[논문 리뷰] FeatUp: A Model-Agnostic Framework for Features at Any Resolution
FeatUp은 심층 특징을 의미를 바꾸지 않으면서 더 높은 해상도로 업스케일하며, 빠른 JBU 기반 업샘플러 또는 이미지별 암시적 모델 중 하나를 이용하고 다중 뷰 일관성에 의해 안내됩니다.
Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features often lack the spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction because models aggressively pool information over large areas. In this work, we introduce FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. We introduce two variants of FeatUp: one that guides features with high-resolution signal in a single forward pass, and one that fits an implicit model to a single image to reconstruct features at any resolution. Both approaches use a multi-view consistency loss with deep analogies to NeRFs. Our features retain their original semantics and can be swapped into existing applications to yield resolution and performance gains even without re-training. We show that FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, transfer learning for segmentation and depth prediction, and end-to-end training for semantic segmentation.
연구 동기 및 목표
- 재학습이나 의미를 바꾸지 않고 심층 특징 표현에서 손실된 공간 해상도를 회복할 필요성을 제시한다.
- 다중 뷰 일관성을 강제하여 저해상도 뷰로부터 고해상도 특징을 재구성하는 프레임워크로 FeatUp를 제안한다.
- 빠른 순전파 JBU 기반 업샘플러와 이미지당 암시적 업샘플러의 두 가지 변형을 제시한다.
- FeatUp이 시맨틱 분할, 깊이 추정, CAM 설명과 같은 다운스트림 작업을 개선함을 보여준다.
제안 방법
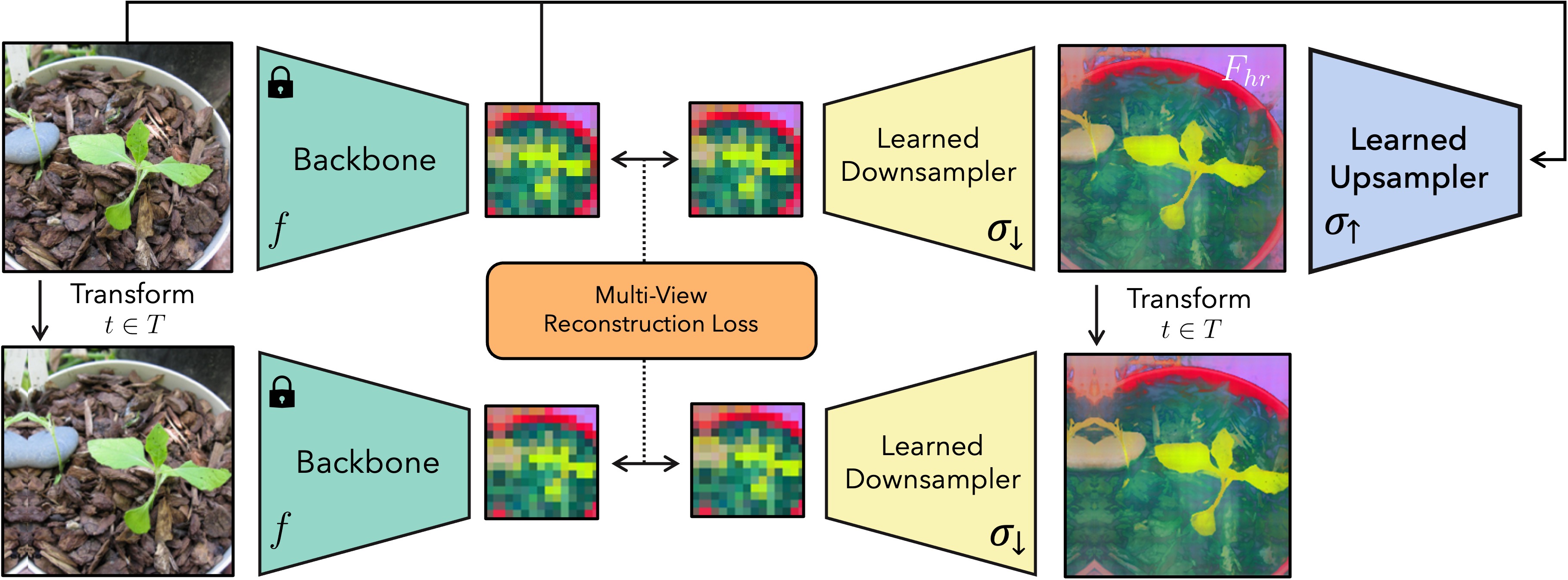
- 패딩, 스케일, 뒤집기 등의 지터된 입력 변환 전반에 걸친 다중 뷰 일관성을 통해 심층 특징을 업샘플링한다.
- (i) 빠르고 가이드된 순전파 모듈로서의 Joint Bilateral Upsampler (JBU); (ii) 이미지별 임의 해상도 출력에 대해 단일 이미지에 MLP를 과적합시키는 암시적 FeatUp.
- 고해상도 특징을 저해상도 뷰로 매핑하기 위한 학습된 다운샘플러(간단한 블러 또는 주의 기반) 도입.
- 적응 가능한 불확실성 항을 갖는 다운샘플된 고해상도 특징을 저해상도 백본 출력과 일치시키는 다중 뷰 재구성 손실 사용.
- 효율성을 위한 CUDA 가속 JBU 구현 제공과 수렴을 높이기 위한 암시적 모델의 선택적 Fourier 기반 특징.
- 암시적 특징의 크기를 안정시키기 위해 작은 전체 변이(prior)를 적용한다.
