[논문 리뷰] Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
본 논문은 대형 언어 모델과 함께 적은 샷(Text-to-SQL) 성능을 향상시키기 위한 맥락 학습의 프롬프트 설계 전략을 조사하고, 문법 기반 시연 선택, 스키마 보강, 투표를 제안하여 Spider에서 실행 정확도를 높이는 방법을 제시한다. 최적의 프롬프트는 최신 연구를 2.5포인트 차로 앞서고, 최상의 미세 조정 시스템을 5.1포인트 차로 능가한다.
In-context learning (ICL) has emerged as a new approach to various natural language processing tasks, utilizing large language models (LLMs) to make predictions based on context that has been supplemented with a few examples or task-specific instructions. In this paper, we aim to extend this method to question answering tasks that utilize structured knowledge sources, and improve Text-to-SQL systems by exploring various prompt design strategies for employing LLMs. We conduct a systematic investigation into different demonstration selection methods and optimal instruction formats for prompting LLMs in the Text-to-SQL task. Our approach involves leveraging the syntactic structure of an example's SQL query to retrieve demonstrations, and we demonstrate that pursuing both diversity and similarity in demonstration selection leads to enhanced performance. Furthermore, we show that LLMs benefit from database-related knowledge augmentations. Our most effective strategy outperforms the state-of-the-art system by 2.5 points (Execution Accuracy) and the best fine-tuned system by 5.1 points on the Spider dataset. These results highlight the effectiveness of our approach in adapting LLMs to the Text-to-SQL task, and we present an analysis of the factors contributing to the success of our strategy.
연구 동기 및 목표
- 대형 언어 모델을 사용한 맥락 학습으로 Text-to-SQL 성능을 향상시키는 것.
- 유사성과 다양성의 균형을 맞춘 시연 선택 기준을 조사한다.
- 데이터베이스 스키마 표현 및 지식 보강으로 프롬프트를 강화한다.
- Text-to-SQL에서 성공적인 프롬프트 설계에 기여하는 요인을 분석한다.
제안 방법
- 질문 유사도만이 아닌 SQL 구문 구조를 사용하여 시연을 선택한다.
- 프롬프트 구성을 위해 데이터베이스를 일반 텍스트가 아닌 코드(CREATE 쿼리)로 표현한다.
- SQL 구문 벡터의 이산 표현에 대해 k-평균 클러스터링으로 다양성을 적용하여 시연을 선택한다.
- 의미적 및 구조적 스키마 정보(온톨로지, 열 정의, ER 요약)를 활용해 프롬프트를 보강한다.
- 다양한 샷 설정의 예측에 대한 투표를 통해 여러 프롬프트를 결합하여 실행 오류를 줄인다.
- Codex (code-davinci-002) 및 gpt-3.5-turbo로 Spider 및 관련 데이터셋에서 프롬프트를 평가하고 실행 정확도를 보고한다.
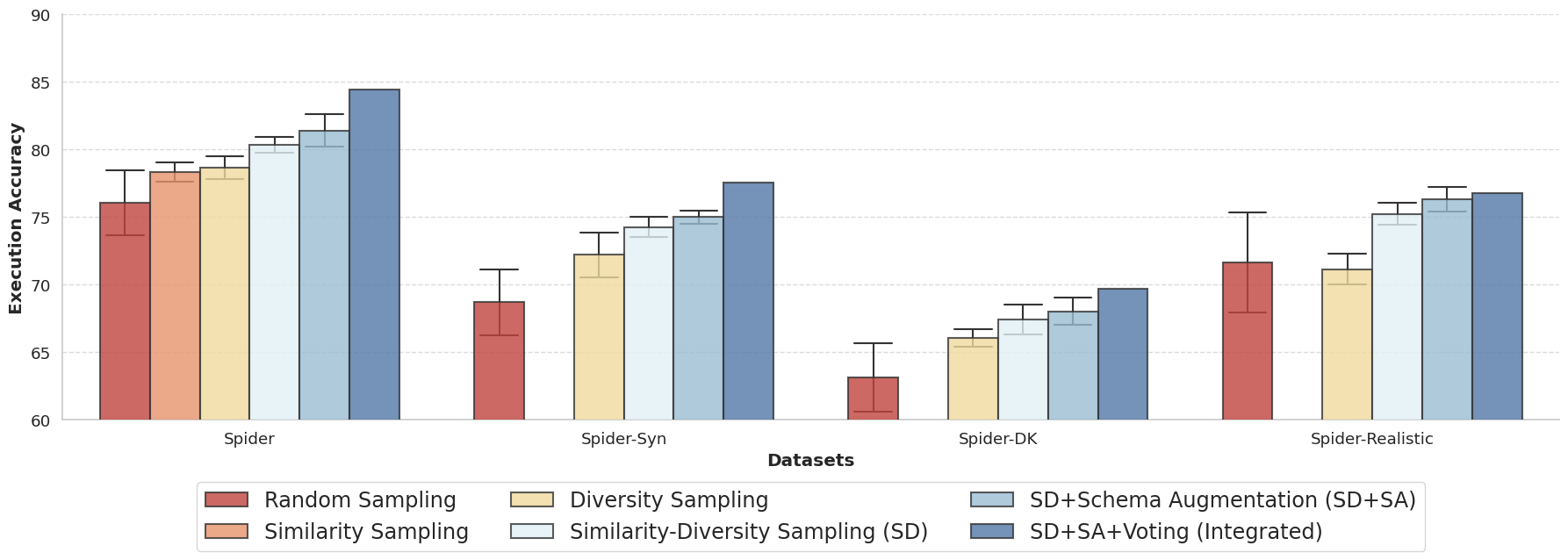
실험 결과
연구 질문
- RQ1SQL 구문 기반 시연 선택이 적은 샷 Text-to-SQL 성능에 어떤 영향을 미치는가?
