[논문 리뷰] Efficient Multimodal Learning from Data-centric Perspective
Bunny가 신중하게 압축된 학습 데이터로 작은 다중모달 모델이 더 큰 MLLMs를 능가하여 3B 매개변수에서 최신 성능을 달성한다.
Multimodal Large Language Models (MLLMs) have demonstrated notable capabilities in general visual understanding and reasoning tasks. However, their deployment is hindered by substantial computational costs in both training and inference, limiting accessibility to the broader research and user communities. A straightforward solution is to leverage smaller pre-trained vision and language models, which inevitably cause significant performance drops. In this paper, we demonstrate the possibility of training a smaller but better MLLM with high-quality training data. Specifically, we introduce Bunny, a family of lightweight MLLMs with flexible vision and language backbones for efficient multimodal learning from selected training data. Experiments show that our Bunny-4B/8B outperforms the state-of-the-art large MLLMs on multiple benchmarks. We expect that this work can provide the community with a clean and flexible open-source tool for further research and development. The code, models, and data can be found in https://github.com/BAAI-DCAI/Bunny.
연구 동기 및 목표
- MLLM의 높은 학습/추론 비용으로 인해 저렴하면서도 고성능인 다중모달 모델의 필요성을 설득한다.
- 가볍고 융통성 있는 백본과 데이터 중심 학습 전략을 갖춘 Bunny라는 경량 MLLM 패밀리를 제안한다.
