[논문 리뷰] Efficient Memory Management for Large Language Model Serving with PagedAttention
이 논문은 PagedAttention과 vLLM을 도입하여 KV 캐시 메모리 낭비를 대폭 줄이고 현 시점의 최첨단 시스템 대비 LLM 서빙 처리량을 2–4배 향상시키며, 요청 간 및 디코딩 시나리오 전반에서 더 나은 공유를 제공합니다.
High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the key-value cache (KV cache) memory for each request is huge and grows and shrinks dynamically. When managed inefficiently, this memory can be significantly wasted by fragmentation and redundant duplication, limiting the batch size. To address this problem, we propose PagedAttention, an attention algorithm inspired by the classical virtual memory and paging techniques in operating systems. On top of it, we build vLLM, an LLM serving system that achieves (1) near-zero waste in KV cache memory and (2) flexible sharing of KV cache within and across requests to further reduce memory usage. Our evaluations show that vLLM improves the throughput of popular LLMs by 2-4$ imes$ with the same level of latency compared to the state-of-the-art systems, such as FasterTransformer and Orca. The improvement is more pronounced with longer sequences, larger models, and more complex decoding algorithms. vLLM's source code is publicly available at https://github.com/vllm-project/vllm
연구 동기 및 목표
- 처리량을 제약하는 LLM 서빙의 메모리 할당 문제를 식별한다.
