[논문 리뷰] Gemma: Open Models Based on Gemini Research and Technology
Gemma는 Gemini 기술로 구축된 두 가지 오픈 LLM(2B 및 7B)을 제공하며, 사전 학습된 및 미세 조정된 체크포인트를 가지고, 언어, 추론 및 안전성에 대한 광범위한 벤치마크에서 평가되었고, 오픈 추론 코드와 안전 도구와 함께 공개되었습니다.
This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
연구 동기 및 목표
- Gemma 연구에서 파생된 오픈형 고품질 언어 모델을 연구 및 개발을 위해 제공합니다.
- 언어 이해, 추론, 코딩 및 안전 벤치마크에서 성능 평가.
- 안전성, 기억화 및 책임 있는 배포 측면을 평가하여 오픈 모델 관행에 정보를 제공합니다.
- 광범위한 연구 및 실험을 가능하게 하는 사전 학습 및 지시-미세 조정 체크포인트 제공.
- 지원 도구 및 문서와 함께 책임 있는 오픈 가중치 공개를 촉진합니다.
제안 방법
- 컨텍스트 길이 8192 토큰의 트랜스포머 디코더 아키텍처.
- 두 가지 모델 규모: 2B(2048 차원, 18 계층) 및 7B(3072 차원, 28 계층).
- 개선 사항: 다중 쿼리 어텐션 또는 다중 헤드 어텐션, 로터리 포지션 임베딩(RoPE), GeGLU 활성화, RMSNorm.
- Pathways 스타일 샤딩과 2D 토루스 하드웨어를 사용한 TPUv5e에서 최대 6T 토큰으로 학습; 단일 컨트롤러 GPT-스타일 오케스트레이션(Jax, Pathways, GSPMD).
- 안전하지 않거나 품질이 낮은 콘텐츠를 줄이고 평가 세트의 누출을 방지하기 위한 데이터 필터링; 어휘 크기 256k; 2B는 2T 토큰으로 학습되고 7B는 6T 토큰으로 학습.
- 두 단계 미세 조정: 감독 학습 미세조정(SFT) 후 사람 피드백으로 강화학습(RLHF); 대화 제어를 위한 지시 형식 토큰.
실험 결과
연구 질문
- RQ1Gemma 모델이 유사한 규모의 오픈 모델과 자동화된 벤치마크 및 사람 평가 벤치마크에서 어떻게 성능을 보이는가?
- RQ2Gemma 모델의 안전성 및 기억화 프로파일은 민감한 정보를 노출하거나 기억할 위험을 포함하여 어떠한가?
- RQ3지시-미세 조정 체계(SFT, RLHF)가 다운스트림 성능 및 안전성에 미치는 영향은?
- RQ4오픈 가중치가 연구, 안전 연구 및 다운스트림 혁신에 어떻게 기여하는가?
- RQ5책임 있는 오픈 모델 공개를 위한 배포 및 거버넌스 메커니즘은 어떤 것이 효과적인가?
주요 결과
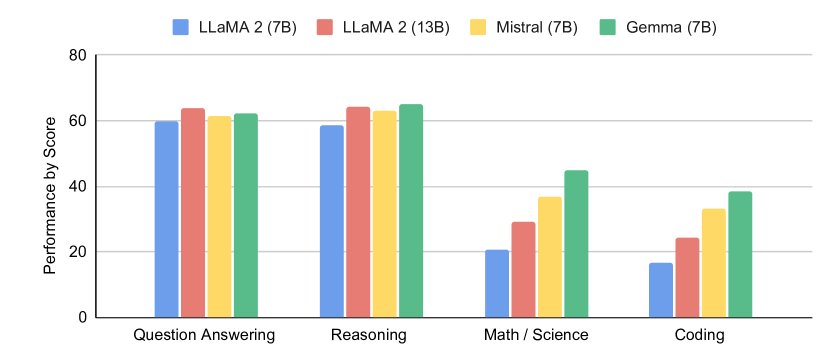
- Gemma 7B는 유사한 오픈 모델에 비해 강력한 성능을 달성하며, MMLU 벤치마크에서 여러 모델을 능가하고(64.3%), MBPP에서(44.4%)를 달성하였다.
- Mistral v0.2 7B Instruct에 대한 인간 평가에서 Gemma-7B IT는 지시 따르기 프롬프트에서 51.7%의 긍정적 승률, 안전 프롬프트에서 58%의 승률을 보였으며(신뢰 구간 제공).
- Gemma 모델은 수학 및 코딩 능력이 뛰어나 GSM8K, MATH, MBPP에서 많은 오픈 경쟁자들을 능가한다.
- 사전 학습 기억화는 낮고 PaLM 계열과 비슷하며 민감한 데이터 암시가 탐지되지 않았다; 근사 기억화는 더 높지만 여전히 예상 범위 내.
- 오픈 공개에는 사전 학습 및 미세 조정 체크포인트 모두 포함되며 연구 및 안전 분석을 용이하게 하는 오픈 소스 추론/서비스 코드베이스가 있다.
- Gemma는 안전 벤치마크, 레드팀핑, 모델 카드, 개발자를 위한 생성형 AI 책임 도구 세트를 통해 책임 있는 배포를 강조한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.