[논문 리뷰] Gemini Goes to Med School: Exploring the Capabilities of Multimodal Large Language Models on Medical Challenge Problems & Hallucinations
이 논문은 Google Gemini를 오픈소스 및 상용 의료 LLM과 의료 추론, 환각 위험(Med-HALT), 및 의료 VQA에서 평가하고, MultiMedQA, Med-HALT, NEJM-VQA 벤치마크를 사용하며 프롬프트 전략과 평가 도구를 제공합니다. Gemini는 여러 의료 태스크에서 Med-PaLM 2 및 GPT-4보다 뒤처지는 반면, 프롬프팅 기술로 개선이 나타나는 주목할 만한 환각 위험이 존재합니다.
Large language models have the potential to be valuable in the healthcare industry, but it's crucial to verify their safety and effectiveness through rigorous evaluation. For this purpose, we comprehensively evaluated both open-source LLMs and Google's new multimodal LLM called Gemini across Medical reasoning, hallucination detection, and Medical Visual Question Answering tasks. While Gemini showed competence, it lagged behind state-of-the-art models like MedPaLM 2 and GPT-4 in diagnostic accuracy. Additionally, Gemini achieved an accuracy of 61.45\% on the medical VQA dataset, significantly lower than GPT-4V's score of 88\%. Our analysis revealed that Gemini is highly susceptible to hallucinations, overconfidence, and knowledge gaps, which indicate risks if deployed uncritically. We also performed a detailed analysis by medical subject and test type, providing actionable feedback for developers and clinicians. To mitigate risks, we applied