[논문 리뷰] Foundation Models for Biomedical Image Segmentation: A Survey
이 설문은 Segment Anything Model (SAM) 및 그 의료 영상 세분화 적응을 SAM 발행 직후의 첫 여섯 달 동안 분석하여 제로샷 성능, 도메인 특화 튜닝, 3D 확장 및 지식 증류를 33개의 공개 데이터세트에 걸쳐 상세히 다룹니다.
Recent advancements in biomedical image analysis have been significantly driven by the Segment Anything Model (SAM). This transformative technology, originally developed for general-purpose computer vision, has found rapid application in medical image processing. Within the last year, marked by over 100 publications, SAM has demonstrated its prowess in zero-shot learning adaptations for medical imaging. The fundamental premise of SAM lies in its capability to segment or identify objects in images without prior knowledge of the object type or imaging modality. This approach aligns well with tasks achievable by the human visual system, though its application in non-biological vision contexts remains more theoretically challenging. A notable feature of SAM is its ability to adjust segmentation according to a specified resolution scale or area of interest, akin to semantic priming. This adaptability has spurred a wave of creativity and innovation in applying SAM to medical imaging. Our review focuses on the period from April 1, 2023, to September 30, 2023, a critical first six months post-initial publication. We examine the adaptations and integrations of SAM necessary to address longstanding clinical challenges, particularly in the context of 33 open datasets covered in our analysis. While SAM approaches or achieves state-of-the-art performance in numerous applications, it falls short in certain areas, such as