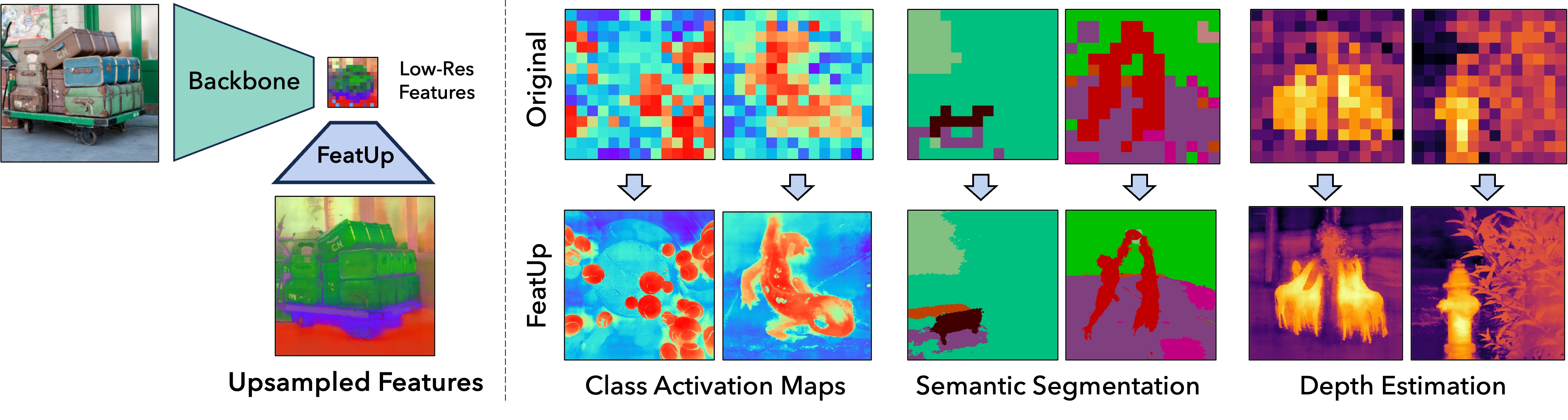
실험 결과
연구 질문
- RQ1의미를 바꾸거나 백본을 재학습하지 않고도 심층 특징의 공간 해상도를 크게 개선할 수 있는가?
- RQ2이미지 지터에 따른 다중 뷰 일관성이 고해상도 특징 재구성을 위한 강력한 감독 신호를 제공하는가?
- RQ3빠른 JBU 기반과 암시적 이미지별 업샘플링 방식이 백본과 작업 전반에서 품질, 속도, 메모리 사용 면에서 어떻게 비교되는가?
- RQ4FeatUp 특징이 다운스트림 밀도 예측 및 모델 설명 가능성을 개선하기 위한 드롭인 대체로 작동할 수 있는가?
- RQ5FeatUp 유래 특징이 모델 해석 가능성을 위한 CAM 품질에서 측정 가능한 이점을 제공하는가?
주요 결과
| Method | CAM Score A.D.↓ | CAM Score A.I.↑ | Semantic Seg. mIoU↑ | Semantic Seg. Acc↑ | Depth RMSE↓ | Depth δ>1.25↑ |
|---|---|---|---|---|---|---|
| Low-res | 10.69 | 4.81 | 65.17 | 40.65 | 1.25 | 0.894 |
| Bilinear | 10.24 | 4.91 | 66.95 | 42.40 | 1.19 | 0.910 |
| Resize-conv | 11.02 | 4.95 | 67.72 | 42.95 | 1.14 | 0.917 |
| DIP | 10.57 | 5.16 | 63.78 | 39.86 | 1.19 | 0.907 |
| Strided | 11.48 | 4.97 | 64.44 | 40.54 | 2.62 | 0.900 |
| Large image | 13.66 | 3.95 | 58.98 | 36.44 | 2.33 | 0.896 |
| CARAFE | 10.24 | 4.96 | 67.10 | 42.39 | 1.09 | 0.920 |
| SAPA | 10.62 | 4.85 | 65.69 | 41.17 | 1.19 | 0.917 |
| FeatUp (JBU) | 9.83 | 5.24 | 68.77 | 43.41 | 1.09 | 0.938 |
| FeatUp (Implicit) | 8.84 | 5.60 | 71.58 | 47.37 | 1.04 | 0.927 |
- FeatUp은 CAM 신뢰성, 시맨틱 분할, 깊이 추정 전반에 대해 기준 업샘플링 방법들(bilinear, resize-conv, DIP 등)을 일관되게 능가한다.
- 두 가지 FeatUp 변형(JBU 및 Implicit)은 고해상도 특징의 품질을 더 높게 제공하며, 여러 지표에서 암시적 변형이 다운스트림에서 가장 강한 개선을 달성한다.
- 전이 학습 실험에서 FeatUp 특징은 시맨틱 분할(mIoU) 및 깊이 추정(RMSE, delta>1.25)에 대한 선형 프로브 성능을 개선한다.
- FeatUp 업샘플링은 엔드투엔드 분할 모델의 드롭인 대체로 사용될 수 있으며, 평균 IoU, 평균 정확도, 픽셀 정확도를 향상시키고 FLOPs/매개변수와 비교해 경쟁력 있다.
- CUDA 가속 JBU 구현은 비전형 구현과 비교해 최대 약 10배의 속도 증가와 현저히 낮은 메모리 사용량을 제공한다.
- 암시적 FeatUp는 Fourier 색상 특징의 이점을 받아 더 빠른 수렴과 더 높은 주파수 디테일 포착을 가능하게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.