[논문 리뷰] FICE: Text-Conditioned Fashion Image Editing With Guided GAN Inversion
FICE 편집은 패션 이미지의 GAN 반전을 텍스트 설명으로 안내하여 자세/신원을 보존하면서 CLIP 기반 의미론과 이미지 스티칭으로 새로운 의상을 통합합니다.
Fashion-image editing represents a challenging computer vision task, where the goal is to incorporate selected apparel into a given input image. Most existing techniques, known as Virtual Try-On methods, deal with this task by first selecting an example image of the desired apparel and then transferring the clothing onto the target person. Conversely, in this paper, we consider editing fashion images with text descriptions. Such an approach has several advantages over example-based virtual try-on techniques, e.g.: (i) it does not require an image of the target fashion item, and (ii) it allows the expression of a wide variety of visual concepts through the use of natural language. Existing image-editing methods that work with language inputs are heavily constrained by their requirement for training sets with rich attribute annotations or they are only able to handle simple text descriptions. We address these constraints by proposing a novel text-conditioned editing model, called FICE (Fashion Image CLIP Editing), capable of handling a wide variety of diverse text descriptions to guide the editing procedure. Specifically with FICE, we augment the common GAN inversion process by including semantic, pose-related, and image-level constraints when generating images. We leverage the capabilities of the CLIP model to enforce the semantics, due to its impressive image-text association capabilities. We furthermore propose a latent-code regularization technique that provides the means to better control the fidelity of the synthesized images. We validate FICE through rigorous experiments on a combination of VITON images and Fashion-Gen text descriptions and in comparison with several state-of-the-art text-conditioned image editing approaches. Experimental results demonstrate FICE generates highly realistic fashion images and leads to stronger editing performance than existing competing approaches.
연구 동기 및 목표
- 의도와 가능성을 부여하고 대상 의상 이미지를 필요로 하지 않는 자연어 설명으로 패션 이미지를 편집하도록 동기 부여하고 이를 가능하게 한다.
- 의상 영역만 편집하고 피사체의 자세, 신원, 배경은 보존한다.
- 역전 과정에서 의미론, 자세, 이미지 일관성 제약을 적용하기 위해 CLIP과 보조 미분 가능 모델을 활용한다.
- 현실감을 높이고 편집을 잘 정의된 잠재 공간으로 제한하기 위해 잠재 코드 정규화를 도입한다.
제안 방법
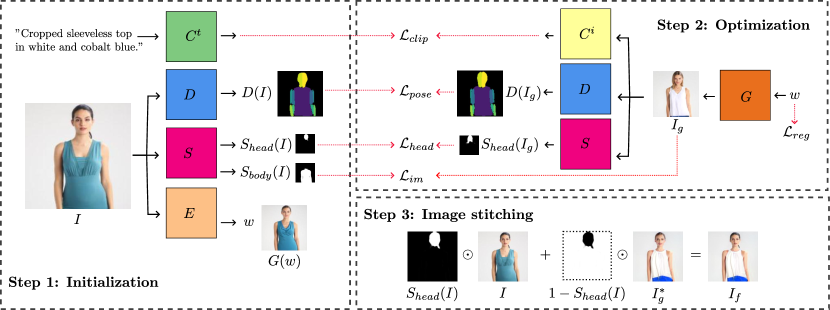
- 초기화, 제약된 GAN 반전, 그리고 이미지 스티칭의 세 단계 파이프라인을 사용한다.
- 편집 백본으로 사전 학습된 StyleGAN2 생성기를 사용한다.
- 텍스트 설명과 편집된 이미지를 맞추기 위해 CLIP 기반 의미 손실을 사용한다.
- 자세 보존을 위해 DensePose와 영역 인식 편집을 위한 분할 모델을 도입한다.
- 공간 간 분포 드리프트를 줄이기 위해 W+ 공간의 확장 잠재 코드를 정규화한다.
- 정체성을 보존하고 인공물을 최소화하기 위해 편집된 영역을 원본 이미지와 스티칭한다.

실험 결과
연구 질문
- RQ1자연어 설명만으로 자세와 신원을 보존하면서도 현실적인 패션 이미지 편집이 가능할까?
- RQ2CLIP 기반 의미론, 자세 제약, 영역 인식 손실이 일반 GAN 편집에 비해 텍스트 주도 편집의 우수성을 보일까?
- RQ3스타일GAN 기반 패션 편집에서 잠재 코드 정규화가 현실감과 편집의 일관성을 향상시키는가?
- RQ4VITON 및 Fashion-Gen 데이터셋의 실제 패션 이미지와 텍스트 설명을 결합했을 때 FICE의 성능은 어떤가?
주요 결과
- FICE는 자세와 신원을 보존하면서 매우 현실적인 패션 편집을 생성한다.
- FICE는 질적/양적 평가에서 경쟁 텍스트 기반 편집 방식보다 우수하다.
- CLIP 의미론, 자세 보존, 이미지 영역 손실의 조합이 그럴듯한 의상 통합을 이끈다.
- 잠재 코드 정규화는 확장된 W+ 코드를 원래 잠재 공간과 정렬시켜 이미지 현실감을 유지하는 데 도움이 된다.
- 이미지 스티칭은 경계 영역의 충실도를 더욱 개선하고 인공물을 줄인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.