[논문 리뷰] EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
EfficientViT는 샌드위치 레이아웃과 Cascaded Group Attention을 통해 메모리 접근 및 계산을 줄여 이전의 효율적 모델들보다 더 빠른 속도와 더 높은 정확도를 제공하는 메모리 효율적 비전 트랜스포머를 도입합니다.
Vision transformers have shown great success due to their high model capabilities. However, their remarkable performance is accompanied by heavy computation costs, which makes them unsuitable for real-time applications. In this paper, we propose a family of high-speed vision transformers named EfficientViT. We find that the speed of existing transformer models is commonly bounded by memory inefficient operations, especially the tensor reshaping and element-wise functions in MHSA. Therefore, we design a new building block with a sandwich layout, i.e., using a single memory-bound MHSA between efficient FFN layers, which improves memory efficiency while enhancing channel communication. Moreover, we discover that the attention maps share high similarities across heads, leading to computational redundancy. To address this, we present a cascaded group attention module feeding attention heads with different splits of the full feature, which not only saves computation cost but also improves attention diversity. Comprehensive experiments demonstrate EfficientViT outperforms existing efficient models, striking a good trade-off between speed and accuracy. For instance, our EfficientViT-M5 surpasses MobileNetV3-Large by 1.9% in accuracy, while getting 40.4% and 45.2% higher throughput on Nvidia V100 GPU and Intel Xeon CPU, respectively. Compared to the recent efficient model MobileViT-XXS, EfficientViT-M2 achieves 1.8% superior accuracy, while running 5.8x/3.7x faster on the GPU/CPU, and 7.4x faster when converted to ONNX format. Code and models are available at https://github.com/microsoft/Cream/tree/main/EfficientViT.
연구 동기 및 목표
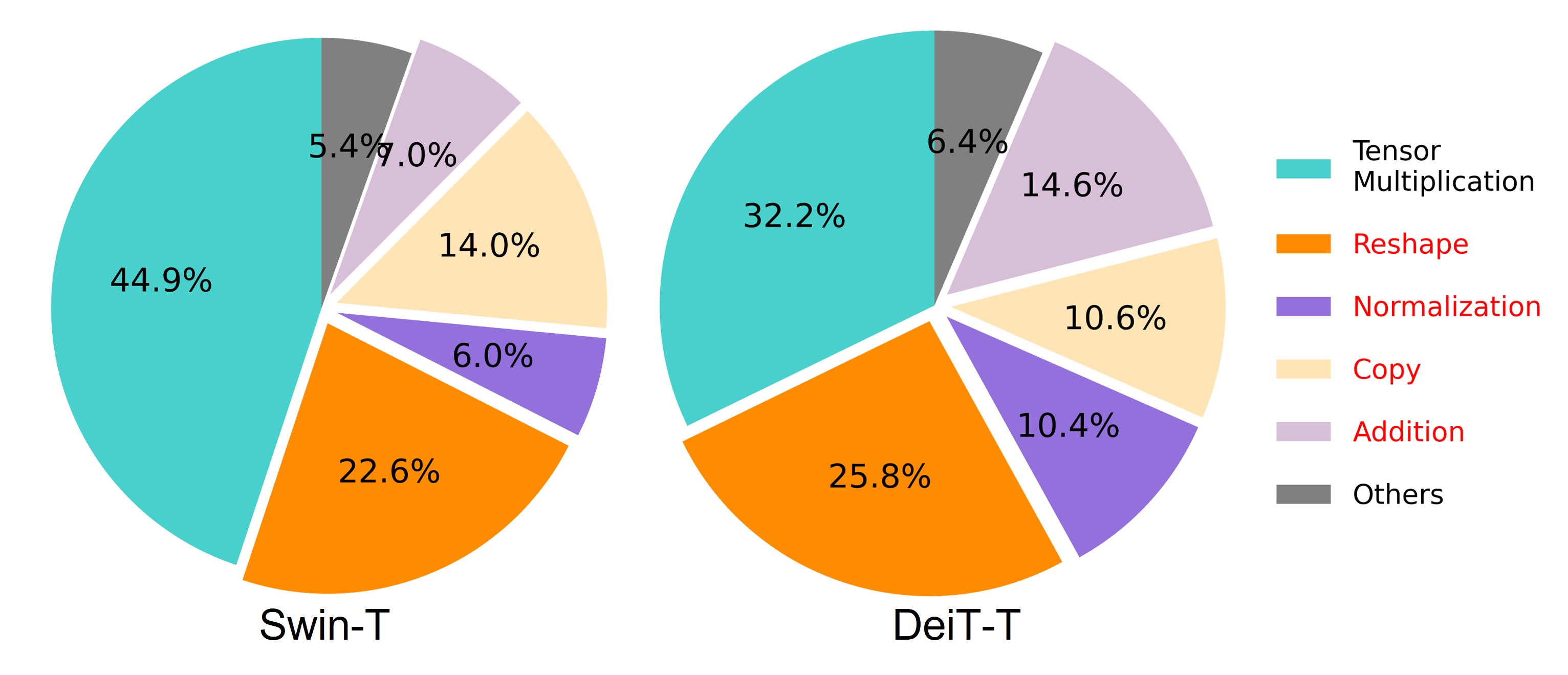
- Vision Transformer(ViT) 추론 속도에 영향을 주는 요인을 분석하고, 메모리 접근성, 계산 중복성 및 파라미터 사용에 초점을 맞춥니다.
