[논문 리뷰] Generative AI on the Edge: Architecture and Performance Evaluation
이 논문은 CPU 전용 Raspberry Pi 엣지 클러스터에서 K3s 관리 Docker 기반 설정으로 다양한 LLM을 평가하고, 처리량, 대기시간, 메모리/CPU 사용량, 정확도를 정량화하여 클라우드 의존 없는 GenAI의 엣지 실현 가능성을 평가합니다.
6G's AI native vision of embedding advance intelligence in the network while bringing it closer to the user requires a systematic evaluation of Generative AI (GenAI) models on edge devices. Rapidly emerging solutions based on Open RAN (ORAN) and Network-in-a-Box strongly advocate the use of low-cost, off-the-shelf components for simpler and efficient deployment, e.g., in provisioning rural connectivity. In this context, conceptual architecture, hardware testbeds and precise performance quantification of Large Language Models (LLMs) on off-the-shelf edge devices remains largely unexplored. This research investigates computationally demanding LLM inference on a single commodity Raspberry Pi serving as an edge testbed for ORAN. We investigate various LLMs, including small, medium and large models, on a Raspberry Pi 5 Cluster using a lightweight Kubernetes distribution (K3s) with modular prompting implementation. We study its feasibility and limitations by analyzing throughput, latency, accuracy and efficiency. Our findings indicate that CPU-only deployment of lightweight models, such as Yi, Phi, and Llama3, can effectively support edge applications, achieving a generation throughput of 5 to 12 tokens per second with less than 50\% CPU and RAM usage. We conclude that GenAI on the edge offers localized inference in remote or bandwidth-constrained environments in 6G networks without reliance on cloud infrastructure.
연구 동기 및 목표
- 6G/ORAN 맥락에서 자원 제약 엣지 디바이스에서 Generative AI를 실행할 수 있는 가능성을 동기 부여하고 정량화한다.
- 엣지 하드웨어에서 다른 LLM 크기의 성능 트레이드오프(처리량, 지연, 메모리, CPU 사용, 정확도)를 평가한다.
- 향후 네트워크 엣지에서 GenAI 실험을 위한 확장 가능한 엣지 AI 테스트베드와 방법론을 제공한다.
- 경험적 결과를 바탕으로 엣지 배포를 위한 모델 및 구성 선택에 대한 구체적인 지침을 제공한다.
제안 방법
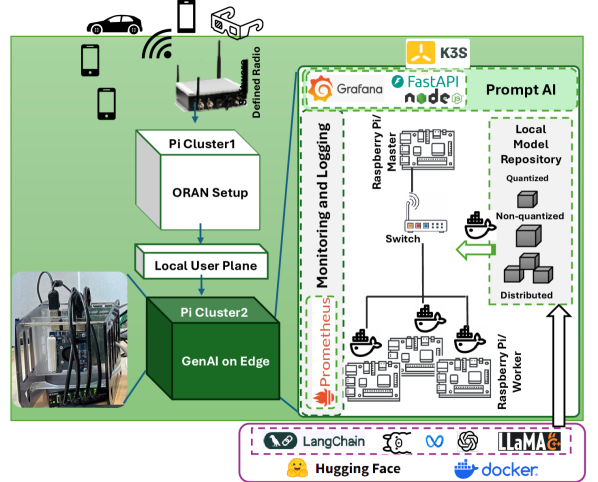
- K3스(경량 쿠버네틱스)로 조율된 네 대의 Raspberry Pi 5 노드로 구축된 엣지 테스트베드.
- 모델 선택 및 추론 라우팅을 위한 모듈식 API 기반 아키텍처의 도커화된 PromptAI 서비스.
- Hugging Face에서 가져온 4비트 GGUF 모델의 양자화된 도커 기반 워크플로우.
- 메모리, CPU, 대기시간, 정확도, 처리량을 측정하기 위해 OpenAssistant/oasst1 프롬프트의 하위집합(50 대화, 5회 이상 턴)을 사용한 평가.
- 성능 분석은 프롬프트당 500개의 생성 토큰 상한으로 결정적 추론을 위한 llama.cpp 프레임워크를 활용.
실험 결과
연구 질문
- RQ1CPU 전용 엣지 디바이스(Raspberry Pi 클러스터)가 대화형 AI 작업에 대해 LLM 추론을 효과적으로 실행할 수 있는가?
- RQ2모델 크기(대형, 중형, 소형)와 양자화(4비트 GGUF)가 엣지 하드웨어에서 처리량, 지연, 메모리, CPU, 정확도에 어떤 영향을 미치는가?
- RQ3실시간 대화 시나리오에서 엣지에 배포된 LLM의 안정성 및 맥락 민감도 특성은 무엇인가?
- RQ4스케일 가능하고 모듈식 엣지 GenAI 실험을 지원하는 배포 아키텍처와 툴링(K3s, Docker, PromptAI)은 무엇이 가장 적합한가?
주요 결과
- 경량 모델(Yi, Phi)은 CPU에서 실용적인 처리량과 지연을 달성하며, 생성은 초당 약 5–12 토큰, CPU 및 RAM 사용률은 50% 미만.
- 엔드투엔드 지연 및 처리량은 모델 크기에 따라 다르다; Yi와 같은 소형 모델이 엔드투엔드 총 시간에서 가장 빠르며(예: Yi는 InternLM보다 토큰당 총 시간에서 훨씬 빠름), 반면 더 큰 모델은 더 높은 정확도를 대가로 지연을 감수한다.
- 메모리 사용은 일반적으로 모델 크기에 따라 증가(Inte rnLM, Mistral, Llama2는 0.66–3.14 GB를 넘는 경향)이며 CPU 사용은 모델 전반에 걸쳐 약 ~50%에 집중된다.
- 정확도는 Winogrande 벤치마크에서 모델마다 다르며, InternLM은 약 0.8, Gemma는 약 0.7, Llama3은 약 0.69인 반면 Yi와 Zephyr는 각각 약 0.49와 0.46 수준으로 나타났다(비세부 미세 조정_variant).
- 처리량 CV 분석은 컨텍스트 길이에 따른 민감도가 다름; 일부 모델(Mistral, InternLM)은 프롬프트 길이 변화에 안정적이지만, 다른 모델(Llama3, Phi, Yi)은 Prefill/Decode 단계에서 더 큰 변동성을 보인다.
- 시스템은 배포 중 메모리 부족 오류나 재시작 없이 견고함을 입증했으며, 양자화는 메모리 사용을 줄이면서 약간의 정확도 저하를 받아들였다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.