[논문 리뷰] Exploring the Intersection of Large Language Models and Agent-Based Modeling via Prompt Engineering
본 논문은 프롬프트 엔지니어링을 활용한 LLM 구동 에이전트 시뮬레이션(두 에이전트 협상 및 여섯 에이전트 살인 미스터리)을 제시하고, 타당성을 분석하며 맥락 창 병목 현상과 같은 한계점을 논의한다.
The final frontier for simulation is the accurate representation of complex, real-world social systems. While agent-based modeling (ABM) seeks to study the behavior and interactions of agents within a larger system, it is unable to faithfully capture the full complexity of human-driven behavior. Large language models (LLMs), like ChatGPT, have emerged as a potential solution to this bottleneck by enabling researchers to explore human-driven interactions in previously unimaginable ways. Our research investigates simulations of human interactions using LLMs. Through prompt engineering, inspired by Park et al. (2023), we present two simulations of believable proxies of human behavior: a two-agent negotiation and a six-agent murder mystery game.
연구 동기 및 목표
- 전통적인 에이전트 규칙을 넘어 인간 주도 상호작용을 모델링하기 위해 ABM과 LLM의 결합을 모티브로 삼는다.
- 에이전트 페르소나와 프롬프트를 형성해 결과를 연구하는 LLM 주도 시뮬레이션을 소개한다.
- LLM 주도 시뮬레이션을 일대일, 일대다, 다대다로 분류한다.
- 맥락 창 4,096 토큰과 같은 병목 현상을 강조하고 향후 개선 가능성을 논의한다.
제안 방법
- 정의된 페르소나를 지닌 대화 기반 LLM 에이전트에 대해 OpenAI GPT-3.5-turbo를 사용한다.
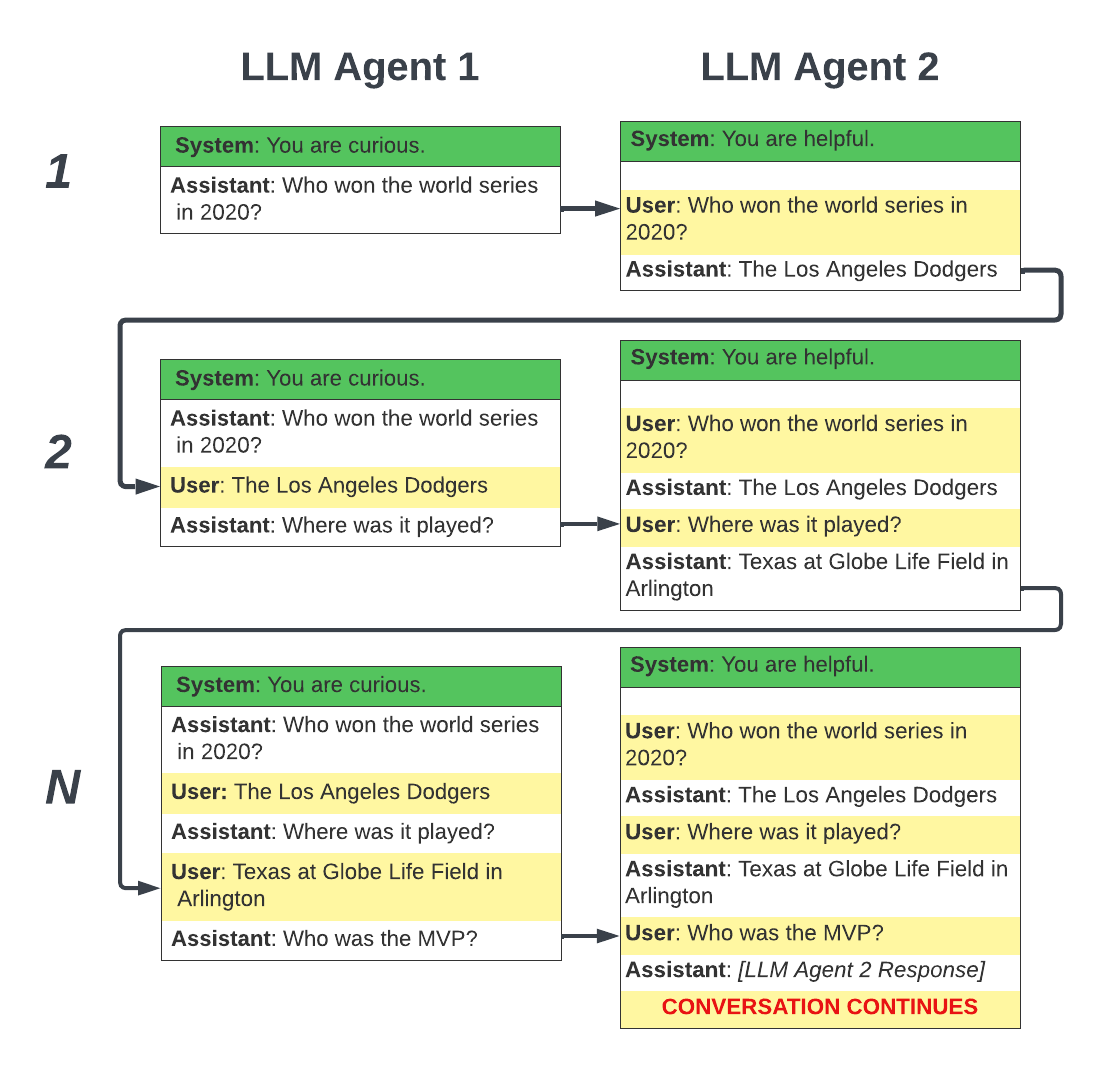
- 에이전트가 누적 대화 기록과 함께 서로 응답하는 자율적인 왕복 prompting을 구현한다.
- 대화를 일관되게 유지하기 위한 라운드 로빈 상호작용 메커니즘을 채택한다.
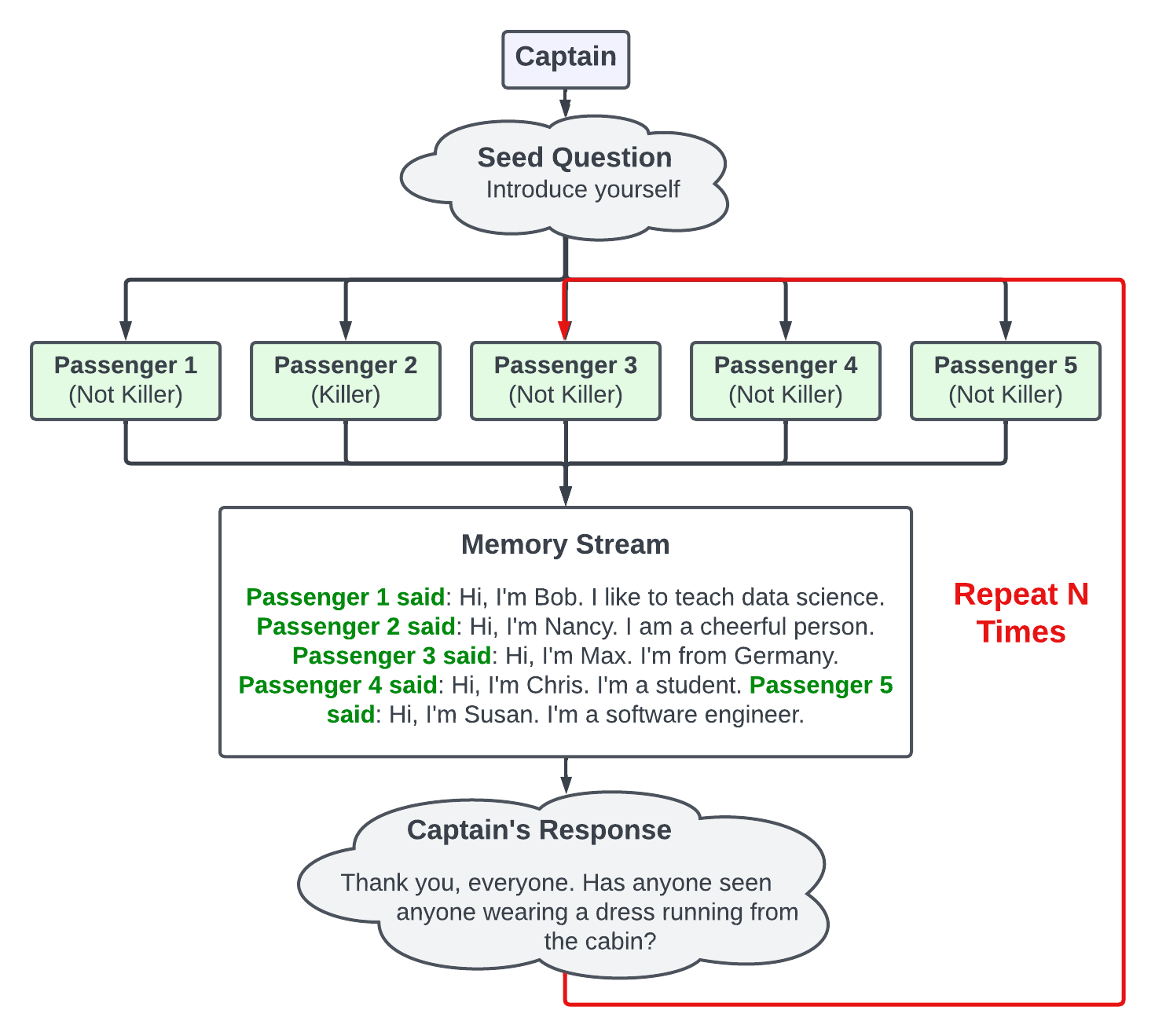
- 그룹 시뮬레이션에서 다수의 승객 에이전트 간 문맥을 보존하기 위해 메모리 스트림을 활용한다.
- 페르소나 설계가 나타나는 전략과 결과에 어떤 영향을 미치는지 분석한다.
- 최종 프롬프트 토큰 수를 보고하고 확장성 제약을 논의한다.
실험 결과
연구 질문
- RQ1프롬프트 엔지니어링이 자율적인 LLM 에이전트가 그럴듯한 인간 상호작용을 시뮬레이션하도록 어떻게 도울 수 있는가?
- RQ2LLM 주도 시뮬레이션을 가장 잘 설명하는 범주는 무엇이며(일대일, 일대다, 다대다) 어떤 한계가 있는가?
