[논문 리뷰] FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
FBNet은 Differentiable Neural Architecture Search를 활용해 목표 디바이스에 맞춘 하드웨어 인식 ConvNet을 설계하고, 낮은 대기 시간과 검색 비용 감소로 높은 정확도를 달성합니다. FBNet-B는 295M FLOPs와 23.1 ms의 지연으로 Samsung S8에서 ImageNet의 top-1 74.1%를 달성하며, 기존 NAS 방법들에 비해 검색 비용이 상당히 낮습니다.
Designing accurate and efficient ConvNets for mobile devices is challenging because the design space is combinatorially large. Due to this, previous neural architecture search (NAS) methods are computationally expensive. ConvNet architecture optimality depends on factors such as input resolution and target devices. However, existing approaches are too expensive for case-by-case redesigns. Also, previous work focuses primarily on reducing FLOPs, but FLOP count does not always reflect actual latency. To address these, we propose a differentiable neural architecture search (DNAS) framework that uses gradient-based methods to optimize ConvNet architectures, avoiding enumerating and training individual architectures separately as in previous methods. FBNets, a family of models discovered by DNAS surpass state-of-the-art models both designed manually and generated automatically. FBNet-B achieves 74.1% top-1 accuracy on ImageNet with 295M FLOPs and 23.1 ms latency on a Samsung S8 phone, 2.4x smaller and 1.5x faster than MobileNetV2-1.3 with similar accuracy. Despite higher accuracy and lower latency than MnasNet, we estimate FBNet-B's search cost is 420x smaller than MnasNet's, at only 216 GPU-hours. Searched for different resolutions and channel sizes, FBNets achieve 1.5% to 6.4% higher accuracy than MobileNetV2. The smallest FBNet achieves 50.2% accuracy and 2.9 ms latency (345 frames per second) on a Samsung S8. Over a Samsung-optimized FBNet, the iPhone-X-optimized model achieves a 1.4x speedup on an iPhone X.
연구 동기 및 목표
- ConvNet 설계에서 정확도와 실제 하드웨어 지연 간의 불일치를 모바일 디바이스에 맞춰 해결한다.
- 타겟 하드웨어에 맞춘 층별 아키텍처를 효율적으로 탐색하는 differentiable NAS (DNAS) 프레임워크를 개발한다.
- 아키텍처 탐색을 안내하기 위한 지연 인식 손실 및 differentiable latency estimator를 정의한다.
- 수동으로 설계된 모델 및 다른 자동 검색 모델보다 모바일 벤치마크에서 더 나은 FBNet 모델을 시연한다.
제안 방법
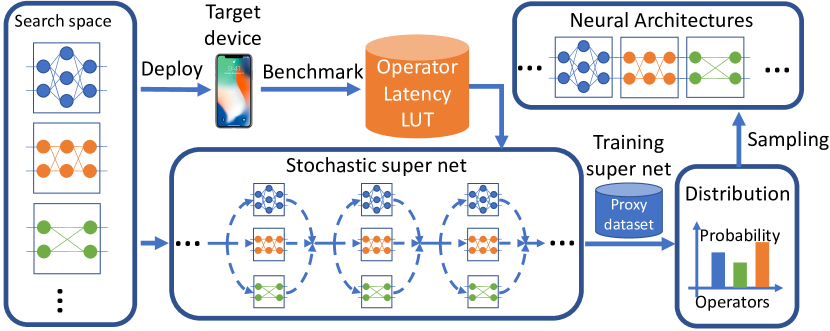
- 탐색 공간을 22개 층과 각 층당 9개의 후보 블록이 있는 계층별 매크로 아키텍처로 표현한다.
- 각 층이 Gumbel-Softmax를 통해 확률적으로 블록을 샘플하는 확률적 슈퍼 네트로 구성하여 그래디언트 기반 최적화를 가능하게 한다.
- LAT(a)가 differentiable LAT 추 up 표를 통해 추정될 수 있도록 LAT(a) = CE(a,w) * alpha * log(LAT(a))^beta 형태의 지연 인식 손실을 정의한다.
- LAT(a)를 LAT(a)=sum_l LAT(b_l^(a))로 추정하여 아키텍처 선택에 대해 지연을 미분 가능하게 만든다.
- 標준 CNN 학습에서와 같이 모든 연산자의 가중치 w_a를 학습하는 동안 아키텍처 파라미터 theta를 업데이트하여 더 높은 정확도와 더 낮은 지연의 블록을 선호하도록 한다.
