[논문 리뷰] FeCAM: Exploiting the Heterogeneity of Class Distributions in Exemplar-Free Continual Learning
FeCAM은 클래스별 공분산(마할라노비스 거리)을 활용하는 베이지안 분류기를 도입하여 exemplar-free 지속적 학습에서 이질적 특징 분포를 처리하고, Euclidean 기반 프로토타입 대비 많은 샷 및 적은 샷 CIL 및 도메인 증가 작업에서 성능을 향상시킵니다.
Exemplar-free class-incremental learning (CIL) poses several challenges since it prohibits the rehearsal of data from previous tasks and thus suffers from catastrophic forgetting. Recent approaches to incrementally learning the classifier by freezing the feature extractor after the first task have gained much attention. In this paper, we explore prototypical networks for CIL, which generate new class prototypes using the frozen feature extractor and classify the features based on the Euclidean distance to the prototypes. In an analysis of the feature distributions of classes, we show that classification based on Euclidean metrics is successful for jointly trained features. However, when learning from non-stationary data, we observe that the Euclidean metric is suboptimal and that feature distributions are heterogeneous. To address this challenge, we revisit the anisotropic Mahalanobis distance for CIL. In addition, we empirically show that modeling the feature covariance relations is better than previous attempts at sampling features from normal distributions and training a linear classifier. Unlike existing methods, our approach generalizes to both many- and few-shot CIL settings, as well as to domain-incremental settings. Interestingly, without updating the backbone network, our method obtains state-of-the-art results on several standard continual learning benchmarks. Code is available at https://github.com/dipamgoswami/FeCAM.
연구 동기 및 목표
- 클래스 분포의 이질성이 exemplar-free CIL 성능에 어떤 영향을 미치는지 조사한다.
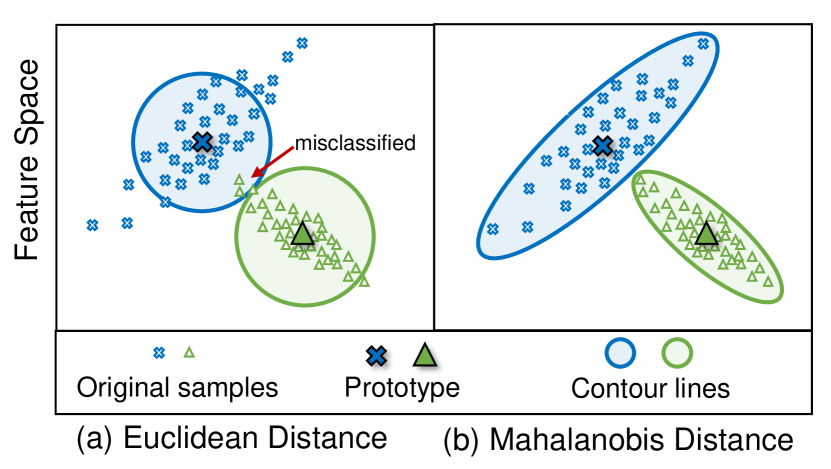
- 다항성(NCM) 분류기 대비 Euclidean 거리보다 per-class 공분산을 사용하는 anisotropic(마할라노비스) 거리가 분류 성능을 개선하는지 평가한다.
- 고정된 백본과 사전 학습된 특징에서도 효과적인 공분산 인식 FeCAM 분류기를 개발한다.
- FeCAM의 적용 가능성을 많은 샷, 적은 샷, 도메인 증가 지속적 학습 설정 전반에 걸쳐 입증한다.
제안 방법
- 고정된 백본으로 프로토타입을 형성하기 위해 프로토타입 네트워크를 사용한다.
- 특징을 클래스 프로토타입과 비교하기 위해 anisotropic 마할라노비스 거리(FeCAM)를 채택한다.
- 클래스별 공분산 행렬을 계산하고 정규화한다; 역행렬 가능성을 보장하기 위해 공분산 수축(shrinkage)을 적용한다.
- 공분산 추정 전에 Tukey의 사다리 변환을 적용하여 특징 분포를 안정화한다.
- 클래스 간 및 작업 간 공분산 행렬을 비교 가능하게 하기 위해 상관관계 정규화를 수행한다.
- 클래스 공분산을 활용한 베이즈 분류기가 가우시안 샘플에서 학습된 선형 분류기보다 비선형적이고 더 최적의 결정 경계를 생성함을 주장하고 검증한다.