- 낭비를 줄이기 위해 비연속 KV 캐시 저장을 가능하게 하는 새로운 주의(attention) 알고리즘을 제안한다.
- 메모리 관리와 디코딩을 공동 최적화하는 분산 LLM 서빙 엔진을 설계한다.
- 다양한 모델과 디코딩 시나리오에서 FasterTransformer와 Orca에 비해 처리량 개선을 실험으로 보여준다.
제안 방법
- KV 캐시를 고정 크기 블록으로 분할하고 비연속 메모리 저장을 가능하게 하는 PagedAttention를 도입한다.
- OS 가상 메모리에서 영감을 받은 KV 캐시 관리자를 개발하여 논리 KV 블록을 물리적 블록에 매핑하고 필요 시 할당을 가능하게 한다.
- 프롬프트 단계와 자기회귀 생성을 효율적으로 지원하기 위해 PagedAttention와 함께 vLLM을 공동 설계한다.
- 블록 수준 공유 및 쓰기 시 복사(Copy-on-Write)를 적용하여 시퀀스와 빔 간 메모리 공유를 가능하게 한다.
- 가변 입력/출력 길이 및 다양한 디코딩 방법(탐욕적, 샘플링, 빔 검색)을 페이지 메모리 프레임워크 내에서 다루는 방법을 설명한다.
- GPU 작업자를 조정하는 중앙 집중식 스케줄러가 있는 분산 아키텍처를 설명한다.
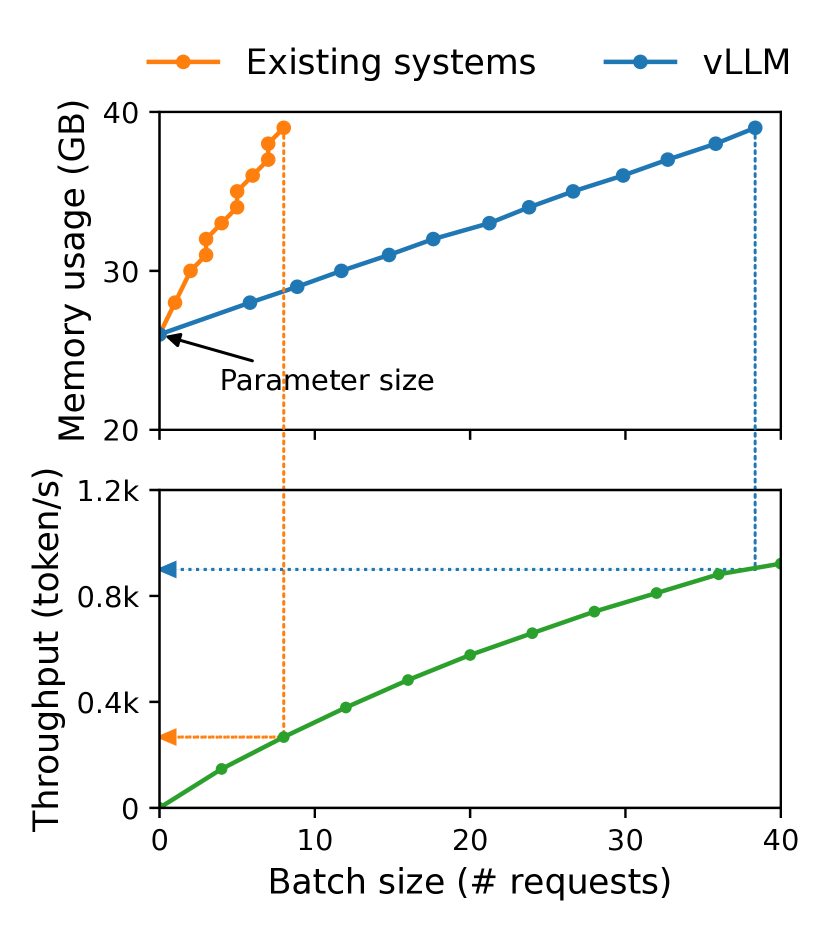
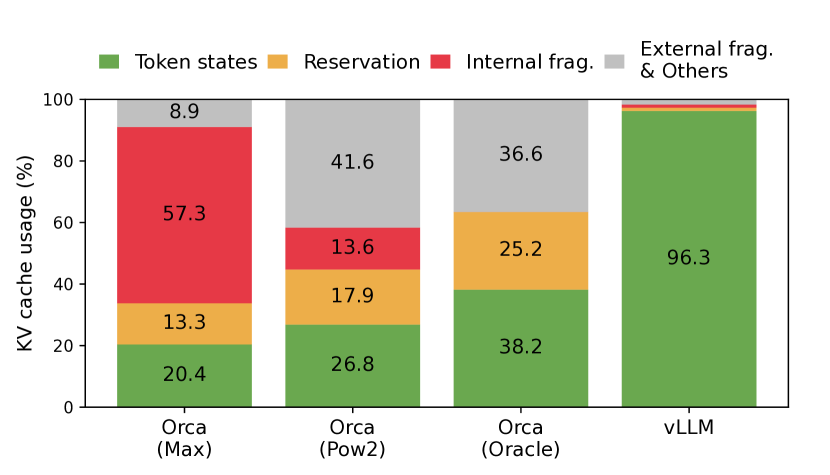
실험 결과
연구 질문
- RQ1비연속 KV 캐시 저장이 LLM 서빙의 메모리 낭비와 배치 처리량에 어떤 영향을 미치는가?
- RQ2페이지형 KV 캐시 관리가 토큰, 프롬프트, 샘플, 빔 간의 효과적인 메모리 공유를 가능하게 하면서 정확도를 보존할 수 있는가?
- RQ3다양한 모델과 디코딩 전략에 걸쳐 vLLM이 FasterTransformer와 Orca에 비해 달성하는 처리량 증가와 메모리 절감은 어느 정도인가?
- RQ4페이지(memory) 모델에서 가변 시퀀스 길이와 복잡한 디코딩(빔 검색, 병렬 샘플링)을 어떻게 처리하는가?
주요 결과
- vLLM은 비슷한 지연 시간으로 최첨단 시스템 대비 LLM 서빙 처리량을 2–4배 향상시킨다.
- PagedAttention은 고정 크기 KV 블록과 비연속 저장을 가능하게 하여 KV 캐시 메모리 낭 waste를 줄인다.
- 블록 수준 관리와 Copy-on-Write에 의해 시퀀스 및 디코딩 후보 간의 메모리 공유가 가능해져 중복 KV 캐시 복사를 줄인다.
- 프롬프트 및 접두사 공유를 지원하여 공통 접두사의 메모리 절감을 크게 가능하게 한다.
- 이 접근 방식은 더 긴 시퀀스, 더 큰 모델, 더 복잡한 디코딩 알고리즘으로 확장되며 정확도는 보존된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.