[논문 리뷰] Exploring Autonomous Agents through the Lens of Large Language Models: A Review
이 리뷰는 대형 언어 모델이 자율 에이전트를 어떻게 가능하게 하는지 조사하고, 아키텍처, 도구, 추론 전략, 평가 플랫폼을 상세히 다루며 도전과 미래 방향을 개략합니다.
Large Language Models (LLMs) are transforming artificial intelligence, enabling autonomous agents to perform diverse tasks across various domains. These agents, proficient in human-like text comprehension and generation, have the potential to revolutionize sectors from customer service to healthcare. However, they face challenges such as multimodality, human value alignment, hallucinations, and evaluation. Techniques like prompting, reasoning, tool utilization, and in-context learning are being explored to enhance their capabilities. Evaluation platforms like AgentBench, WebArena, and ToolLLM provide robust methods for assessing these agents in complex scenarios. These advancements are leading to the development of more resilient and capable autonomous agents, anticipated to become integral in our digital lives, assisting in tasks from email responses to disease diagnosis. The future of AI, with LLMs at the forefront, is promising.
연구 동기 및 목표
- LLMs가 다양한 도메인에서 자율 에이전트를 가능하게 하는 방식을 평가한다.
- LLM 기반 에이전트의 핵심 아키텍처, 기억, 추론 및 행동 구성요소를 요약한다.
- 자율 에이전트를 구축하고 테스트하기 위한 현재의 프레임워크와 도구를 평가한다.
- 주요 도전과제(다중 모달성, 정렬, 환각) 및 제시된 해결책을 식별한다.
- 오픈 소스 모델과 도구 통합을 위한 개방된 가능성을 강조한다.
제안 방법
- 트랜스포머 기반 아키텍처와 그 인코더/디코더 구성에 대해 설명한다.
- LLM 기반 에이전트의 기억, 계획 및 행동 구성요소를 논의한다.
- CoT, SPR, MPR, ToT, GoT, ReAct, Reflexion을 포함한 추론/행동 패러다임을 설명한다.
- 검색 강화(RAG) 및 도구/사용 프레임워크(LangChain, LiteLLM, Auto-GPT)를 검토한다.
- 평가 플랫폼(AgentBench, WebArena, ToolLLM)을 비교하고 주관적 평가 고려사항을 다룬다.
![Figure 1: Architecture of Transformer (Based on [ 86 ] )](https://ar5iv.labs.arxiv.org/html/2404.04442/assets/Figures/Transformer.jpg)
실험 결과
연구 질문
- RQ1LLM 기반 자율 에이전트를 가능하게 하는 핵심 아키텍처 구성요소(기억, 계획, 행동)는 무엇인가?
- RQ2어떤 프롬팅, 추론 및 도구 사용 전략이 LLM이 자율적으로 행동하도록 가장 잘 지원하는가?
- RQ3LLM 기반 에이전트를 위한 평가 프레임워크는 무엇이 있으며, 이것들은 전통적 방법과 어떻게 비교되는가?
- RQ4LLM 주도 자율 에이전트 배치의 주요 한계와 사회적 함의는 무엇인가?
- RQ5다중 모달 및 오픈 소스 접근법이 자율 에이전트 개발에 어떤 영향을 미치는가?
주요 결과
- LLM 기반 에이전트는 기억, 계획, 그리고 행동을 통합하여 자율적인 작업 수행을 달성한다.
- 도구 사용과 검색 보강 생성은 텍스트 생성을 넘어 LLM 능력을 확장하는 데 핵심이다.
