[논문 리뷰] Explainable Automated Debugging via Large Language Model-driven Scientific Debugging
AutoSD는 LLM을 사용하여 디버거 인터페이스로 Scientific Debugging을 모방하고, 자동 디버깅을 위한 가설과 설명을 생성하며, 경쟁력 있는 수정 성능을 유지합니다. 인간 연구는 설명이 개발자 의사 결정에 도움이 됨을 시사합니다.
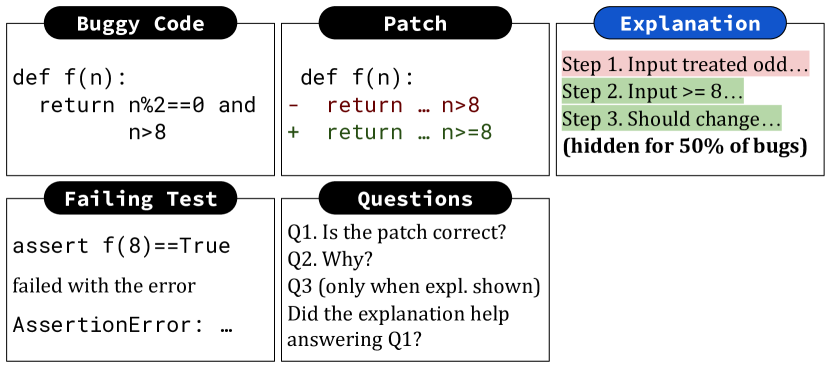
Automated debugging techniques have the potential to reduce developer effort in debugging, and have matured enough to be adopted by industry. However, one critical issue with existing techniques is that, while developers want rationales for the provided automatic debugging results, existing techniques are ill-suited to provide them, as their deduction process differs significantly from that of human developers. Inspired by the way developers interact with code when debugging, we propose Automated Scientific Debugging (AutoSD), a technique that given buggy code and a bug-revealing test, prompts large language models to automatically generate hypotheses, uses debuggers to actively interact with buggy code, and thus automatically reach conclusions prior to patch generation. By aligning the reasoning of automated debugging more closely with that of human developers, we aim to produce intelligible explanations of how a specific patch has been generated, with the hope that the explanation will lead to more efficient and accurate developer decisions. Our empirical analysis on three program repair benchmarks shows that AutoSD performs competitively with other program repair baselines, and that it can indicate when it is confident in its results. Furthermore, we perform a human study with 20 participants, including six professional developers, to evaluate the utility of explanations from AutoSD. Participants with access to explanations could judge patch correctness in roughly the same time as those without, but their accuracy improved for five out of six real-world bugs studied: 70% of participants answered that they wanted explanations when using repair tools, while 55% answered that they were satisfied with the Scientific Debugging presentation.
연구 동기 및 목표
- 자동화된 추론을 인간의 디버깅 프로세스와 일치시키기 위해 설명 가능한 자동 디버깅을 고무한다.
- LLMs를 사용하여 가설과 디버깅 실험을 디버거 인터페이스를 통해 생성하는 AutoSD를 제안한다.
- AutoSD가 추적 가능한 설명을 제공하면서 경쟁력 있는 프로그램 수리 성능을 달성함을 보여준다.
- 설명의 유용성을 개발자 중심의 인간 연구를 통해 평가한다.
제안 방법
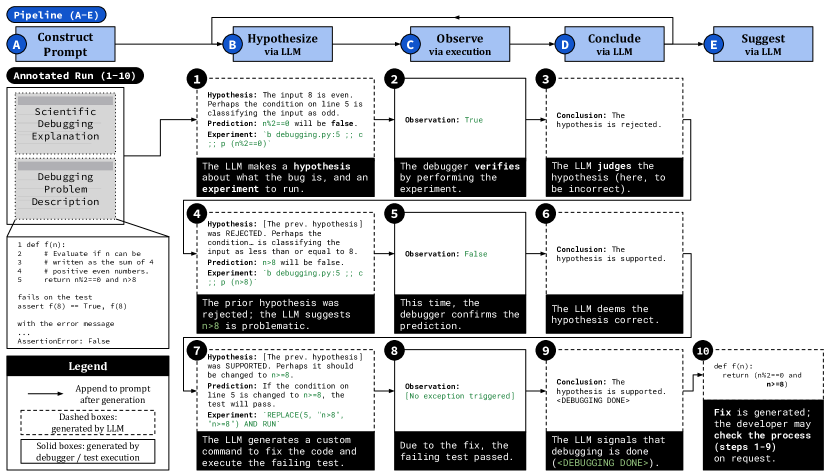
- 가설과 대응하는 디버깅 실험을 생성하기 위해 상세한 Scientific Debugging 프레임워크로 LLM에 프롬프트를 제공한다.
- 제안된 디버거 명령이나 테스트 가설을 검증하기 위한 편집-실행 스크립트를 실행한다.
- Hypothesize-Observe-Conclude 반복을 통해 가설을 다듬고 <DONE> 신호나 반복 한도에 도달할 때까지 디버거 결과를 사용한다.
- 패치를 생성하고 개발자 검토를 위해 중간 추론 단계를 추적하는 설명을 생성한다.
실험 결과
연구 질문
- RQ1RQ1 실현 가능성: AutoSD가 설명을 제공하더라도 기존 APR 기법과 경쟁하는가?
- RQ2RQ2 디버거 제거: <DONE> 토큰이 더 높은 정확도와 상관관계가 있는가, 예측된 디버거 출력이 성능에 어떤 영향을 미치는가?
- RQ3RQ3 LLM 다양화: 서로 다른 기본 LLM에서 AutoSD의 성능은 어떻게 달라지는가?
- RQ4RQ4 개발자 혜택: 설명이 실제 환경에서 패치의 정확성을 개발자가 판단하는 데 도움이 되는가?
- RQ5RQ5 개발자 수용: 설명이 개발자에게 받아들여지고 바람직한가?
주요 결과
| 벤치마크 | 가능성 있음(템플릿 기반) | 가능성 있음(LLM-기초) | 가능성 있음(AutoSD) | 정확함(LLM-기초) | 정확함(AutoSD) |
|---|---|---|---|---|---|
| ARHE | 85.77 ± 4.20 | 179 | 189 | 177 | 187 |
| Defects4J v1.2 | 24 | 41 | 87 | 76 | |
| Defects4J v2.0 | 11 | 28 | 110 | 113 |
- AutoSD는 또한 설명을 제공하면서 벤치마크 3개(ARHE, Defects4J v1.2/v2.0)에서 기저 시스템과 비교해 경쟁력 있는 수리 성능을 달성한다.
- <DONE> 토큰은 더 높은 정밀도를 나타내며 AutoSD가 올바른 패치를 생성할 가능성이 높은 시점을 시사하며, 디버거-backed 결과가 신뢰성을 향상시킨다.
- 더 크거나 더 능력이 있는 LLM을 사용할수록 AutoSD의 성능이 향상되는 경향이 있으며, 실험에서 ChatGPT가 강력한 기본값으로 사용된다.
- 인간 연구에서 설명은 6개의 실제 버그 중 5개에서 개발자의 정확도를 향상시켰고, APR 도구에 대한 참가자들의 가치를 높였다.
- 참가자의 70%가 APR 도구에 설명을 원했고, 55%가 Scientific Debugging 프레젠테이션에 만족했다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.