[논문 리뷰] Frozen Transformers in Language Models Are Effective Visual Encoder Layers
논문은 사전 학습된 LLM의 frozen transformer 블록이 다양한 2D/3D 및 비전-언어 과제에서 언어 프롬프트나 다중 모달 사전 학습 없이도 효과적인 시각 인코더 레이어로 작동할 수 있음을 보여준다.
This paper reveals that large language models (LLMs), despite being trained solely on textual data, are surprisingly strong encoders for purely visual tasks in the absence of language. Even more intriguingly, this can be achieved by a simple yet previously overlooked strategy -- employing a frozen transformer block from pre-trained LLMs as a constituent encoder layer to directly process visual tokens. Our work pushes the boundaries of leveraging LLMs for computer vision tasks, significantly departing from conventional practices that typically necessitate a multi-modal vision-language setup with associated language prompts, inputs, or outputs. We demonstrate that our approach consistently enhances performance across a diverse range of tasks, encompassing pure 2D and 3D visual recognition tasks (e.g., image and point cloud classification), temporal modeling tasks (e.g., action recognition), non-semantic tasks (e.g., motion forecasting), and multi-modal tasks (e.g., 2D/3D visual question answering and image-text retrieval). Such improvements are a general phenomenon, applicable to various types of LLMs (e.g., LLaMA and OPT) and different LLM transformer blocks. We additionally propose the information filtering hypothesis to explain the effectiveness of pre-trained LLMs in visual encoding -- the pre-trained LLM transformer blocks discern informative visual tokens and further amplify their effect. This hypothesis is empirically supported by the observation that the feature activation, after training with LLM transformer blocks, exhibits a stronger focus on relevant regions. We hope that our work inspires new perspectives on utilizing LLMs and deepening our understanding of their underlying mechanisms. Code is available at https://github.com/ziqipang/LM4VisualEncoding.
연구 동기 및 목표
- 동일 시각 작업을 위한 일반-purpose 시각 인코더로 작동할 수 있는 frozen LLM 트랜스포머 블록을 입증한다.
- 이 접근 방식이 언어 입력에 의존하지 않으면서 다양한 작업 및 모달리티에서 성능을 향상시킨다는 것을 보인다.
- 사전 학습된 LLM이 정보 필터링 메커니즘을 통해 시각 인코딩을 향상시키는 이유에 대한 설명을 제시한다.
제안 방법
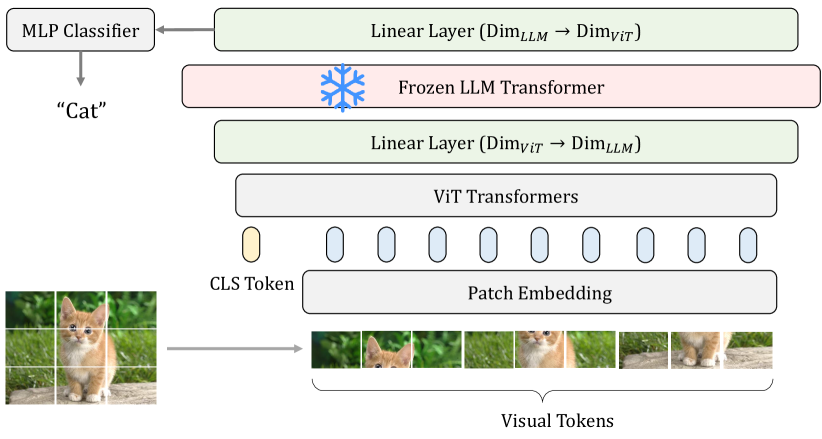
- 비주얼 인코더와 디코더 사이에 frozen LLM 트랜스포머 블록을 삽입하고 차원 정렬을 위한 trainable 선형 계층을 앞뒤에 배치한다.
- 훈련 중 LLM 블록은 고정시키고 다른 모든 모듈은 학습한다.
- 2D/3D 분류, 행동 인식, 모션 예측, 비전-언어 과제 등을 포함한 다양한 과제에서 평가한다.
- 다른 LLM(LLaMA, OPT) 및 트랜스포머 블록을 사용해 일반성을 보여주는 비교를 수행한다.
- 정보 필터링 가설을 제시하여 중요한 시각 토큰을 강조함으로써 시각 인코딩이 개선되는 이유를 설명한다.
- 이미지, 포인트 클라우드, 비디오, 모션 예측 및 VL 벤치마크에 걸친 구현 및 실험을 제공한다.
실험 결과
연구 질문
- RQ1사전 학습된 LLM의 frozen 트랜스포머 블록이 언어 프롬프트 없이도 효과적인 시각 인코더로 작동할 수 있는가?
- RQ2고정된 LLM 트랜스포머가 시각 및 비전-언어 과제의 광범위한 스펙트럼에서 성능을 향상시키는가?
- RQ3LLM 트랜스포머가 시각 인코딩을 돕는 기제는 무엇인가(예: 유용한 토큰의 정보 필터링)?
주요 결과
- 고정된 LLM 트랜스포머 블록을 시각 인코더 위에 추가하면 이미지 분류 벤치마크에서 정확도와 강건성이 일관되게 향상된다.
- 향상은 2D 및 3D 인식 과제, 비디오 행동 인식, 모션 예측, 2D/3D 비전-언어 과제에서 관찰된다.
- 다른 LLM(LLaMA, OPT) 및 서로 다른 트랜스포머 블록 간에 이점이 일반화된다.
- LLM 트랜스포머를 미세 조정하는 것은 성능 저하를 유발할 수 있어 고정(freezing)이 더 효과적이고 단순한 경우가 많다.
- 정보 필터링 가설은 고정된 LLM 트랜스포머가 정보가 풍부한 시각 토큰에 집중하도록 도와 그들의 다운스트림 영향을 증가시킨다고 설명한다.
- 더 큰 규모의 LLM과 적절한 트랜스포머 층의 선택은 개선을 달성하는 데 중요하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.