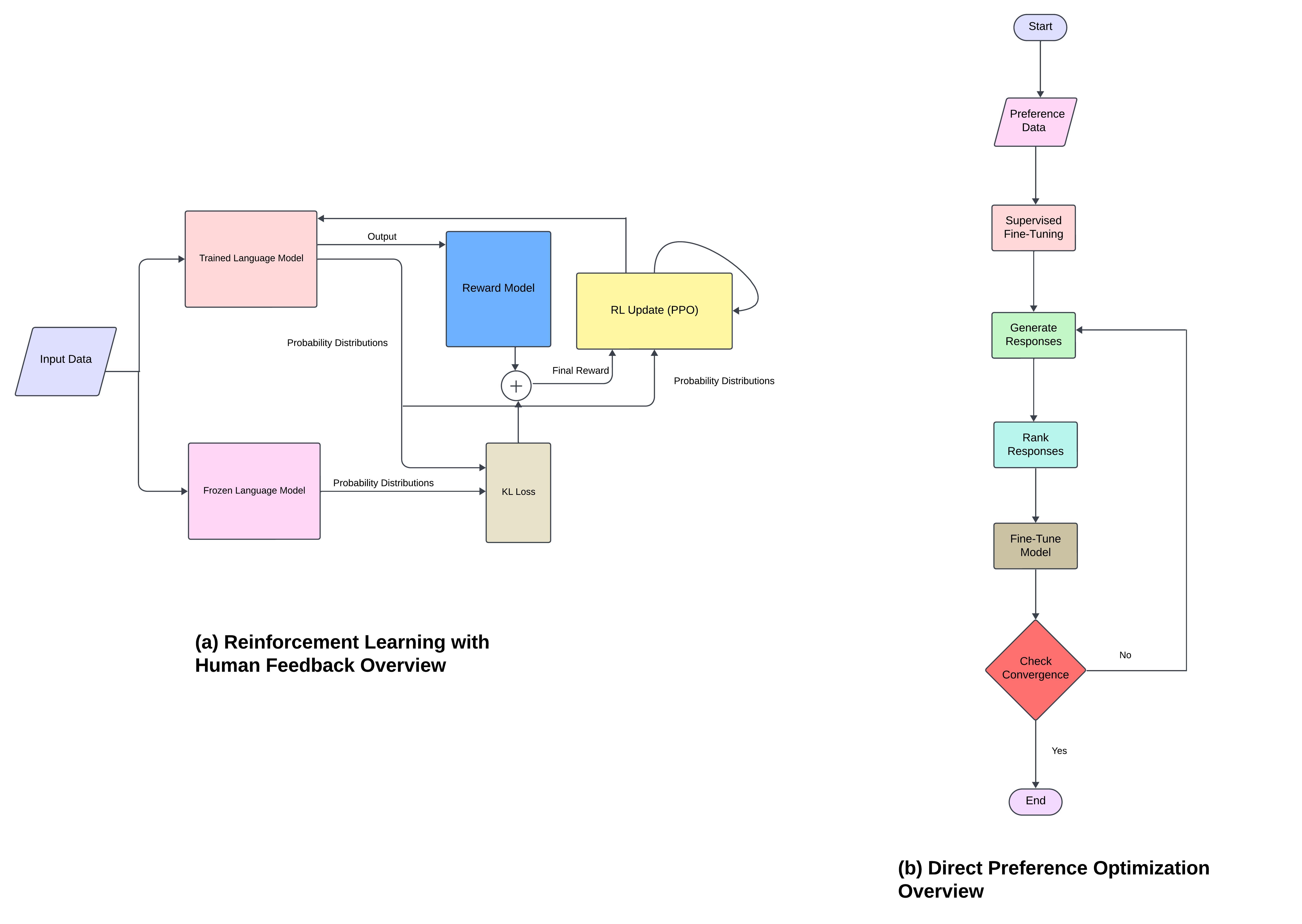
- 고급 추론 프레임워크(CoT, ToT, GoT, ReAct, RLHF/DPO)가 의사결정과 성능을 향상시킨다.
- AgentBench, WebArena, ToolLLM 같은 평가 플랫폼은 확장 가능한 평가를 제공하며, 주관적 평가가 인간 중심의 고려사항을 강조한다.
- 오픈 소스 LLM과 모듈식 도구 에코시스템(LangChain, LiteLLM)은 접근성과 잠재적 개선을 민주화한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.