- 학습된 분포 P_theta에서 최종 아키텍처를 샘플링하고 평가를 위해 무작위로 학습한다.
실험 결과
연구 질문
- RQ1DNAS가 목표 모바일 디바이스에 맞춘 하드웨어 인식 ConvNet을 효율적으로 발견할 수 있는가?
- RQ2지연 인식 objective를 도입하면 실제 지연이 낮아지면서 정확도가 떨어지지 않는 아키텍처를 얻을 수 있는가?
- RQ3레이어별 블록 유연성(셀 레벨 재사용 대비)이 실제 하드웨어에서의 정확도와 지연에 어떤 영향을 미치는가?
- RQ4다양한 입력 해상도 및 채널 확장에서 달성 가능한 정확도-지연 트레이드는 무엇인가?
- RQ5타깃 디바이스별 지연 특성이 디바이스별 네트워크 분리를 정당화하는가?
주요 결과
| 모델 | 검색 | 공간 | 검색 비용 (GPU 시간 / 상대) | 파라미터 수 | FLOPs | CPU 지연 | 지연 | Top-1 정확도 (%) |
|---|---|---|---|---|---|---|---|---|
| 1.0-MobileNetV2 | 수동 | - | - | 3.4M | 300M | 21.7 ms | - | 72.0 |
| 1.5-ShuffleNetV2 | 수동 | - | - | 3.5M | 299M | 22.0 ms | - | 72.6 |
| CondenseNet (G=C=8) | 수동 | - | - | 2.9M | 274M | 28.4 ms | - | 71.0 |
| MnasNet-65 | RL | stage-wise | 91K ∗ / 421x | 3.6M | 270M | - | - | 73.0 |
| DARTS | gradient | cell | 288 / 1.33x | 4.9M | 595M | - | - | 73.1 |
| FBNet-A (ours) | gradient | 레이어별 | 216 / 1.0x | 4.3M | 249M | 19.8 ms | - | 73.0 |
| 1.3-MobileNetV2 | 수동 | - | - | 5.3M | 509M | 33.8 ms | - | 74.4 |
| CondenseNet (G=C=4) | 수동 | - | - | 4.8M | 529M | 28.7 ms | - | 73.8 |
| MnasNet-65 | RL | stage-wise | - | 4.2M | 317M | - | - | 74.0 |
| NASNet-A | RL | cell | - | 5.3M | 564M | - | - | 74.0 |
| PNASNet | SMBO | cell | - | 5.1M | 588M | - | - | 74.2 |
| FBNet-B (ours) | gradient | 레이어별 | 216 / 1.0x | 4.5M | 295M | 23.1 ms | - | 74.1 |
| 1.4-MobileNetV2 | 수동 | - | - | 6.9M | 585M | 37.4 ms | - | 74.7 |
| 2.0-ShuffleNetV2 | 수동 | - | - | 7.4M | 591M | 33.3 ms | - | 74.9 |
| MnasNet-92 | RL | stage-wise | - | 4.4M | 388M | - | - | 74.8 |
| FBNet-C (ours) | gradient | 레이어별 | 216 / 1.0x | 5.5M | 375M | 28.1 ms | - | 74.9 |
- FBNet 모델은 최첨단 효율 네트워크와 비교해 적은 지연과 FLOPs로 경쟁력 있는 또는 우수한 정확도를 달성한다.
- FBNet-B는 295M FLOPs 및 23.1 ms 지연으로 Samsung S8에서 74.1% top-1 정확도를 달성하며 MobileNetV2-1.3를 능가하고 MnasNet에 근접하되 훨씬 낮은 검색 비용을 보인다.
- DNAS는 검색 비용을 약 216 GPU-시간으로 대폭 감소시켜 MnasNet 대비 약 421배 빠르고 보고된 비교에서 NAS/PNAS/DARTS에 비해 현저히 빠르다.
- 다양한 입력 해상도 및 채널 스케일로 확장하면 유사 지연에서 MobileNetV2 대비 절대 1.5%에서 6.4%의 정확도 증가를 얻는다.
- FBNet-small 변형은 매우 낮은 지연(최소 2.9 ms)으로 합리적인 정확도를 달성하고, iPhone X 대 Samsung S8와 같은 디바이스별 최적화가 온디바이스 속도를 크게 향상시킨다.
- FBNet-iPhoneX 및 FBNet-S8는 아키텍처 선택이 디바이스별 런타임에 적응함을 보여주며, 디바이스별 하드웨어 인식 설계의 필요성을 검증한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.