[논문 리뷰] Finding Inductive Loop Invariants using Large Language Models
본 논문은 대형 언어 모델(LLMs)을 이용해 C 프로그램의 귀납 루프 불변식을 생성하고, LLM 출력과 기호적 검증 도구를 결합해 Hoare 삼중식을 검증하며, 많은 경우 기호적 기준선 대비 검증 성능이 향상됨을 보여준다.
Loop invariants are fundamental to reasoning about programs with loops. They establish properties about a given loop's behavior. When they additionally are inductive, they become useful for the task of formal verification that seeks to establish strong mathematical guarantees about program's runtime behavior. The inductiveness ensures that the invariants can be checked locally without consulting the entire program, thus are indispensable artifacts in a formal proof of correctness. Finding inductive loop invariants is an undecidable problem, and despite a long history of research towards practical solutions, it remains far from a solved problem. This paper investigates the capabilities of the Large Language Models (LLMs) in offering a new solution towards this old, yet important problem. To that end, we first curate a dataset of verification problems on programs with loops. Next, we design a prompt for exploiting LLMs, obtaining inductive loop invariants, that are checked for correctness using sound symbolic tools. Finally, we explore the effectiveness of using an efficient combination of a symbolic tool and an LLM on our dataset and compare it against a purely symbolic baseline. Our results demonstrate that LLMs can help improve the state-of-the-art in automated program verification.
연구 동기 및 목표
