[논문 리뷰] Embedded Graph Convolutional Networks for Real-Time Event Data Processing on SoC FPGAs
이 논문은 SoC FPGA에서 실시간 이벤트 데이터 처리를 위한 PointNet++-유사 그래프 컨볼루션 네트워크의 하드웨어 인식을 반영한 최적화를 제시하여, 상당한 모델 크기 감소와 약간의 정확도 손실, 4.47 ms 지연에서 13.3 MEPS 처리량을 달성한다.
The utilisation of event cameras represents an important and swiftly evolving trend aimed at addressing the constraints of traditional video systems. Particularly within the automotive domain, these cameras find significant relevance for their integration into embedded real-time systems due to lower latency and energy consumption. One effective approach to ensure the necessary throughput and latency for event processing is through the utilisation of graph convolutional networks (GCNs). In this study, we introduce a custom EFGCN (Event-based FPGA-accelerated Graph Convolutional Network) designed with a series of hardware-aware optimisations tailored for PointNetConv, a graph convolution designed for point cloud processing. The proposed techniques result in up to 100-fold reduction in model size compared to Asynchronous Event-based GNN (AEGNN), one of the most recent works in the field, with a relatively small decrease in accuracy (2.9% for the N-Caltech101 classification task, 2.2% for the N-Cars classification task), thus following the TinyML trend. We implemented EFGCN on a ZCU104 SoC FPGA platform without any external memory resources, achieving a throughput of 13.3 million events per second (MEPS) and real-time partially asynchronous processing with low latency. Our approach achieves state-of-the-art performance across multiple event-based classification benchmarks while remaining highly scalable, customisable and resource-efficient. We publish both software and hardware source code in an open repository: https://github.com/vision-agh/gcnn-dvs-fpga
연구 동기 및 목표
- 임베디드 FPGA 플랫폼에서 비동기 이벤트 카메라 데이터의 에너지 효율적 실시간 처리를 가능하게 하도록 동기를 부여하고 지원한다.
- 희소하고 동적인 이벤트 그래프에 맞춰 PointNet++-스타일 GCN을 적응·최적화한다.
- 고정 지연과 알려진 처리량을 가진 ZCU104 SoC FPGA에서 엔드-투-엔드 하드웨어-소프트웨어 공동 설계를 시연한다.
- 다수의 이벤트 기반 데이터셋에서 모델 크기를 100배 이상 축소하면서도 허용 가능한 정확도 하락을 보인다.
제안 방법
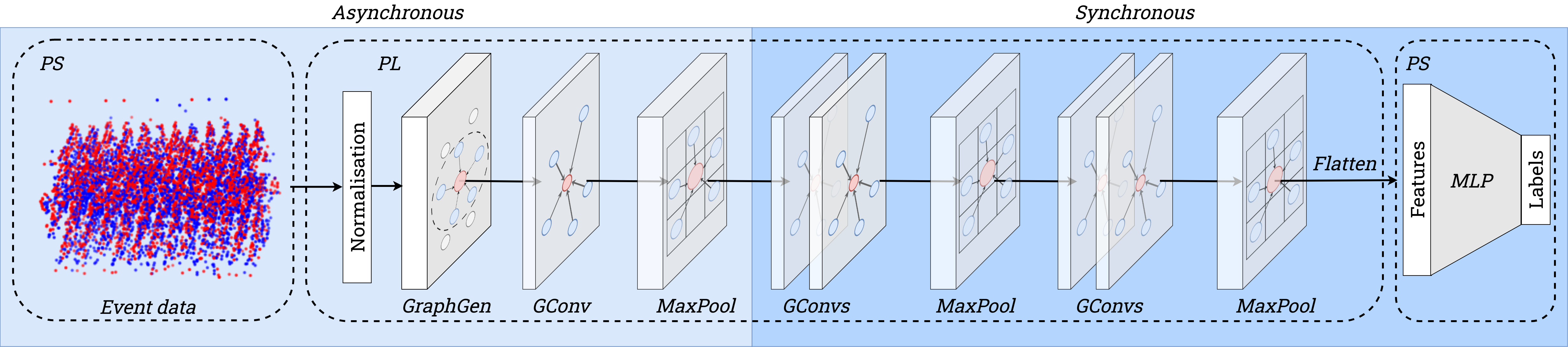
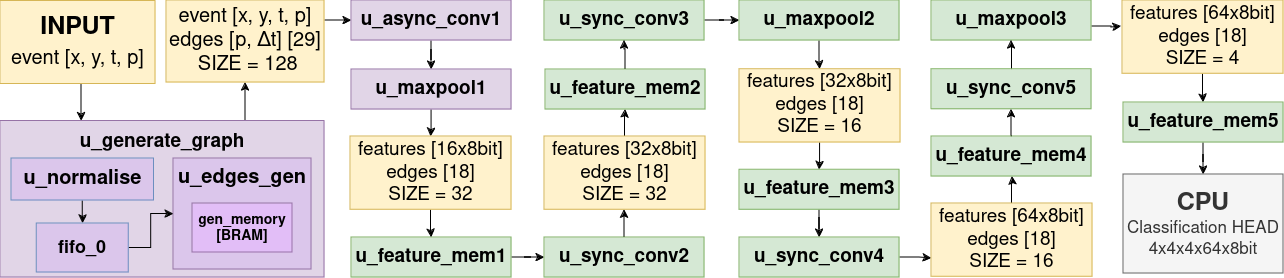
- 방사선 반경 기반 엣지를 사용하여 비동기 이벤트 스트림으로부터 희소 그래프를 구축하는 하드웨어 의식 그래프 생성기를 개발한다.
