[논문 리뷰] GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
GaLore는 메모리 효율적인 그래디언트 저랭크 프로젝션으로 전체 매개변수 모델을 학습시키며, LLM의 사전 학습(pre-training) 및 미세 조정(fine-tuning) 동안 성능을 유지하면서 옵티마이저 상태 메모리 사용을 크게 감소시킵니다.
Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-rank adaptation (LoRA), add a trainable low-rank matrix to the frozen pre-trained weight in each layer, reducing trainable parameters and optimizer states. However, such approaches typically underperform training with full-rank weights in both pre-training and fine-tuning stages since they limit the parameter search to a low-rank subspace and alter the training dynamics, and further, may require full-rank warm start. In this work, we propose Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods such as LoRA. Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
연구 동기 및 목표
- 대형 언어 모델의 사전 학습(pre-training)과 미세 조정(fine-tuning)에서의 메모리 병목 현상을 동기 부여한다.
- 전체 매개변수 학습을 제약하지 않으면서 옵티마이저 메모리를 줄이기 위한 그래디언트 기반 저랭크 프로젝션을 제안한다.
- LLaMA-7B 사전 학습과 RoBERTa-GLE 미세 조정에서 메모리 및 성능 이점을 시연한다.
- 기존 옵티마이저 및 메모리 절감 기술과의 호환성을 보인다.
제안 방법
- 훈련 중 가중치 그래디언트가 저랭크가 된다는 관찰을 활용한다(Lemma 3.1 및 관련 내용).
- 그래디언트 업데이트를 위해 P^T G Q를 형성하기 위해 R^{m×r}의 P와 R^{n×r}의 Q라는 두 개의 프로젝션 행렬을 도입한다.
- 가중치를 tilde{G}_t = P_t ρ_t(P_t^T G_t Q_t) Q_t^T로 업데이트하여 전체 매개변수 학습을 보존한다.
- 일정 간격(T)마다 SVD 기반 프로젝션으로 P와 Q를 재초기화하여 부분공간 전환(subspace switching)을 허용한다.
- 고정되거나 주기적으로 업데이트된 프로젝션 하에서 GaLore가 수렴함을 보이는 수렴 분석(Theorem 3.6)을 제공한다.
- Adam, 8-bit Adam, Adafactor 및 레이어별 가중치 업데이트와의 호환성을 보인다.
- 메모리 효율 옵티마이저와 결합하여 메모리를 추가로 줄인다.
실험 결과
연구 질문
- RQ1LLM 훈련 중 그래디언트 행렬을 효과적으로 저랭크로 간주하여 성능을 저하시키지 않으면서 메모리를 줄일 수 있는가?
- RQ2GaLore가 LoRA 기반 방법과 비교하거나 우수한 메모리 절감을 달성하면서 전체 매개변수 학습을 보존하는가?
- RQ3부분공간 전환 빈도와 랭크가 수렴 및 최종 모델 품질에 어떤 영향을 미치는가?
- RQ4GaLore가 일반적인 메모리 효율 옵티마이저 및 학습 체계(사전 학습 및 미세 조정)에 호환되는가?
주요 결과
| 지표 | GaLore | LoRA |
|---|---|---|
| Weights | mn | mn+mr+nr |
| Optim States | mr+2nr | 2mr+2nr |
| Multi-Subspace | ✓ | ✗ |
| Pre-Training | ✓ | ✗ |
| Fine-Tuning | ✓ | ✓ |
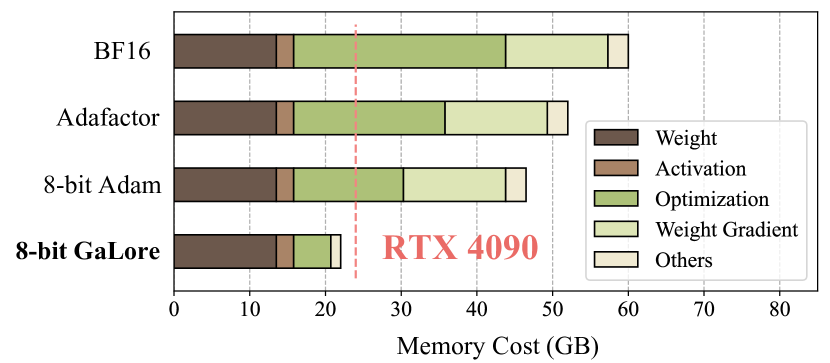
- GaLore는 8-bit 옵티마이저 사용 시 BF16 기준으로 옵티마이저 메모리를 최대 65.5% 감소시키고 전체 학습 메모리를 최대 63.3%까지 줄인다.
- 19.7B 토큰의 C4에서 LLaMA 7B 사전 학습 동안, 8-bit GaLore는 전체 랭크 학습과 비교할 만한 perplexity를 더 적은 메모리로 달성한다; 어떤 설정에서는 더 높은 r에서 전체 랭크 성능과 동일하거나 약간 상회한다.
- GaLore는 소비자 GPU(예: RTX 4090)에서 24GB 메모리로 7B 모델의 사전 학습을 가능하게 하며 모델 병렬화, 체크포인팅, 오프로딩 없이도 가능하다(Activation checkpointing으로 배치 사이즈를 더 확장할 수 있다).
- GLUE에서 RoBERTa-Base 미세 조정에서 GaLore(랭크 4)는 평균 GLUE 점수에서 LoRA를 상회하며(85.89 대 85.61) 비슷하거나 더 작은 메모리 사용량으로 이점을 보인다; 랭크 8의 GaLore도 경쟁력 있는 이점을 제공한다.
- GaLore는 여전히 옵티마이저에 구애받지 않으며 AdamW, 8-bit Adam, Adafactor와 함께 작동하고 추가 메모리 절감을 위한 레이어별 가중치 업데이트를 지원한다.
![Figure 2 : Learning through low-rank subspaces $\Delta W_{T_{1}}$ and $\Delta W_{T_{2}}$ using GaLore. For $t_{1}\in[0,T_{1}-1]$ , $W$ are updated by projected gradients $\tilde{G}_{t_{1}}$ in a subspace determined by fixed $P_{t_{1}}$ and $Q_{t_{1}}$ . After $T_{1}$ steps, the subspace is changed b](https://ar5iv.labs.arxiv.org/html/2403.03507/assets/x2.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.