[논문 리뷰] Generative AI for Synthetic Data Generation: Methods, Challenges and the Future
이 논문은 거대하고 고정된 LLM이 작업-특정 합성 데이터를 어떻게 생성할 수 있는지 조사하고, 프롬프트 및 적응 방법을 검토하며, 데이터 품질을 평가하고, 응용 및 도전과제와 향후 방향에 대해 논의합니다.
The recent surge in research focused on generating synthetic data from large language models (LLMs), especially for scenarios with limited data availability, marks a notable shift in Generative Artificial Intelligence (AI). Their ability to perform comparably to real-world data positions this approach as a compelling solution to low-resource challenges. This paper delves into advanced technologies that leverage these gigantic LLMs for the generation of task-specific training data. We outline methodologies, evaluation techniques, and practical applications, discuss the current limitations, and suggest potential pathways for future research.
연구 동기 및 목표
- 데이터 부족과 개인정보 보호 문제를 해결하기 위한 합성 데이터 생성을 촉진한다.
- 모델 재학습 없이 거대 고정 LLM이 작업별 훈련 데이터를 생성할 수 있는지 조사한다.
- 데이터 생성 방법론, 품질 평가, 다운스트림 학습 전략을 요약한다.
- 실용적 응용 및 향후 연구 방향과 해결 과제를 개략적으로 제시한다.
제안 방법
- 속성-제어 프롬프트 및 verbalizers를 포함한 작업 조건 데이터 생성을 위한 프롬프트 엔지니어링 기법을 설명한다.
- 데이터 생성에 맞춘 LLM 조정에 대한 매개변수 효율적 적응 방법(예: 어댑터, 프리픽스/프롬프트 튜닝, LoRA)을 논의한다.
- 다양성, 정확성, 자연스러움 등 데이터 품질 측정 접근법과 품질 추정 파이프라인을 기술한다.
- 합성 데이터를 효과적으로 활용하기 위한 학습 전략을 개략적으로 제시하고 정규화 및 샘플 가중치 부여 스키마를 포함한다.
- 데이터 생성 방법의 분류 체계를 제공하고 NLP의 대표적 시스템과 벤치마크를 요약한다.
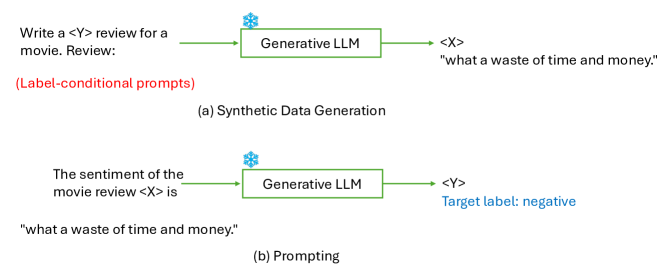
실험 결과
연구 질문
- RQ1LLM을 재학습시킴 없이 작업별 합성 데이터를 생성하는 주요 방법은 무엇인가?
- RQ2합성 데이터의 품질을 어떻게 측정하고 다운스트레이닝에 대해 보장할 수 있는가?
- RQ3저자원 또는 민감한 도메인에서 합성 데이터의 실용적 응용 및 배치 고려사항은 무엇인가?
- RQ4생성형 LLM으로부터의 합성 데이터 사용을 형성하는 과제와 향후 방향은 무엇인가?
주요 결과
- 여러 데이터 생성 방법이 등장해 라벨링되거나 비라벨링된 합성 데이터를 NLP 작업에 대해 생성한다(예: ZeroGen, ProGen, MSP, FewGen).
- 합성 데이터의 품질은 다양성, 정확성, 자연스러움을 따라 평가되며, 정확성은 자동 평가와 인간 평가를 사용한다.
- 프롬프트 엔지니어링 및 속성 제어 프롬프트가 생성 데이터의 관련성 및 다양성을 향상시킨다.
- 매개변수 효율적 적응은 전체 모델 미세조정 없이 작업 특화 데이터 생성을 가능하게 한다.
- 합성 데이터는 저자원 및 빠른 추론 시나리오에서 가능성을 보여주지만, 환각과 프라이버시 문제 등의 도전에 직면한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.