- 그래프 위에서 최대 풀링이 있는 PointNet++-유사 그래프 컨볼루션과 모델 축소를 위한 세 개의 MaxPool 계층을 채택한다.
- FPGA 제약에 맞춘 8비트 가중치와 32비트 바이어스의 양자화 인식 학습(Quantisation aware training)을 수행한다.
- 엣지 생성을 위한 이웃 탐색은 반경 R 내에서 수행하고 고정소수점 구현을 사용한다.
- 네 가지 이벤트 기반 데이터셋(N-Cars, N-Caltech101, CIFAR10-DVS, MNIST-DVS)에서 평가하고 관련 GNN 기반 이벤트 처리 방법과 비교한다.
실험 결과
연구 질문
- RQ1FPGA에서 이벤트 스트림용 하드웨어 의식 GCN 설계가 낮은 지연으로 실시간 처리량을 달성할 수 있는가?
- RQ2표준 이벤트 기반 분류 벤치마크에서 공격적 모델 축소가 정확도에 미치는 영향은?
- RQ3임베디드 하드웨어에서 그래프 구성에 대한 서로 다른 반경 설정(R=3 대 R=5)의 트레이드오프는 무엇인가?
- RQ4이벤트 데이터에서 파생된 동적, 비동기 업데이트 그래프를 엔드-투-엔드 FPGA 가속으로 실현 가능성은?
주요 결과
| 모델 | 표현 | N-Cars | N-Caltech101 | CIFAR10-DVS | MNIST-DVS | 크기 [MB] | 파라미터 [M] |
|---|---|---|---|---|---|---|---|
| EV-VGCNN | Voxel | 0.953 | 0.748 | 0.670 | - | 3.20 | 0.84 |
| VMV-GCN | Voxel | 0.932 | 0.778 | 0.690 | - | 3.28 | 0.86 |
| VMST-Net | Voxel | 0.944 | 0.822 | 0.753 | - | 3.61 | 0.95 |
| G-CNNs | Graph | 0.902 | 0.630 | 0.515 | 0.974 | 18.81 | 4.93 |
| RG-CNNs | Graph | 0.914 | 0.657 | 0.540 | 0.986 | 19.46 | 5.10 |
| NvS-S | Graph | 0.915 | 0.670 | 0.602 | 0.986 | - | - |
| EvS-S | Graph | 0.931 | 0.761 | 0.680 | 0.991 | - | - |
| AEGNN | Graph | 0.945 | 0.668 | - | - | 83.31 | 21.84 |
| OAEGNN_R=3 | Graph | 0.903 | 0.601 | 0.502 | 0.911 | 0.82 | 0.86 |
| OAEGNN_R=5 | Graph | 0.928 | 0.645 | 0.541 | 0.942 | 0.82 | 0.86 |
| EFGCN_R=3 | Graph | 0.853 | 0.576 | 0.478 | 0.892 | 0.40 | 0.42 |
| EFGCN_R=5 | Graph | 0.896 | 0.619 | 0.498 | 0.904 | 0.40 | 0.42 |
- ZCU104 FPGA 플랫폼에서 처리량이 최대 13.3 MEPS, 지연 4.47 ms.
- 제안된 EFGCN 계열은 AEGNN 대비 모델 크기를 100배 이상 축소하고 메모리 효율성을 크게 향상.
- OAEGNN은 데이터셋 전반에서 더 작은 모델로도 경쟁력 있는 정확도를 보인다.
- 양자화 인식 학습으로 8비트 가중치와 32비트 바이어스가 최소한의 정확도 손실과 함께 얻어진다.
- 반경 기반 엣지와 NM 기반 이웃 탐색으로 비동기적 실시간 그래프 업데이트가 가능.
- 본 접근법은 SoC FPGA에서 GCN용 엔드-투-엔드 하드웨어 가속기 최초의 실시간 이벤트 데이터용으로 포지셔닝된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.