[논문 리뷰] Empirical Analysis of the Strengths and Weaknesses of PEFT Techniques for LLMs
이 논문은 데이터 규모와 작업에 걸쳐 FLAN-T5-XL에 대해 PEFT 방법들(LoRA, IA3, BitFit, Prompt Tune)을 벤치마킹하고 방법 선택 프레임워크를 제안하며, 데이터가 작거나 중간일 때 전체 튜닝이 더 빨리 수렴하는 반면 PEFT는 더 큰 데이터에서 뛰어나고 매개변수 효율적으로 성능을 달성할 수 있음을 발견했다.
As foundation models continue to exponentially scale in size, efficient methods of adaptation become increasingly critical. Parameter-efficient fine-tuning (PEFT), a recent class of techniques that require only modifying a small percentage of the model parameters, is currently the most popular method for adapting large language models (LLMs). Several PEFT techniques have recently been proposed with varying tradeoffs. We provide a comprehensive and uniform benchmark of various PEFT techniques across a representative LLM, the FLAN-T5 model, and evaluate model performance across different data scales of classification and generation datasets. Based on this, we provide a framework for choosing the optimal fine-tuning techniques given the task type and data availability. Contrary to popular belief, we also empirically prove that PEFT techniques converge slower than full tuning in low data scenarios, and posit the amount of data required for PEFT methods to both perform well and converge efficiently. Lastly, we further optimize these PEFT techniques by selectively choosing which parts of the model to train, and find that these techniques can be applied with significantly fewer parameters while maintaining and even improving performance.
연구 동기 및 목표
- 대표적인 LLM(FLAN-T5)에서 데이터 규모 및 작업 유형(분류 및 생성)에 걸쳐 일관되고 포괄적인 PEFT 벤치마크를 제공한다.
- PEFT 대 전체 미세조정의 수렴 속도, 정확도 및 기타 지표를 분석하여 PEFT를 언제 사용할지 파악한다.
- 다양한 PEFT 방법에 대해 학습하는 모델의 어떤 부분(계층/하위 모듈)이 가장 큰 영향을 미치는지 식별한다.
- 작업 유형과 데이터 가용성에 따라 PEFT 방법을 선택하기 위한 실용적 프레임워크를 제시한다.
- 성능을 유지하거나 개선하면서 학습 매개변수를 줄일 수 있는 잠재적 제거(ablation) 가능성을 시연한다.
제안 방법
- 네 가지 PEFT 기법(LoRA, (IA)3, 프롬프트 튜닝, BitFit)을 FLAN-T5-XL에서 다중 데이터 세트 및 데이터 규모에 걸쳐 전체 미세조정과 비교하여 평가한다.
- AG News와 CoLA의 정확도는 정확한 문자열 일치(exact string-match accuracy)를, E2E NLG와 SAMSum의 평가는 ROUGE-L을 사용한다.
- 학습되는 계층/하위 모듈과 수정되는 구성 요소(예: 주의 메커니즘 vs Dense 블록)를 다양화하는 제거 연구(ablation)를 수행한다.
- 수렴 속도, 메모리 사용량 및 계산 비용을 분석하여 효율-정확도 트레이드오프를 도출한다.
- 매개변수 수치와 시간당 성능과 같은 기준으로 비교하여 매개변수당 효율을 정규화한 결과를 제공한다.
- 리소스 제약 및 데이터 가용성에 따라 어느 경우 전체 튜닝 또는 PEFT가 바람직한지에 대한 경험적 가이드라인을 제시한다.
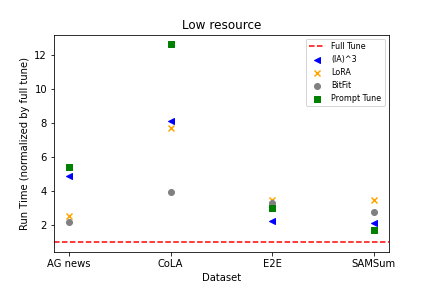
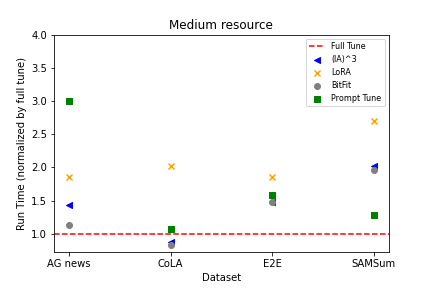
실험 결과
연구 질문
- RQ1FLAN-T5-XL에서 낮은/중간/높은 데이터 규모에서 분류 및 생성 작업에 대해 서로 다른 PEFT 기법의 성능은 어떻게 나타나는가?
- RQ2데이터 레짐에 걸친 PEFT와 전체 미세조정의 수렴 특성 및 자원 비용은 어떻게 다른가?
- RQ3학습에 적용할 때 어떤 모델 구성 요소(계층, 주의 블록, 활성화)가 가장 중요한가?
- RQ4특정 계층이나 하위 모듈의 선택적 학습으로 PEFT 접근법을 더 최적화하면 성능에 해를 끼치지 않는가?
- RQ5주어진 작업과 데이터 레짐에 대해 적절한 PEFT 기법을 선택하는 프레임워크를 실무자에게 어떻게 제시할 수 있는가?
주요 결과
- PEFT 기법은 일반적으로 낮은/중간 자원 데이터에서 수렴 속도 면에서 전체 튜닝보다 뒤처지지만, 더 큰 데이터 볼륨에서는 성능이 이를 따라잡거나 능가할 수 있다.
- BitFit와 LoRA는 낮은/중간 자원 시나리오에서 좋은 성능을 보이는 경향이 있는 반면, 더 많은 데이터가 주어지면 전체 튜닝의 상대적 성능 이점이 커진다.
- $(IA)^{3}$은 요소별 스케일링을 통해 메모리 효율성을 제공하며 제거 연구에서 최소한의 성능 손실로 매개변수 수를 크게 줄일 수 있다.
- 주의 수준의 수정과 이후 계층의 선택이 다운스트림 성능에 특히 중요한데, $(IA)^{3}$에서는 후반부 계층 또는 임의의 계층 선택이 초기 계층 선택보다 종종 더 우수한 성능을 낸다.
- 성능을 해치지 않으면서 매개변수를 상당히 줄일 수 있어, 보다 효율적인 적응을 가능하게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.