- 정확도를 희생하지 않으면서 Throughput을 개선하기 위한 메모리 효율적 ViT 빌딩 블록을 설계합니다.
- 헤드의 중복 출현을 줄이고 특징 다양성을 높이기 위한 새로운 주의(attention) 메커니즘을 개발합니다.
- 더 중요한 모듈의 효율성을 개선하고 덜 중요한 구성 요소를 가지치기(pruning)하는 방식으로 파라미터를 재할당합니다.
- EfficientViT를 다운스트림 비전 태스크로의 이전 가능성을 시연합니다.
제안 방법
- 단일 메모리 바운드 MHSA가 FFN 레이어 사이에 샌드위치로 배치되어 메모리 바운드 작업을 감소시키는 샌드위치 레이아웃 블록을 도입합니다.
- Cascaded Group Attention(CGA)을 제안하여 주의 헤드에 서로 다른 피처 분할을 공급하고 헤드 간 출력을 계단식으로 연결하여 다양성을 높이고 계산을 줄입니다.
- Taylor 구조 프 pruning을 적용하여 중요한 채널을 식별하고 파라미터 재배치를 안내하며, 중요 모듈의 폭을 확장하고 덜 중요한 부분을 축소합니다.
- 이중 중첩 패치 임베딩(overlapping patch embedding)과 BN이 전반에 걸쳐 적용된 3단계 계층 구조를 사용하여 하드웨어에서의 속도와 실용성을 향상시킵니다.
- GPU/CPU/ONNX에서 ImageNet-1K의 처리량과 정확도를 평가하고 다운스트림 태스크로의 이전 가능성을 테스트합니다.
![Figure 1 : Speed and accuracy comparisons between EfficientViT (Ours) and other efficient CNN and ViT models tested on an Nvidia V100 GPU with ImageNet-1K dataset [ 17 ] .](https://ar5iv.labs.arxiv.org/html/2305.07027/assets/figures/modelACC_gpu.png)
실험 결과
연구 질문
- RQ1추론 중 메모리 바운드 작업을 최소화하도록 ViT를 어떻게 재설계할 수 있는가?
- RQ2피처 채널을 분할하여 주의 헤드를 공급하는(CGA) 방식이 정확도를 희생하지 않으면서 중복성을 줄이고 주의 다양성을 높일 수 있는가?
- RQ3경량화된 ViT에서 더 나은 속도-정확도 트레이드를 제공하는 파라미터 재할당 전략은 무엇인가?
- RQ4제안된 EfficientViT 블록들이 다운스트림 비전 태스크와 실제 하드웨어 배포에 일반화되는가?
주요 결과
- EfficientViT-M5는 Nvidia V100에서 10,621 images/s 처리량으로 Top-1 정확도 77.1%를 달성하며 MobileNetV3-Large보다 정확도에서 1.9% 높고 처리량은 GPU에서 40.4% / CPU에서 45.2%의 향상을 보입니다.
- EfficientViT-M2는 Top-1 정확도 70.8%에 도달하여 MobileViT-XXS를 1.8% 상회하고 GPU에서 5.8배, CPU에서 3.7배의 속도 향상을 제공하며 ONNX 성능은 7.4배 더 빠릅니다.
- EfficientViT-M4는 ImageNet에서 더 높은 처리량과 경쟁력 있는 정확도로 여러 효율 모델을 능가합니다(예: EdgeViT-XXS 대비 GPU 4.4배, CPU 3.0배 빠름).
- 메모리 바운드 MHSA를 샌드위치 레이아웃으로 교체하면 메모리 시간 소모를 줄이면서 FFN 기반 채널 간의 통신을 증가시킵니다.
- CGA는 피처 분할에 걸쳐 헤드를 분배하고 출력을 계단식으로 연결하여 주의 계산을 줄이고 효율성과 정확도를 향상시킵니다(비교 실험에서 MHSA 대비 이득이 확인됨).
- 파라미터 재할당으로 V-채널 폭을 늘리고 Q/K 차원을 줄이며 FFN 확장을 축소하면 측정 가능한 정확도와 처리량 이득이 얻어집니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.