[논문 리뷰] Facial Affect Recognition based on Transformer Encoder and Audiovisual Fusion for the ABAW5 Challenge
논문은 Transformer Encoder 기반의 다중모달 프레임워크와 Affine Module를 도입하여 오디오와 비주얼 특성을 융합하고, 네 ABAW5 하위 과제 모두에서 최신 결과를 달성했다 (VA, Expr, AU, ERI).
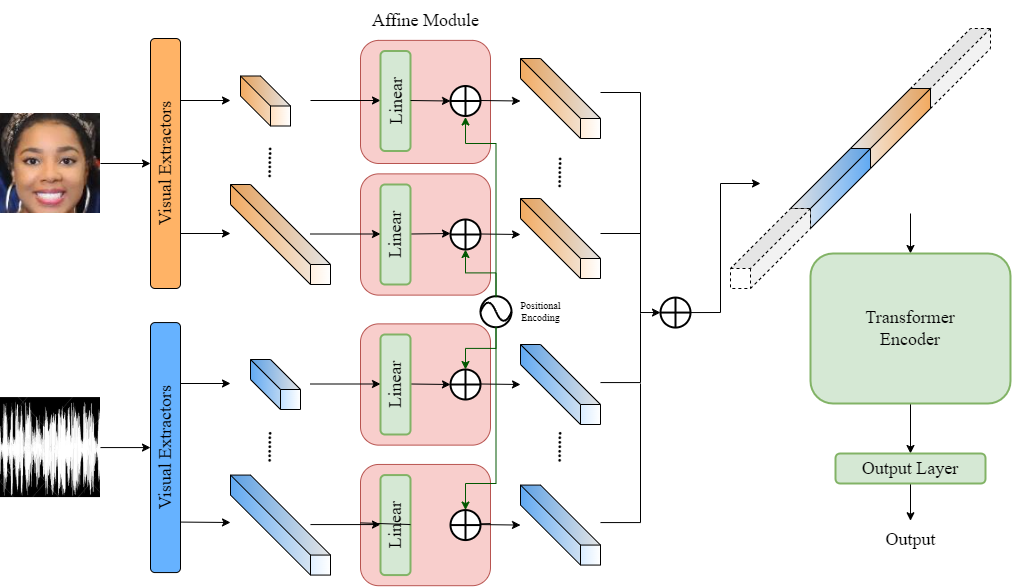
In this paper, we present our solutions for the 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW), which includes four sub-challenges of Valence-Arousal (VA) Estimation, Expression (Expr) Classification, Action Unit (AU) Detection and Emotional Reaction Intensity (ERI) Estimation. The 5th ABAW competition focuses on facial affect recognition utilizing different modalities and datasets. In our work, we extract powerful audio and visual features using a large number of sota models. These features are fused by Transformer Encoder and TEMMA. Besides, to avoid the possible impact of large dimensional differences between various features, we design an Affine Module to align different features to the same dimension. Extensive experiments demonstrate that the superiority of the proposed method. For the VA Estimation sub-challenge, our method obtains the mean Concordance Correlation Coefficient (CCC) of 0.6066. For the Expression Classification sub-challenge, the average F1 Score is 0.4055. For the AU Detection sub-challenge, the average F1 Score is 0.5296. For the Emotional Reaction Intensity Estimation sub-challenge, the average pearson's correlations coefficient on the validation set is 0.3968. All of the results of four sub-challenges outperform the baseline with a large margin.
연구 동기 및 목표
- 다양한 작업(VA, Expr, AU, ERI)에서 현장의 강건한 얼굴 표정 인식을 모티브로 삼는다.
- 최신 sota 모델로부터 다양한 오디오 및 비주얼 특징을 활용해 성능을 향상시킨다.
- 융합 전에 이질적인 특징 차원을 맞추기 위한 Affine Module을 도입한다.
- Transformer Encoder를 적용해 시간적 다이나믹스를 모델링하고 ERI에는 TEMMA를 적용한다.
- 네 가지 ABAW5 하위 과제 전반에 대해 베이스라인 대비 우수한 성능을 입증한다.
제안 방법
- 다양한 음향 인코더(IS09, VGGish, eGeMAPS, DeepSpectrum, CNN14)로 오디오 특징 추출.
- 다양한 아키텍처(EAC, ResNet18, POSTER, POSTER2, FAU, OPENFace FAU)로 비주얼 특징 추출.
- Affine Module로 이질적 특징 차원을 정렬하고 위치 인코딩을 더한다.
- 정렬된 특징을 연결하고 Transformer Encoder(ERI의 경우 TEMMA)로 시간 관계를 모델링한다.
- 예측을 태스크별 출력층으로 디코드하고 태스크에 맞는 손실(MSE VA/ERI, CE Expr, 가중된 비대칭 손실 AU)로 최적화한다.
- RAF-DB 및 AffectNet에서 비주얼 추출기를 사전 학습하고 ABAW5 데이터셋(Aff-Wild2 변형 및 Hume-Reaction)에서 학습·평가한다.
실험 결과
연구 질문
- RQ1Transformer 기반 인코더를 통해 융합된 다중모달 오디오-비주얼 특징이 모든 ABAW5 하위 과제의 성능 개선에 기여하는가?
- RQ2Affine Module로 이질적 특징 차원을 맞추는 것이 융합의 효과에 어떤 영향을 미치는가?
- RQ3TEMMA 기반의 시간 모델링이 표준 Transformer 인코더에 비해 ERI 추정에 이득을 주는가?
- RQ4어떤 특징 조합이 VA, Expr, AU, ERI 태스크에서 최상의 검증 성능을 낳는가?
주요 결과
| Features | VA | Arousal | Mean |
|---|---|---|---|
| Baseline | 0.24 | 0.20 | 0.22 |
| EAC | 0.4479 | 0.5878 | 0.5179 |
| POSTER | 0.3920 | 0.6317 | 0.5119 |
| ResNet18 | 0.4762 | 0.5671 | 0.5217 |
| POSTER2 | 0.5374 | 0.6297 | 0.5836 |
| ResNet18+VGGish | 0.4742 | 0.6220 | 0.5481 |
| ResNet18+POSTER2 | 0.5515 | 0.6429 | 0.5972 |
| ResNet18+POSTER2+FAU | 0.4868 | 0.6301 | 0.5585 |
| POSTER2+POSTER+VGGish | 0.5003 | 0.6946 | 0.5975 |
| EAC+ResNet18+POSTER2+VGGish | 0.5542 | 0.6590 | 0.6066 |
- VA 추정에서 가장 좋은 단일 특징은 POSTER2(Mean=0.5836)이고, 가장 좋은 다중 특징 조합은 ResNet18+POSTER2+FAU이며 Mean=0.5585를 달성하고, EAC, ResNet18, POSTER2, VGGish를 결합할 때 전체 평균 Mean 0.6066을 달성한다.
- VA 검증 평균 CCC가 0.6066으로 베이스라인 대비 큰 개선을 보여준다.
- Expr 분류는 POSTER2 단독으로 최상의 F1 점수(0.4055)를 달성하고, ResNet18과 POSTER2를 결합하면 (0.3957–0.4055 범위) 성능이 향상된다.
- AU 탐지는 POSTER2 및 FAU 특징으로 F1 점수가 베이스라인보다 높아 다중모달 융합이 효과적임을 시사한다.
- ERI 추정은 ResNet18과 DeepSpectrum를 결합할 때 PCC가 가장 높아 보완적인 오디오-비주얼 단서를 시사한다.
- ABAW5 전반에 걸쳐 네 가지 하위 과제가 모두 베이스라인을 상당한 차이로 능가한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.