- RQ3대규모의 인간 현실감 있는 LLM 시뮬레이션을 제한하는 주요 병목은 무엇인가(예: 맥락 창)?
- RQ4페르소나 형식이 명시적 목표와 다른 새로운 전략의 변화를 이끄는가?
주요 결과
| Seller Objective | Buyer Objective | Outcome | Final Prompt Token |
|---|---|---|---|
| Sell for over $20 | Negotiate for lowest price | Sold for $25 | 522 |
| Sell for around $20 | Negotiate for lowest price | Sold for $17 | 369 |
| Sell for over $20 | Buy for under $20 | No deal | 472 |
- 두 에이전트 흥정 시뮬레이션에서 최종 가격이 $25에 이르러 판매자 목표인 $20를 초과했다.
- 여섯 에이전트 살인 미스터리 시뮬레이션은 메모리 스트림을 통해 에이전트 간 맥락을 유지하면서 일대다 대화를 시연한다.
- 프롬프트화된 페르소나는 판매자가 초기 가격을 올리는 것과 같은 emergent 협상 전략을 낳을 수 있다.
- 간단한 시나리오의 최종 프롬프트 토큰 수는 약 300~600 토큰으로, gpt-3.5-turbo의 4,096 토큰 한도에 비해 충분히 작다.
- 세 가지 시나리오 변형은 에이전트 목표를 바꿀 때 결과가 어떻게 달라지는지 보여준다(예: $20 이상 판매 -> $25; 약 $20 판매 -> $17; 반대 제약으로 합의 없음).
- 연구는 제약을 논의하고 더 긴 맥락 창과 메모리 스트림 강화된 검색과 같은 대형 시뮬레이션의 개선점을 제시한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.