segmentation of the carotid artery, adrenal glands, optic nerve, and mandible bone. Our survey delves into the innovative techniques where SAM's foundational approach excels and explores the core concepts in translating and applying these models effectively in diverse medical imaging scenarios.
연구 동기 및 목표
- SAM이 도메인 특화 학습 없이 의료 영상에 일반화되는 방식을 평가합니다.
- SAM을 의료 과제에 맞게 조정하기 위한 도메인 특화 튜닝 기술을 조사합니다.
- 의료 데이터의 체적 데이터에 대해 SAM의 3D 확장 및 다차원 적응을 검토합니다.
- SAM 출력물을 활용한 작업 특화 모델을 위한 지식 증류 전략을 탐구합니다.
- SAM이 성공하거나 부족한 clinical한 도전과 데이터셋을 식별합니다.
제안 방법
- SAM 적응을 네 가지 주요 방법론으로 리뷰하고 분류합니다: 제로샷 평가, 어댑터/프로젝션/전체 튜닝, 3D 확장, 그리고 지식 증류.
- SAM 아키텍처를 설명합니다: 이미지 인코더 (MAE/ViT), 프롬프트 인코더, 경량 마스크 디코더.
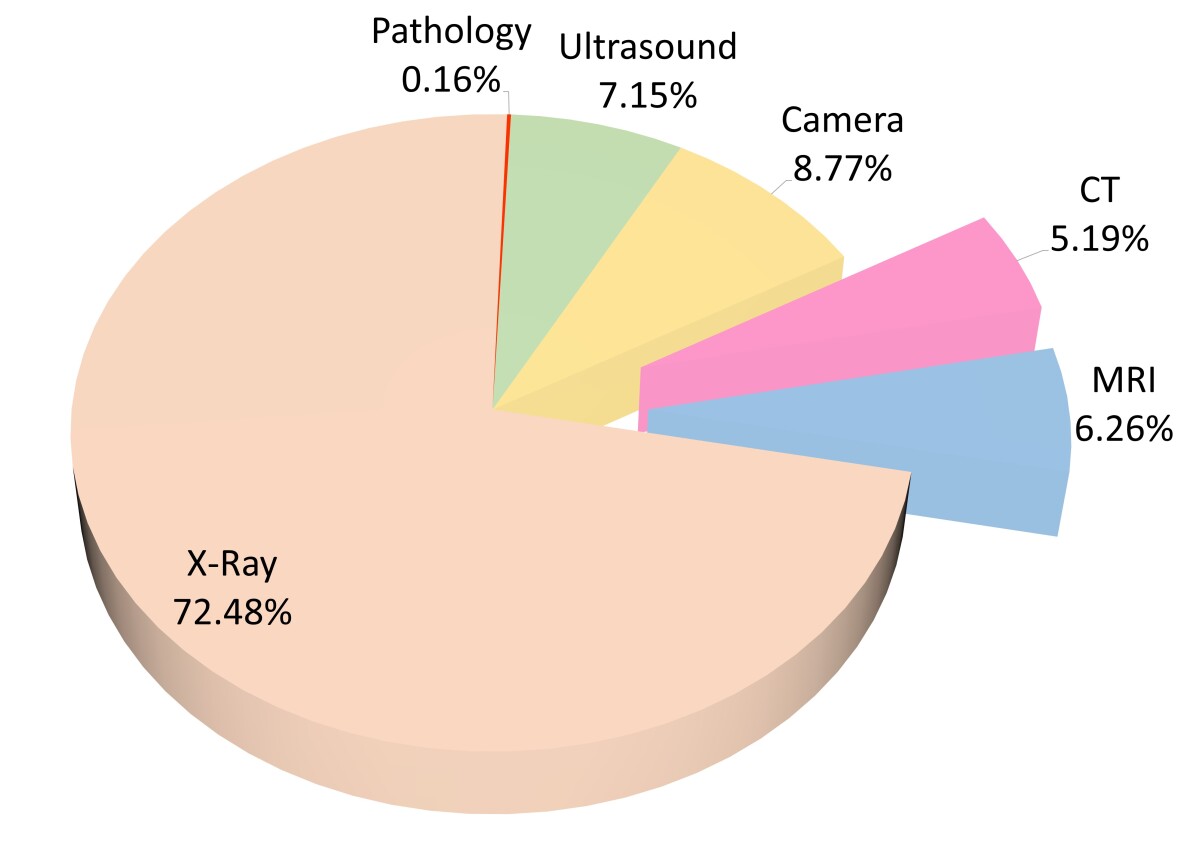
- 다양한 모달리티와 타깃에 걸친 33개의 공개 의료 영상 데이터세트를 수집하고 분석합니다.
- 2D 대 3D 처리, 2.5D 접근법 및 의료 데이터의 체적 전략을 포함하여 2D 대 3D 처리 방식을 논의합니다.
- 의료 SAM 연구의 초기 단계에서 관찰된 성능 경향과 한계점을 요약합니다.
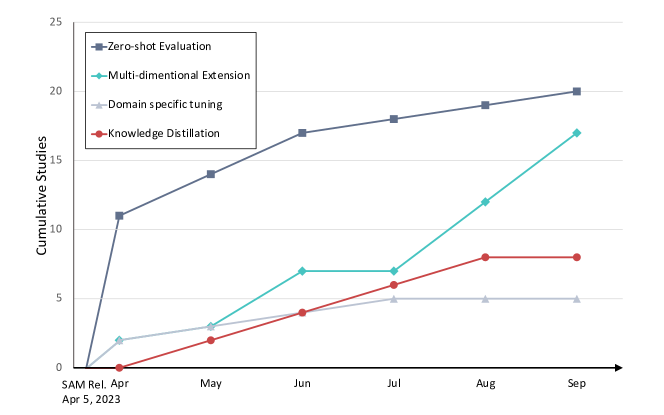
실험 결과
연구 질문
- RQ1다양한 데이터셋에서 제로샷 의료 영상 세분화에서 SAM의 성능은 어느 정도인가?
- RQ2도메인 특화 튜닝 전략(프로젝션, 어댑터, 전체 튜닝)이 자연 이미지에서 의료 영상으로 SAM을 얼마나 잘 연결하는가?
- RQ3SAM의 2D 프레임워크에서 3D 의료 영상 데이터는 어떻게 다루어지며, 제안된 확장은 무엇인가?
- RQ4지식 증류가 SAM의 능력을 작업 특화 의료 모델로 변환하는 데 어떤 역할을 하는가?
- RQ5초기 공개 데이터셋을 바탕으로 SAM이 뛰어난 해부학적 표적 및 모달리티는 무엇이며, 어디에서 어려움을 겪는가?
주요 결과
- SAM은 다양한 의료 세분화 작업에서 종종 최첨단 또는 경쟁력 있는 결과를 달성하지만, 경동맥, 부신, 시신경 및 하악골과 같은 구조에 대해 격차가 있다.
- 도메인 특화 튜닝(어댑터 및 전체 튜닝)과 3D 확장이 SAM의 의료 성능을 개선하는 활발한 연구 영역이다.
- 3D 의료 데이터는 2D 슬라이스로 처리되거나 SAM의 2D 설계에 맞추기 위해 2.5D/체적 접근으로 처리된다.
- SAM 출력물을 의사 라벨처럼 사용하는 지식 증류는 반지도 학습 설정에서 다운스트림 작업 모델을 향상시킬 수 있다.
- 7개 모달리티와 17개의 해부학을 망라하는 33개의 공개 데이터세트가 존재하며, 이는 SAM의 광범위하지만 불균형한 적용성을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.