prompting strategies that improved performance. Additionally, we facilitated future research and development by releasing a Python module for medical LLM evaluation and establishing a dedicated leaderboard on Hugging Face for medical domain LLMs. Python module can be found at https://github.com/promptslab/RosettaEval
연구 동기 및 목표
- Gemini의 텍스트 및 시각적 모듈에서 의료 추론 능력을 평가합니다.
- 의료 맥락에서 Gemini의 환각 경향과 안전성 위험을 정량화합니다.
- 의료 벤치마크에서 Gemini를 오픈소스 LLM 및 상용 모델과 비교합니다.
- 프롬프트 전략 및 모델 개선에 대한 실행 가능한 피드백을 제공합니다.
- 재현 가능한 연구를 촉진하기 위한 평가 도구 및 의료 도메인 리더보드를 릴리스합니다.
제안 방법
- Deterministic 설정(온도 0.0, top-p 1.0)으로 Gemini Pro 개발자 API를 통해 Gemini Pro를 평가합니다.
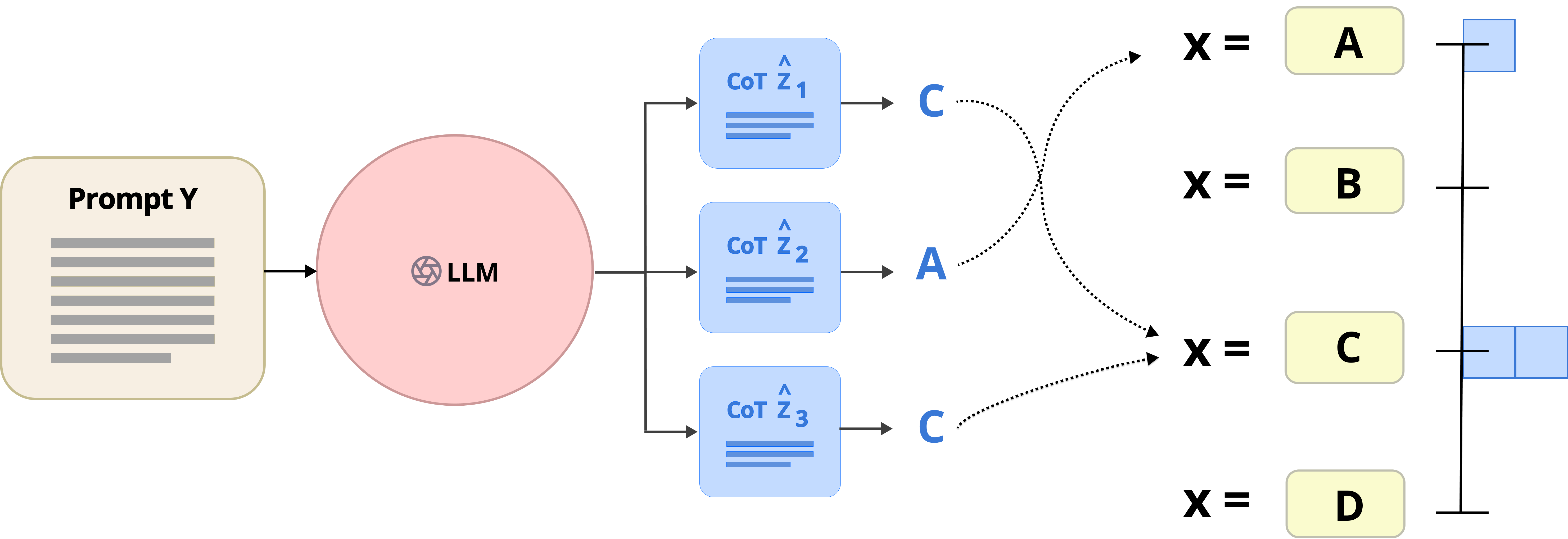
- 프롬프팅 기술(zero-shot, few-shot, chain-of-thought, self-consistency, 앙상블 정제)을 사용하여 MultiMedQA, Med-HALT, 및 Medical Visual Question Answering 벤치마크에서 벤치마크를 수행합니다.
- 오픈소스 LLM(Llama 계열, Mistral, Yi-34b, Qwen-72b 등) 및 폐쇄형 모델(MedPaLM, MedPaLM 2, GPT-4)과 비교합니다.
- MultiMedQA와 VQA 전반에서 정확도를 기본 지표로 사용합니다. Med-HALT 평가에는 Pointwise 점수를 사용합니다.
- 의료 LLM 평가를 위한 RosettaEval 파이썬 모듈과 의료 LLM용 Hugging Face 리더보드를 도입합니다.
실험 결과
연구 질문
- RQ1Gemini가 텍스트와 이미지에서 복잡한 의료 추론 문제를 얼마나 정확하게 해결할 수 있습니까?
- RQ2Gemini가 의료 응답에서 환각이나 과신을 보입니까?
- RQ3표준 벤치마크에서 Gemini의 성능은 오픈소스 및 상용 의료 LLM과 어떻게 비교됩니까?
- RQ4Gemini의 의료 추론을 개선하고 환각을 줄이는 프롬프트 전략은 무엇입니까?
- RQ5Gemini의 의료 지식 및 다중 모달 역량에서 도메인 특정 강점과 약점은 무엇입니까?
