[논문 리뷰] Executable Code Actions Elicit Better LLM Agents
CodeAct는 LLM 에이전트가 실행 가능한 Python 코드를 행동으로 방출하도록 하여 Python 인터프리터와 통합되며, 코드 실행, 수정, 도구 호출 구성에 활용되어 텍스트/JSON 액션 형식보다 성능이 향상되고, Llama2 및 Mistral로 미세 조정된 CodeActAgent와 CodeActInstruct를 가능하게 합니다.
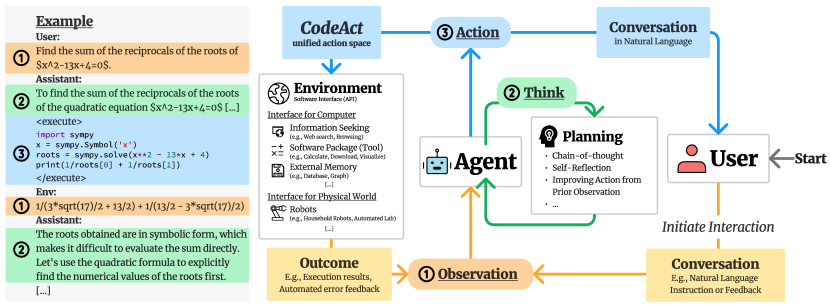
Large Language Model (LLM) agents, capable of performing a broad range of actions, such as invoking tools and controlling robots, show great potential in tackling real-world challenges. LLM agents are typically prompted to produce actions by generating JSON or text in a pre-defined format, which is usually limited by constrained action space (e.g., the scope of pre-defined tools) and restricted flexibility (e.g., inability to compose multiple tools). This work proposes to use executable Python code to consolidate LLM agents' actions into a unified action space (CodeAct). Integrated with a Python interpreter, CodeAct can execute code actions and dynamically revise prior actions or emit new actions upon new observations through multi-turn interactions. Our extensive analysis of 17 LLMs on API-Bank and a newly curated benchmark shows that CodeAct outperforms widely used alternatives (up to 20% higher success rate). The encouraging performance of CodeAct motivates us to build an open-source LLM agent that interacts with environments by executing interpretable code and collaborates with users using natural language. To this end, we collect an instruction-tuning dataset CodeActInstruct that consists of 7k multi-turn interactions using CodeAct. We show that it can be used with existing data to improve models in agent-oriented tasks without compromising their general capability. CodeActAgent, finetuned from Llama2 and Mistral, is integrated with Python interpreter and uniquely tailored to perform sophisticated tasks (e.g., model training) using existing libraries and autonomously self-debug.
연구 동기 및 목표
- 텍스트/JSON를 넘어 LLM 에이전트의 액션 공간을 확장하여 실세계 작업을 처리하도록 동기를 부여합니다.
- 실행 가능한 Python 코드(CodeAct)로 통합된 Python 인터프리터를 사용하는 통합 액션 공간을 제안합니다.
- CodeAct의 제어 및 데이터 흐름, 재사용성, 자동 오류 유도 자기 디버깅의 이점을 입증합니다.
- 17개 모델에 걸친 다중-LLM 평가에서 혜원을 보여주고 CodeActInstruct를 소개하여 지시 조정합니다.
제안 방법
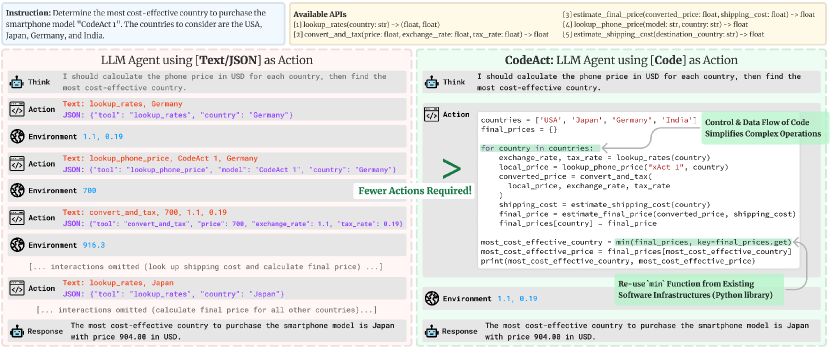
- CodeAct를 임베디드 Python 인터프리터에 의해 실행되는 Python 코드 액션을 방출하는 것으로 정의합니다.
- 기계적 도구 사용의 원자 작업 및 다중 도구 작업에서 CodeAct를 텍스트/JSON 액션과 API-Bank 및 새로운 M3 ToolEval 벤치마크를 사용하여 비교합니다.
- 도구 구성 성능을 평가하기 위해 82개의 다중 턴, 다중 도구 작업으로 M3 ToolEval을 큐레이션합니다.
- CodeActInstruct를 포함하는 7k개의 다중 턴 궤적을 만들어 CodeActAgent를 학습시키고 상호 작용에서의 자기 개선을 연구합니다.
- CodeActAgent를 CodeActInstruct에 대해 미세 조정하고 일반 대화를 추가로 학습시켜 에이전트 작업 및 일반 벤치마크에서의 성과를 평가합니다.
실험 결과
연구 질문
- RQ1RQ1: 코드 데이터에 대한 LLM의 친숙도가 텍스트/JSON보다 원자 도구 사용에서 CodeAct에 이점을 주는가?
- RQ2RQ2: 파이썬의 제어 및 데이터 흐름이 복잡하고 다중 도구 작업에서 성능을 향상시키는가?
- RQ3RQ3: 다중 턴 상호 작용과 기존 소프트웨어가 CodeAct의 견고성과 능력에 어떤 영향을 미치는가?
- RQ4RQ4: 자기 디버깅을 수행하는 개방형 소스 LLM 에이전트를 훈련하는 데 CodeAct를 사용할 수 있는가?
주요 결과
- CodeAct는 텍스트/JSON보다 원자 도구 호출의 정합성이 동등하거나 더 우수하며, 개방 소스 모델의 경우 더 큰 이점을 보입니다.
- CodeAct는 여러 도구가 필요한 복잡한 작업에서 M3 ToolEval 벤치마크에서 최대 20% 절대 개선을 달성하고, 필요한 액션 수를 최대 30%까지 줄입니다.
- CodeActInstruct(7k 궤적)는 에이전트 성능을 향상시키고, CodeActInstruct를 일반 대화와 혼합해도 광범위한 기능을 보존합니다.
- CodeActAgent(CodeActInstruct로 미세 조정)은 도메인 내외의 에이전트 작업에서 오픈 소스 LLM보다 우수하며 MINT 및 M3 ToolEval에서 일반화 가능하며 텍스트-액션 형식으로도 일반화할 수 있습니다.
- CodeActAgent는 파이썬 오류 메시지, 라이브러리 임포트 및 Pandas, Scikit-Learn, Matplotlib 등의 외부 도구를 활용하여 자율적으로 자기 디버깅할 수 있습니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.