- 데이터세트 응축과 신중한 파인튜닝이 더 큰 모델과의 격차를 줄이거나 능가할 수 있음을 보여준다.
제안 방법
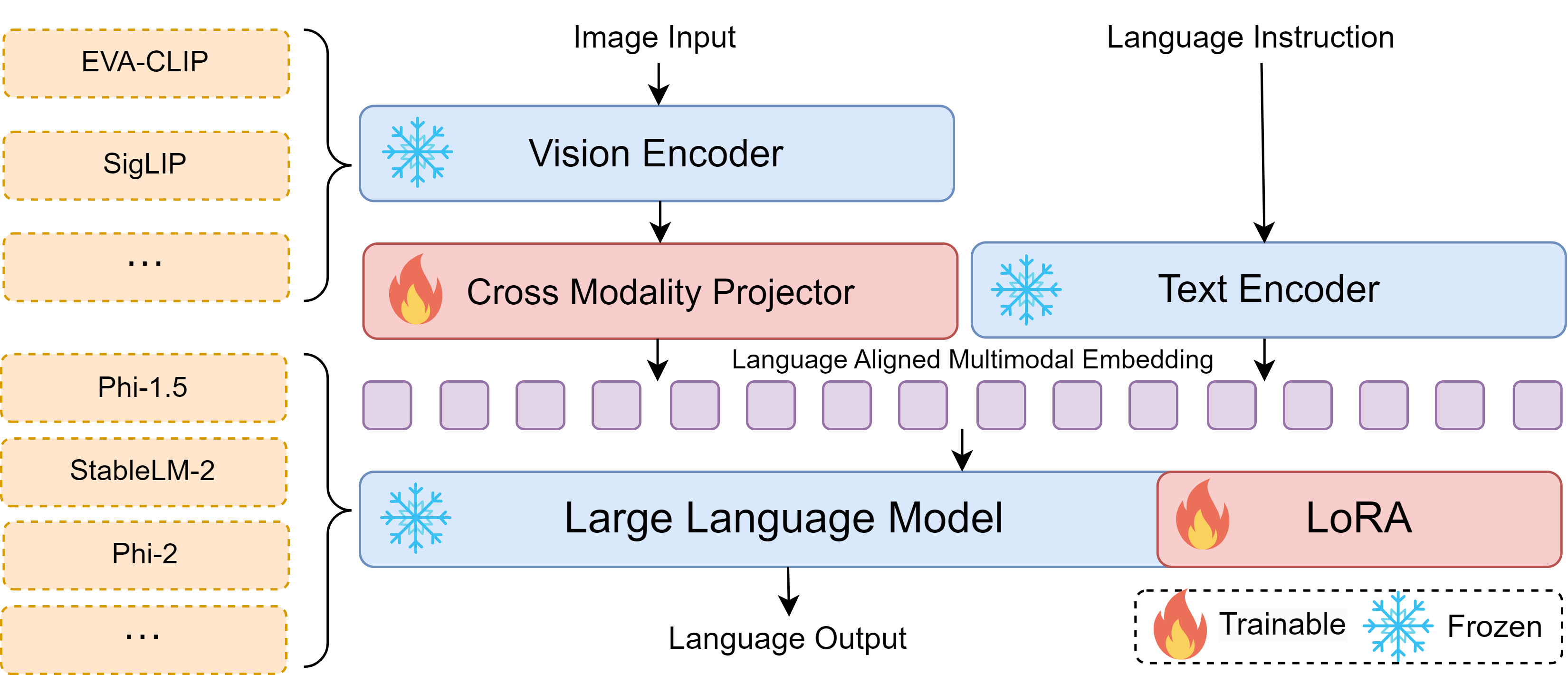
- SigLIP-SO, EVA-CLIP, Phi-2 등과 같은 플러그 앤 플레이 비전 인코더와 LLM 백본을 갖춘 Bunny를 소개한다.
- CLIP 임베딩과 클러스터링 기반 선택을 사용하여 LAION-2B를 2M 코어셋으로 응축해 고품질 사전학습 데이터를 구성한다.
- 인지 구성을 보존하기 위해 다중모달 데이터 세트와 고품질 순수 텍스트 데이터를 결합한 Bunny-695K 파인튜닝 데이터를 생성한다.
- 두 단계 훈련을 사용한다: (1) 교차모달 프로젝터를 통해 비전과 텍스트 임베딩 정렬; (2) LLM과 프로젝터에서 LoRA로 시각 지시문 튜닝.
- 두 단계 모두 다음 토큰 예측에 대한 교차 엔트로피 손실로 훈련하며; 전체 파인튜닝보다 LoRA를 선호한다.
- MME 인지/지각, MMBench, SEED-Bench, MMMU, VQA-v2, GQA, ScienceQA-IMG, POPE 등을 포함한 11개 벤치마크로 평가한다.
실험 결과
연구 질문
- RQ1작고 데이터 최적화된 다중모달 모델이 표준 벤치마크에서 더 큰 MLLMs를 능가할 수 있는가?
- RQ2데이터 응축 및 고품질 파인튜닝 데이터가 모델 크기에 비해 성능에 어떤 영향을 미치는가?
- RQ3Bunny가 최적의 절충을 이룰 수 있는 백본 조합(비전 인코더 + LLM)은 무엇인가?
주요 결과
| 모델 | 비전 인코더 | LLM | MME^P | MME^C | MMB^T | MMB^D | SEED | MMMU^V | MMMU^T | VQA^v2 | GQA | SQA^I | POPE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bunny | SigLIP-SO (0.4B) | Phi-2 (2.7B) | 1488.8 | 289.3 | 69.2 | 68.6 | 62.5 | 38.2 | 33.0 | 79.8 | 62.5 | 70.9 | 86.8 |
- SigLIP-SO와 Phi-2를 결합한 Bunny-3B가 유사 규모의 경량 MLLMs를 능가하고 다수의 벤치마크에서 더 큰 모델들 수준의 성능을 보인다.
- 약 매개변수의 1/4 수준임에도 LLaVA-v1.5-13B와 비교해 여러 작업에서 경쟁력 있거나 우수한 결과를 달성한다.
- 백본 가운데 SigLIP-SO + Phi-2가 벤치마크 전반에서 최상의 성능을 제공한다.
- 데이터 응축과 파인튜닝에서 고품질 순수 텍스트 데이터를 유지하는 것이 인지 및 다중모달 능력을 향상시킨다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.