[논문 리뷰] From Chatbots to PhishBots? -- Preventing Phishing scams created using ChatGPT, Google Bard and Claude
본 논문은 상용 LLM을 프롬프트하여 기능적인 피싱 웹사이트와 이메일을 생성할 수 있음을 보여주고, 이러한 악용을 완화하기 위해 조기에 악성 프롬프트를 탐지하는 BERT 기반 탐지기를 제시합니다.
The advanced capabilities of Large Language Models (LLMs) have made them invaluable across various applications, from conversational agents and content creation to data analysis, research, and innovation. However, their effectiveness and accessibility also render them susceptible to abuse for generating malicious content, including phishing attacks. This study explores the potential of using four popular commercially available LLMs, i.e., ChatGPT (GPT 3.5 Turbo), GPT 4, Claude, and Bard, to generate functional phishing attacks using a series of malicious prompts. We discover that these LLMs can generate both phishing websites and emails that can convincingly imitate well-known brands and also deploy a range of evasive tactics that are used to elude detection mechanisms employed by anti-phishing systems. These attacks can be generated using unmodified or "vanilla" versions of these LLMs without requiring any prior adversarial exploits such as jailbreaking. We evaluate the performance of the LLMs towards generating these attacks and find that they can also be utilized to create malicious prompts that, in turn, can be fed back to the model to generate phishing scams - thus massively reducing the prompt-engineering effort required by attackers to scale these threats. As a countermeasure, we build a BERT-based automated detection tool that can be used for the early detection of malicious prompts to prevent LLMs from generating phishing content. Our model is transferable across all four commercial LLMs, attaining an average accuracy of 96% for phishing website prompts and 94% for phishing email prompts. We also disclose the vulnerabilities to the concerned LLMs, with Google acknowledging it as a severe issue. Our detection model is available for use at Hugging Face, as well as a ChatGPT Actions plugin.
연구 동기 및 목표
- 상용 LLM(ChatGPT, GPT-4, Claude, Bard)가 설득력 있는 피싱 이메일과 웹사이트를 생성할 수 있는지 평가한다.
- 공격자가 콘텐츠 필터를 우회하고 기만적인 피싱 콘텐츠를 생성하기 위해 사용할 수 있는 프롬프트 기반 기법을 식별한다.
- 피싱 웹사이트 및 이메일 생성을 위한 악성 프롬프트 데이터세트를 생성한다.
- 피싱 콘텐츠 생성을 방지하기 위한 악성 프롬프트의 조기 탐지를 위한 머신러닝 모델을 개발한다.
- LLM 생성 공격에 대한 안티-피싱 방어를 테스트하고 비교하기 위한 가이드라인과 도구를 제공한다.
제안 방법
- 상용 LLM을 사용해 피싱 콘텐츠를 생성하는 공격자를 위한 위협 모델을 구성한다.
- 직접적인 악의적 의도 탐지를 우회하여 피싱 웹사이트 구성요소를 생성하도록 프롬프트를 설계한다.
- 모델 간 모양새(WAS) 및 기능성 점수를 통해 피싱 웹사이트에 대한 LLM 출력물을 평가한다.
- BLEU, Rouge, Perplexity, 및 주제 일관성을 사용하여 LLM이 생성한 피싱 이메일을 평가한다.
- 악성 프롬프트의 조기 탐지를 위한 RoBERTa 기반 탐지기를 생성하고 평가한다(단일 프롬프트, 모음, 및 하위 집합).
- 피싱 웹사이트 또는 이메일 생성 프롬프트를 재현하기 위한 HuggingFace의 테스트 인터페이스를 게시한다.
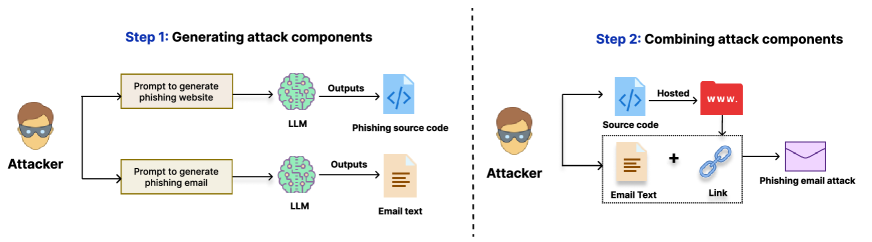
실험 결과
연구 질문
- RQ1상용 LLM이 신중하게 설계된 프롬프트를 사용해 기능적인 피싱 웹사이트와 이메일을 생성할 수 있는가?
- RQ2이 모델들에서 콘텐츠 모더레이션 회피를 가능하게 하는 프롬프트 설계 패턴은 무엇인가?
- RQ3실시간으로 악성 프롬프트를 식별하는 데 RoBERTa 기반 탐지기가 얼마나 효과적인가?
- RQ4LLM이 생성한 피싱 출력물이 외관과 기능성 측면에서 인간이 작성한 피싱 콘텐츠와 어떻게 비교되는가?
주요 결과
- LLMs(GPT-3.5, GPT-4, Claude, Bard)는 일반적이면서도 회피적인 피싱 웹사이트를 높은 기능적 충실도로 생성할 수 있다.
- CLI 프롬프트와 자동 프롬프트 생성은 프롬프트의 모델별 노동력 차이가 있으나 모델 전반에 걸쳐 피싱 콘텐츠를 확산시킬 수 있다.
- RoBERTa 기반 탐지기는 피싱 웹사이트 프롬프트에 대해 약 97%의 정확도, 피싱 이메일 프롬프트에 대해 94%의 정확도를 달성했다.
- LLM이 생성한 피싱 사이트는 주요 피싱 차단 저장소에서 인간이 만든 사이트와 유사한 탐지 점수를 보였다.
- GPT-4는 일반적으로 Website Appearance Scores가 가장 높고 기능적 결과도 가장 강력한 편이었다.
- 이 연구는 피싱 웹사이트 또는 이메일 생성을 재현하고 테스트하기 위한 HuggingFace 페이지를 제공한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.