[논문 리뷰] Efficient Guided Generation for Large Language Models
이 논문은 안내된 LLM 생성을 유한 상태 기계의 전이로 재구성하여 어휘 인덱스를 구축하고, 각 단계에서 평균 O(1) 마스킹을 가능하게 하며 정규 표현식과 CFG로 확장하고 Outlines에서 구현한다.
In this article we show how the problem of neural text generation can be constructively reformulated in terms of transitions between the states of a finite-state machine. This framework leads to an efficient approach to guiding text generation with regular expressions and context-free grammars by allowing the construction of an index over a language model's vocabulary. The approach is model agnostic, allows one to enforce domain-specific knowledge and constraints, and enables the construction of reliable interfaces by guaranteeing the structure of the generated text. It adds little overhead to the token sequence generation process and significantly outperforms existing solutions. An implementation is provided in the open source Python library Outlines
연구 동기 및 목표
- 대형 언어 모델에서 엄격한 형식 및 도메인 특화 제약을 만족시키기 위한 제약된 텍스트 생성을 동기화한다.
- 생성 가이드를 위해 정규 표현식과 CFG를 다루는 FSM 기반 프레임워크를 개발한다.
- 어휘 인덱스를 만들어 다음 가능한 토큰을 효율적으로 결정한다.
- CFG 기반의 구조화된 출력 지원을 위해 LALR(1) 파서와 함께 CFG로 확장한다.
- 기존 방법에 비해 모델에 무관하고 오버헤드가 낮음을 시연한다.
제안 방법
- 제약을 정규 표현식 및 파서를 대응하는 FSM으로 표현한다.
- LLM 출력 로짓의 마스킹을 사용하여 제약을 강제로 조건부 분포를 형성한다.
- 어휘를 사전 처리하여 FSM 상태를 유효한 다음 토큰(시그마)에 매핑하는 인덱스를 구축하고 각 단계에서 O(1) 마스킹을 가능하게 한다.
- 가이드된 생성을 가능하게 하는 알고리즘들(sample_tokens, masking이 포함된 sample_tokens, find_sub_sequences, map_states_to_vocab)을 제공한다.
- FSM 접근법을 CFG 기반 구문 분석을 위한 PUSH DOWN 자동자까지 확장하고 LALR(1) 파서와의 잠재적 통합을 논의한다.
- Outlines 라이브러리에서 구현을 시연하고 기존 가이드 기반 방법과 비교한다.
![Figure 1 : FSM masking for the regular expression ([0-9]*)?\.?[0-9]* .](https://ar5iv.labs.arxiv.org/html/2307.09702/assets/x1.png)
실험 결과
연구 질문
- RQ1정규 표현식이나 CFG 제약을 강제할 때 가이드된 생성을 어떻게 효율적으로 수행할 수 있는가?
- RQ2어휘에 대한 유한 상태 기계 기반 인덱스가 각 단계에서 유효한 다음 토큰의 상수 시간 결정이 가능하게 하는가?
- RQ3이 FSM 기반 가이드 접근법을 정규식 제약에서 CFG 및 실용 프로그래밍 언어 문법(예: Python, SQL)으로 확장할 수 있는가?
- RQ4실제 LLM 워크플로에서 이러한 인덱스를 구축하고 사용하는 데 있어 실용적 트레이드오프(메모리 대 계산)는 무엇인가?
주요 결과
- 다음 토큰의 유효성 결정에 대해 평균 O(1) 비용을 달성하는 어휘-상태 인덱스를 제시한다.
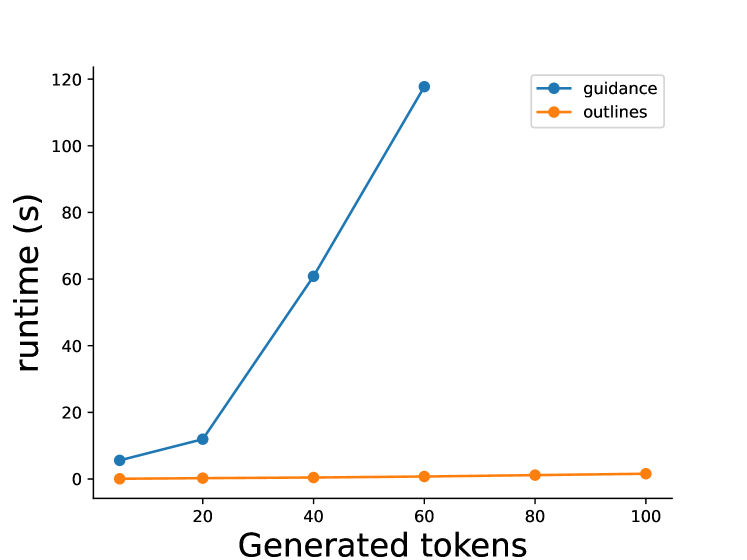
- FSM/CFG 정보 마스크로 LLM 출력 마스킹은 낮은 런타임 오버헤드로 제약 기반 가이드 생성을 가능하게 한다.
- 인덱스 구성은 오프라인으로 수행되며 FSM 상태에서 어휘 부분집합으로의 매핑을 사용하여 빠른 런타임 마스킹을 가능하게 한다.
- 이 방법은 정규식을 넘어 CFG로 확장되며 구조화된 출력을 지원하기 위해 LALR(1) 파서를 통합하기 위한 기초를 다닌다.
- 실증적 비교는 일부 기존 제약 디코딩 방식에 비해 현저한 효율성 향상을 나타내며 Outlines의 오픈 소스 구현이 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.