- LLMs에 의한 불변식 생성을 연구하기 위해 루프가 있는 C 프로그램의 검증 문제 데이터셋을 구성한다.
- 루프 불변식을 생성하도록 LLM에 프롬프트를 제공하고, 기호적 검증기로 유효성을 검증하는 도구 체인을 개발한다.
- 데이터셋에 대해 서로 다른 LLM과 하이브리드 LLM-기호적 접근법을 기호적 기준선과 비교 평가한다.
- LLM의 부정확성을 허용하면서도 귀납성을 보장하는 수리(repair) 기능이 포함된 파이프라인을 제안하고 평가한다.
제안 방법
- LLM(L)과 오라클/기호적 검증자(O)로 구성된 두 구성요소 도구 체인을 구축한다.
- 프롬프트 M과 대상 프로그램 P를 사용해 L을 통해 후보 불변식 I를 생성한다.
- P에 I를 A(P,I)로 주석화하고 O로 귀납성을 검증한다.
- Loopy를 적용해 완성에서 I를 누적하고, 이어서 Houdini를 사용해 귀납적 부분집합을 추출하거나, I를 개선하기 위해 Repair를 사용한다.
- Houdini는 비귀납적이거나 구문적으로 유효하지 않은 후보들을 가지치고, 귀납적인 부분집합을 찾아낸다.
- Repair는 오류 정보를 바탕으로 반복적으로 L을 재프롬프트하여 불변식을 수정하고 O로 재검증한다.
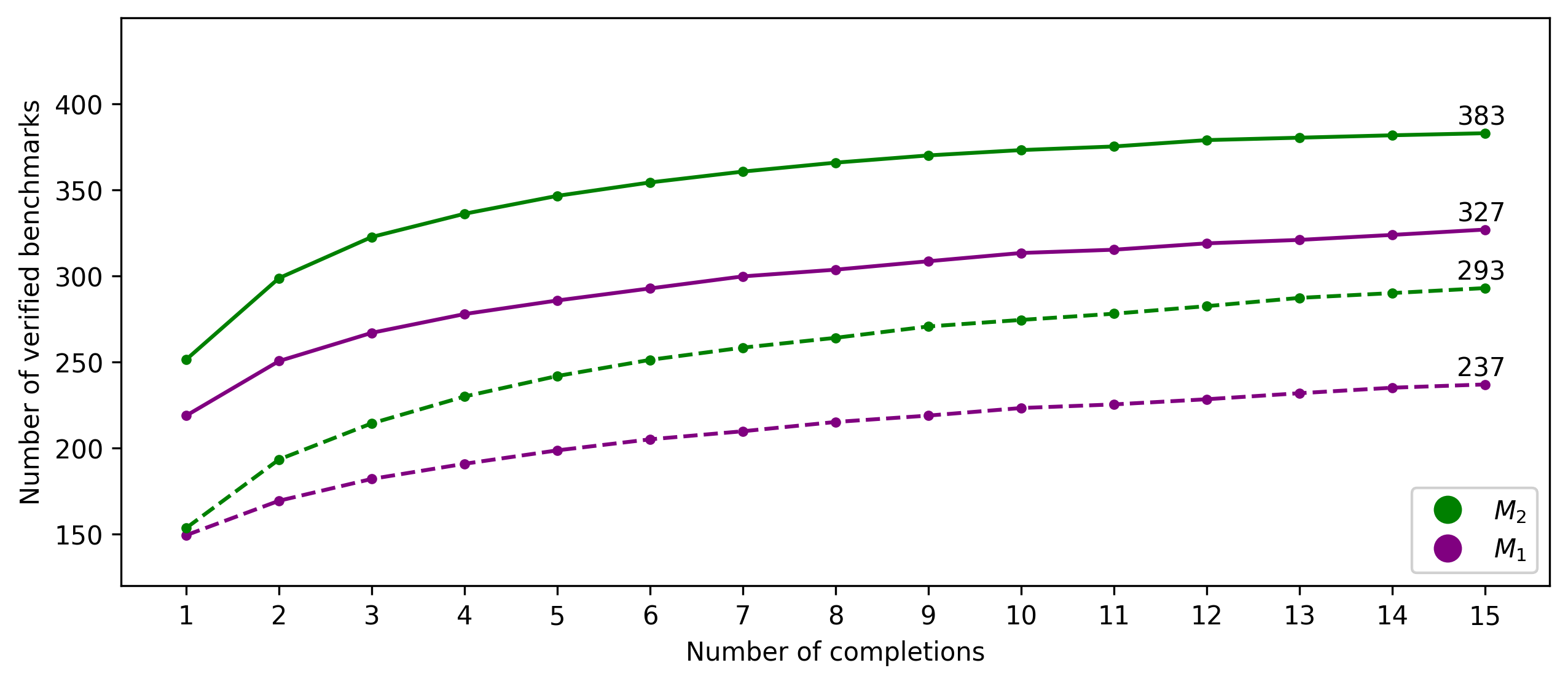
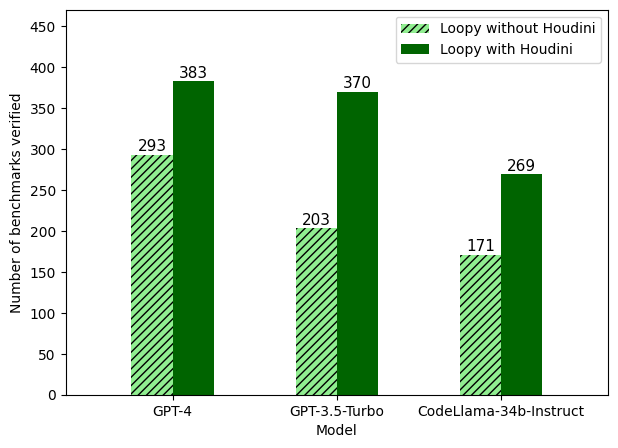
실험 결과
연구 질문
- RQ1RQ1 LLM이 C 프로그램에 대한 올바른 루프 불변식 집합을 생성하는 빈도는 어느 정도인가?
- RQ2RQ2 LLM이 C 프로그램의 검증에 필요한 올바른 루프 불변식 집합의 요소를 생성하는 빈도는 어느 정도인가?
- RQ3RQ3 서로 다른 기초 모델들이 귀납 불변식 발견 능력에서 어떻게 비교되는가?
- RQ4RQ4 오라클의 오류 메시지를 사용해 LLM이 잘못된 불변식을 얼마나 자주 수정할 수 있는가?
- RQ5RQ5 LLM이 올바른 불변식을 생성하지 못하는 프로그램의 특징은 무엇인가?
- RQ6RQ6 Loopy의 성능이 최첨단 기호적 검증기와 어떻게 비교되는가?
주요 결과
- Loopy의 성공은 더 많은 완성에 따라 증가하며, 약 8개의 완성 이후 수익이 감소한다.
- 프롬프트에 힌트를 포함하는(M2)이 간단한 프롬프트(M1) 대비 성공률을 약 23% 향상시킨다.
- Houdini는 LLM이 생성한 부분 불변식을 활용하여 성능을 크게 향상시킨다.
- GPT-4가 일반적으로 다른 LLM보다 우수하지만, Houdini가 다른 모델의 격차를 좁히도록 돕고, 여러 LLM를 사용하는 것이 유익할 수 있다.
- Repair는 검증 도달 범위를 더 확장해, 보고된 설정에서 Houdini만 사용했을 때의 383개를 넘겨 398개 벤치마크를 해결한다.
- 상징적 기준선 Ultimate와 비교할 때 Loopy는 Ultimate이 해결하지 못하는 일부 벤치마크를 해결하고, 전체적으로는 Ultimate이 더 많이 해결한다(469 벤치마크 중 430 대 398).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.