![Figure 1 : Illustration of feature representations in CIL settings. In Joint Training (a), deep neural networks learn good isotropic spherical representations [ 17 ] and thus the Euclidean metric can be used effectively. However, it is challenging to learn isotropic representations of both old and n](https://ar5iv.labs.arxiv.org/html/2309.14062/assets/x1.png)
실험 결과
연구 질문
- RQ1특징 분포의 Episodic 이질성이 exemplar-free CIL에서 특히 새로운 클래스의 Euclidean NCM 성능을 저해하는가?
- RQ2per-class 공분산을 가진 공분산 인식 마할라노비스 거리가 전통적 Euclidean 거리보다 exemplar-free CIL에서 분류를 개선하는가?
- RQ3FeCAM의 성능 향상을 위해 공분산 정규화, 수축, Tukey 변환이 필수 구성요소인가?
- RQ4FeCAM이 백본을 업데이트하지 않고도 많은 샷, 적은 샷, 도메인 증가 지속적 학습 벤치마크에서 일반화되는가?
주요 결과
| CIL 방법 | CIFAR-100 (T=5) Avg Acc | CIFAR-100 (T=10) Avg Acc | CIFAR-100 (T=20) Avg Acc | TinyImageNet (T=5) Avg Acc | TinyImageNet (T=10) Avg Acc | TinyImageNet (T=20) Avg Acc | ImageNet-Subset (T=5) Avg Acc | ImageNet-Subset (T=10) Avg Acc | ImageNet-Subset (T=20) Avg Acc |
|---|---|---|---|---|---|---|---|---|---|
| EWC | 24.5 | 21.2 | 15.9 | 18.8 | 15.8 | 12.4 | - | 20.4 | - |
| LwF-MC | - | - | - | - | - | - | - | - | - |
| DeeSIL | 60.0 | 50.6 | 38.1 | 49.8 | 43.9 | 34.1 | 67.9 | 60.1 | 50.5 |
| MUC | 49.4 | 30.2 | 21.3 | 32.6 | 26.6 | 21.9 | - | - | - |
| SDC | 56.8 | 57.0 | 58.9 | - | - | - | - | - | - |
| PASS | 63.5 | 61.8 | 58.1 | 49.6 | 47.3 | 42.1 | 64.4 | 61.8 | 51.3 |
| IL2A | 66.0 | 60.3 | 57.9 | 47.3 | 44.7 | 40.0 | - | - | - |
| SSRE | 65.9 | 65.0 | 61.7 | 50.4 | 48.9 | 48.2 | - | - | - |
| FeTrIL* | 67.6 | 66.6 | 63.5 | 55.4 | 54.3 | 53.0 | 73.1 | 71.9 | 69.1 |
| Eucl-NCM | 64.8 | 64.6 | 61.5 | 54.1 | 53.8 | 53.6 | 72.2 | 72.0 | 68.4 |
| FeCAM (Σ^{1:t}) | 68.8 | 68.6 | 67.4 | 56.0 | 55.7 | 55.5 | 75.8 | 75.6 | 73.5 |
| FeCAM (Σ_y) | 70.9 | 70.8 | 69.4 | 59.6 | 59.4 | 59.3 | 78.3 | 78.2 | 75.1 |
- 공통 공분산 행렬(Σ^{1:t})을 사용하는 FeCAM이 CIFAR-100, TinyImageNet, ImageNet-Subset에서 이전의 exemplar-free CIL 방법들을 이미 능가한다.
- 개별 클래스 공분산 행렬(Σ_y)을 사용하는 것이 평균 증분 정확도를 더욱 향상시키며 공분산 공용 변형보다 우수하다.
- 개별 클래스 공분산을 사용하는 FeCAM은 엔드-태스크 정확도를 더 높이고 도메인 증가 CoRe50를 포함한 모든 작업에서도 강한 성능을 유지한다.
- 공분산 관계를 활용하는 베이즈 분류기가 가우시안 특징을 샘플링하고 선형 분류기를 학습하는 방법보다 현저히 높은 정확도를 제공한다.
- 공분산 정규화(Eq. 7)와 공분산 수축(Eq. 8)은 오래된 클래스와 새 클래스 간의 분산 변화를 다루고 역행렬 가능성을 보장하는 데 중요하다.
- FeCAM은 사전 학습된 백본(ViT)에도 잘 확장되며 백본 업데이트 없이 여러 벤치마크에서 최첨단 결과를 달성한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.