- RQ2시연에서 유사성과 다양성의 균형이 Text-to-SQL 데이터셋 전반의 실행 정확도를 향상시키는가?
- RQ3제로샷 및 소수 샷 설정에서 스키마 관련 지식 보강이 프롬프트 효과에 미치는 영향은 무엇인가?
- RQ4다양한 프롬프트 구성에서 통합 투표 전략이 강건성을 향상시키는가?
주요 결과
| 커버리지 | 유사도 | 점수 |
|---|---|---|
| Random | 0.38 | 76.03 |
| Similarity | 0.35 | 78.33 |
| Diversity | 0.43 | 78.64 |
| _similarity-Diversity | 0.50 | 80.32 |
- 유사성-다양성 시연 전략이 무작위, 유사도만, 또는 다양성만 접근 방식보다 실행 정확도가 더 높다.
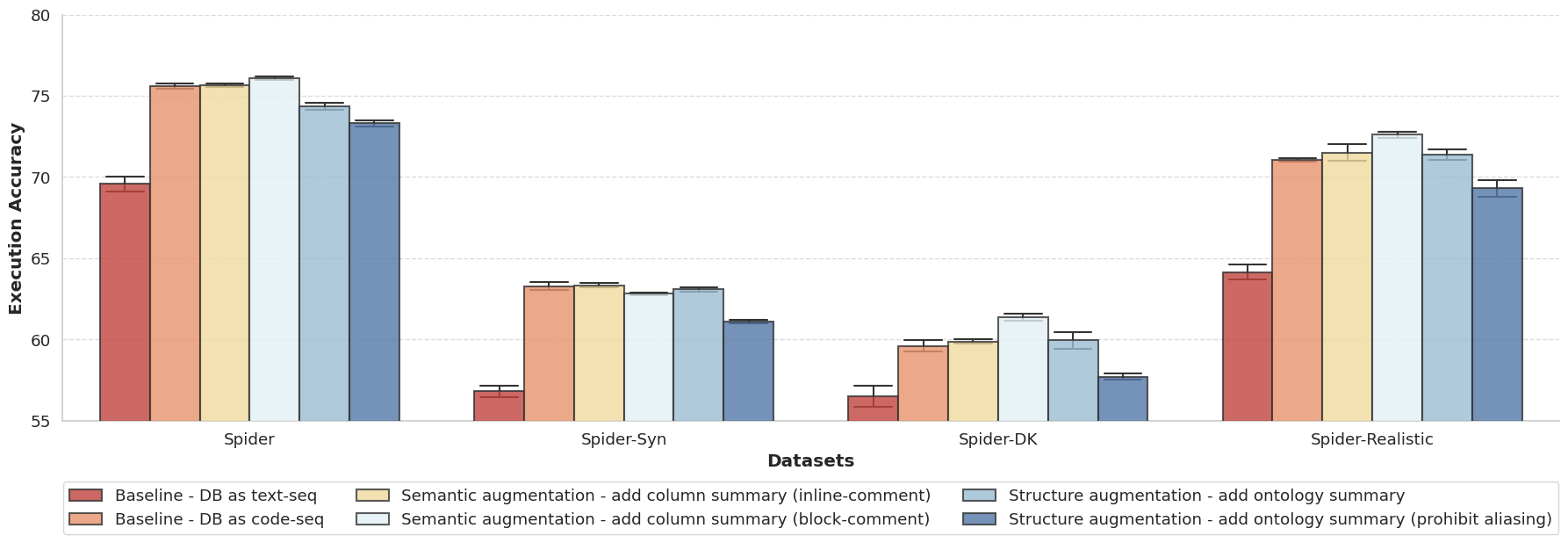
- 스키마 보강은 성능을 향상시키며, 의미적 보강(열 설명)이 제로샷 설정과 일부 소수 샷 사례에서 이점을 보인다.
- 데이터베이스를 표현하는데 SQL CREATE 쿼리(code-seq)를 사용하는 것이 텍스트-시퀀스(text-seq) 표현보다 프롬프트 구성에서 우수하다.
- 여러 샷 구성에 걸친 통합 투표 접근 방식은 일관되게 결과를 개선하고 실행 오류를 줄인다.
- Spider에서 제안된 방법은 Execution Accuracy 84.4를 달성하여 최신 연구보다 2.5포인트, 가장 우수한 미세 조정 시스템보다 5.1포인트를 상회한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.