주요 결과
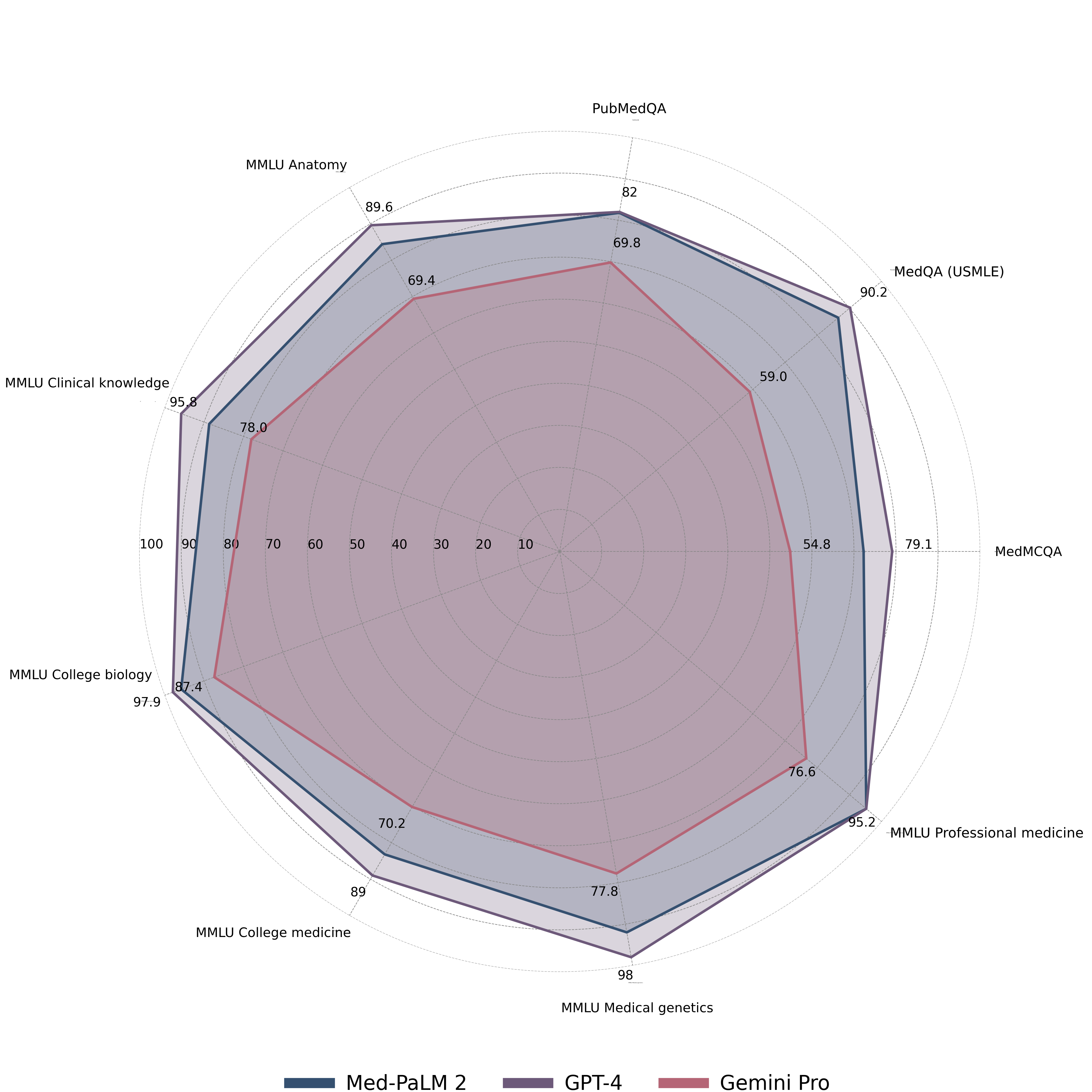
- Gemini Pro는 Med-PaLM 2 및 GPT-4와 비교했을 때 MultiMedQA 벤치마크에서 강력하나 최첨단은 아니며(예: MedQA USMLE 및 MedMCQA 결과가 논의됨).
- Med-HALT에서 Gemini는 추론 Fake에 대한 정확도는 높지만 과신 방지(Risk of Reasoning FCT)와 기억 기반 검색 과제(IR PubMedlink 작업)에서 취약합니다.
- 의료 VQA 정확도는 Gemini Pro에서 61.45%로 GPT-4V의 88%에 비해 크게 낮습니다.
- 주제별 분석에서 Gemini는 생물통계학, 역학, 세포생물학 및 특정 영역(예: 위장병학, 산부인과/부인과)에서 우수하지만 다른 의료 하위 분야 및 복잡한 추론 태스크에서는 저조합니다.
- Chain-of-Thought 및 Ensemble Refinement와 같은 프롬프트 전략이 특정 도메에서 성능을 향상시킬 수 있지만 데이터세트에 따라 효과가 다르게 나타납니다. 제로샷 및 파샷 프롬프트는 작업에 따라 서로 다른 이점을 보입니다.
- 저자는 RosettaEval의 Python 평가 모듈을 제공하고 재현 가능한 의료 LLM 연구를 지원하기 위한 Hugging Face 리더보드를 설정합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.