[논문 리뷰] Feature Denoising for Improving Adversarial Robustness
논문은 CNN에 통합된 특징 잡음 제거 블록(feature denoising blocks)을 도입하고 적대적 학습으로 강한 화이트박스 및 블랙박스 공격에 대한 강인성을 높여 ImageNet에서 최첨단 결과를 달성하고 CAAD 2018 방어에서 우승했다.
Adversarial attacks to image classification systems present challenges to convolutional networks and opportunities for understanding them. This study suggests that adversarial perturbations on images lead to noise in the features constructed by these networks. Motivated by this observation, we develop new network architectures that increase adversarial robustness by performing feature denoising. Specifically, our networks contain blocks that denoise the features using non-local means or other filters; the entire networks are trained end-to-end. When combined with adversarial training, our feature denoising networks substantially improve the state-of-the-art in adversarial robustness in both white-box and black-box attack settings. On ImageNet, under 10-iteration PGD white-box attacks where prior art has 27.9% accuracy, our method achieves 55.7%; even under extreme 2000-iteration PGD white-box attacks, our method secures 42.6% accuracy. Our method was ranked first in Competition on Adversarial Attacks and Defenses (CAAD) 2018 --- it achieved 50.6% classification accuracy on a secret, ImageNet-like test dataset against 48 unknown attackers, surpassing the runner-up approach by ~10%. Code is available at https://github.com/facebookresearch/ImageNet-Adversarial-Training.
연구 동기 및 목표
- 적대적 섭동이 네트워크 특징에 노이즈를 유발하고 예측을 악화시키는지 여부를 동기화한다.
- 중간 계층에서 특징 노이즈를 억제하는 엔드-투-엔드 학습 가능한 denoising 블록을 개발한다.
- ImageNet에서 강력한 화이트박스 및 블랙박스 공격에 대한 강인성을 체계적으로 평가한다.
- 다양한 denoising 연산 및 아키텍처 선택지를 비교하여 효과적인 설계를 식별한다.
- denoising 블록 사용 시 적대적 강인성과 클린 정확도 간의 트레이드-오프를 평가한다.
제안 방법
- ResNet 백본의 선택된 잔차 블록(res2, res3, res4, res5) 뒤에 denoising 블록을 삽입한다.
- 블록 내에서 non-local means, bilateral filtering, mean filtering, median filtering 등의 denoising 연산을 사용한다.
- denoising 연산을 1x1 컨볼루션과 잔차 연결로 감싸 정화된 특징을 입력과 융합한다.
- 대규모 ImageNet에서 PGD(epsilon=16, 30 iterations)를 사용한 적대적 학습으로 엔드-투-엔드로 학습하되 128-GPU 분산 설정을 사용한다.
- 가장 성능이 좋은 denoising 변형으로 Gaussian 가중치를 갖는 non-local means를 식별하고, 1x1 레이어 및 잔차 연결의 역할을 연구하기 위한 제거 실험(ablation)을 수행한다.
- 화이트박스 PGD 공격(10–2000 반복) 및 블랙박스 CAAD 2017/2018 스타일 공격 하에서 평가하고 top-1 정확도와 올-오브-너싱 기준을 보고한다.
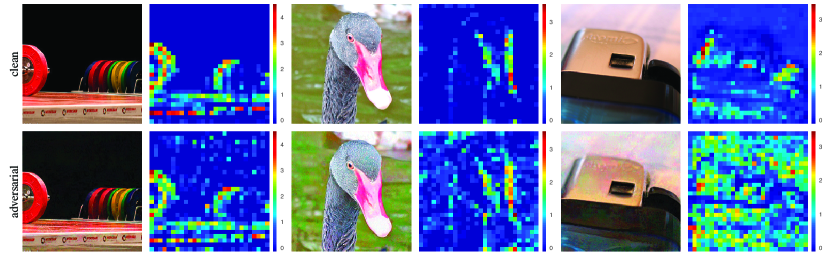
![Figure 1: Feature map in the res 3 block of an ImageNet-trained ResNet-50 [ 9 ] applied on a clean image (top) and on its adversarially perturbed counterpart (bottom). The adversarial perturbation was produced using PGD [ 16 ] with maximum perturbation $\epsilon\!=\!$ 16 (out of 256). In this exampl](https://ar5iv.labs.arxiv.org/html/1812.03411/assets/x1.png)
실험 결과
연구 질문
- RQ1특징 수준의 denoising이 중간 CNN 표현에서 adversarial로 유발된 노이즈를 줄일 수 있는가?
- RQ2화이트박스 PGD 공격하에서 어떤 denoising 연산(non-local means, bilateral, mean, median)이 강인성을 가장 잘 개선하는가?
- RQ3denoising 블록과 적대적 학습을 결합하면 white-box 및 black-box 공격에 대해 ImageNet에서 최첨단 강인성을 달성하는가?
- RQ4denoising 블록 사용 시 적대적 강인성과 클린 정확도 사이의 트레이드-오프는 어떠한가?
주요 결과
| 공격 반복 수 | 비국소, 가우시안 (ResNet-152) | 1x1 제거 | 잔차 제거 |
|---|---|---|---|
| 10 | 55.7 | 52.1 | NaN |
| 100 | 45.5 | 36.8 | NaN |
- 10-회의 PGD 하에서 ResNet-152에 네 개의 denoising 블록을 추가하면 Baseline 대비 55.7%의 정확도를 달성한다(대비 52.5%).
- 2000-iteration PGD 하에서 denoising 모델은 42.6%의 정확도, baseline은 39.2% 이다.
- 블랙박스 CAAD 2018 방어에서 비밀 ImageNet 유사 테스트 데이터 세트에서 50.6% 정확도를 달성하여 준우승자보다 약 10포인트 높은 방어 트랙 우승을 기록했다.
- 1x1 컨볼루션을 제거하면 성능이 크게 감소하는 등(ablation) 두 구성 요소 모두 중요함(예: 100 반복에서 1x1 제거 시 45.5%에서 36.8%로 감소); 잔차 연결 제거는 학습을 불안정하게 만들어 두 구성 요소 모두 중요함.
- 비국소 denoising 블록은 국소 denoising을 넘어서는 강인성 이점을 제공하며, 가우시안 비국소 평균이 변종 중에서 가장 우수했다.
- 비적대적(클린) 설정에서는 denoising 블록이 정확도를 크게 향상시키지 않아 강인성 특화 이점을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.