[논문 리뷰] FwdLLM: Efficient FedLLM using Forward Gradient
FwdLLM은 BP-free training을 forward gradients와 PEFT와 함께 도입하여 모바일 기기에서 LLM의 실용적인 federated fine-tuning을 가능하게 하며, 대규모 속도 개선과 메모리 감소를 달성합니다.
Large Language Models (LLMs) are transforming the landscape of mobile intelligence. Federated Learning (FL), a method to preserve user data privacy, is often employed in fine-tuning LLMs to downstream mobile tasks, an approach known as FedLLM. Though recent efforts have addressed the network issue induced by the vast model size, they have not practically mitigated vital challenges concerning integration with mobile devices, such as significant memory consumption and sluggish model convergence. In response to these challenges, this work introduces FwdLLM, an innovative FL protocol designed to enhance the FedLLM efficiency. The key idea of FwdLLM to employ backpropagation (BP)-free training methods, requiring devices only to execute ``perturbed inferences''. Consequently, FwdLLM delivers way better memory efficiency and time efficiency (expedited by mobile NPUs and an expanded array of participant devices). FwdLLM centers around three key designs: (1) it combines BP-free training with parameter-efficient training methods, an essential way to scale the approach to the LLM era; (2) it systematically and adaptively allocates computational loads across devices, striking a careful balance between convergence speed and accuracy; (3) it discriminatively samples perturbed predictions that are more valuable to model convergence. Comprehensive experiments with five LLMs and three NLP tasks illustrate FwdLLM's significant advantages over conventional methods, including up to three orders of magnitude faster convergence and a 14.6x reduction in memory footprint. Uniquely, FwdLLM paves the way for federated learning of billion-parameter LLMs such as LLaMA on COTS mobile devices -- a feat previously unattained.
연구 동기 및 목표
- 메모리, 가속기, 확장성 제약으로 인한 모바일 기기에서 FedLLM의 실용성 문제를 제기한다.
- perturbed inferences를 통한 BP-free training을 제안하여 온-device 메모리 및 계산량을 감소시킨다.
- 대형 LLM으로 확장하기 위해 forward-gradient training과 PEFT 방법을 통합한다.
- 수렴 속도 향상을 위한 적응형 perturbation pacing과 discriminative perturbation sampling을 개발한다.
- 여러 모델과 작업에서 온-디바이스 실현 가능성을 입증하고 성능 개선을 정량화한다.
제안 방법
- forward gradient를 진짜 gradient의 무편향 추정량으로 사용하여 BP-free training이 가능하도록 한다.
- BP-free training을 LoRa 및 Adapter와 같은 parameter-efficient fine-tuning (PEFT) 방법과 결합한다.
- forward-gradient 분산이 임계값 아래일 때만 gradient를 모으는 분산 제어 페이싱 메커니즘을 구현한다.
- 진짜 gradient와 높은 코사인 유사도를 갖는 perturbation을 판별적으로 샘플링하고, 낮은 가치를 가진 perturbation을 필터링한다.
- gradient 유사도에 따라 모델별로 적합한 PEFT 방법을 선택하기 위해 자동 오프라인 PEFT 프로파일러를 활용한다.
- perturbations 및 기기 참여를 적응적으로 관리하기 위해 클라우드-디바이스 스케줄링 워크플로를 활용한다.
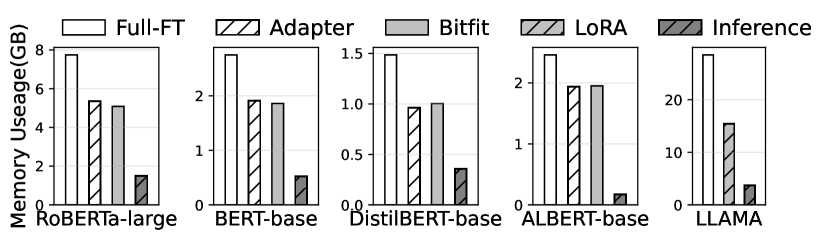
실험 결과
연구 질문
- RQ1BP-free forward-gradient training과 PEFT가 모바일 기기에서 실용적 FedLLM을 가능하게 할 수 있는가?
- RQ2수렴 속도와 계산 비용의 균형을 맞추기 위해 perturbation pacing 및 sampling을 어떻게 자동화할 수 있는가?
- RQ3전체 모델 파인튜닝 및 PEFT 베이스라인에 비해 어떤 메모리, 시간, 정확도 개선이 달성 가능한가?
- RQ4COTS 모바일 하드웨어에서 federate-benchmark billion-parameter LLMs(예: LLaMA)가 가능한가?
주요 결과
- 전체 모델 파인튜닝에 비해 최대 217.3× 빠른 수렴.
- 강력한 베이스라인 대비 메모리 사용량이 최대 14.6× 감소.
- 설명된 설정별로 온디바이스 학습 시간이 10.9–97.9시간에서 0.2–0.8시간으로 감소.
- BP-free + PEFT를 적용한 평균 10.6×의 속도향상, 범위 2.0×–93.4×.
- INT4로 양자화했을 때 소비자용 스마트폰에서 7B LLaMA 모델의 파인튜닝을 10분 이내에 시연.
- Discriminative perturbation sampling과 variance-controlled pacing이 수렴 효율성에 크게 영향을 미치는 것으로 나타났다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.