[논문 리뷰] Generative Sequential Recommendation with GPTRec
GPTRec은 memory를 줄이기 위해 SVD 기반 하위 아이템 토큰화를 사용하는 GPT-2 기반의 생성적 시퀀셜 추천 시스템으로, Next-K 생성을 도입하고, SASRec와 랭킹에서 대등하며 메모리 효율성과 유연한 생성이 가능하다.
Sequential recommendation is an important recommendation task that aims to predict the next item in a sequence. Recently, adaptations of language models, particularly Transformer-based models such as SASRec and BERT4Rec, have achieved state-of-the-art results in sequential recommendation. In these models, item ids replace tokens in the original language models. However, this approach has limitations. First, the vocabulary of item ids may be many times larger than in language models. Second, the classical Top-K recommendation approach used by these models may not be optimal for complex recommendation objectives, including auxiliary objectives such as diversity, coverage or coherence. Recent progress in generative language models inspires us to revisit generative approaches to address these challenges. This paper presents the GPTRec sequential recommendation model, which is based on the GPT-2 architecture. GPTRec can address large vocabulary issues by splitting item ids into sub-id tokens using a novel SVD Tokenisation algorithm based on quantised item embeddings from an SVD decomposition of the user-item interaction matrix. The paper also presents a novel Next-K recommendation strategy, which generates recommendations item-by-item, considering already recommended items. The Next-K strategy can be used for producing complex interdependent recommendation lists. We experiment with GPTRec on the MovieLens-1M dataset and show that using sub-item tokenisation GPTRec can match the quality of SASRec while reducing the embedding table by 40%. We also show that the recommendations generated by GPTRec on MovieLens-1M using the Next-K recommendation strategy match the quality of SASRec in terms of NDCG@10, meaning that the model can serve as a strong starting point for future research.
연구 동기 및 목표
- 대규모 아이템 어휘와 Top-K를 넘어서는 유연한 목표를 다루기 위해 시퀀스 추천에 생성 모델의 사용을 촉진한다.
- 아이템 아이디를 하위 아이템 토큰으로 분할하기 위한 SVD를 이용한 메모리 효율적인 토큰화 도입.
- 상호 의존적인 추천 목록과 복잡한 목표를 가능하게 하는 Next-K 생성 전략 제안.
- GPTRec 아키텍처를 GPT-2에 기초하여 제시하고 MovieLens-1M에서 SASRec 및 BERT4Rec와 비교.
제안 방법
- 아이템 토큰의 시퀀스 모델링을 위해 교차 엔트로피 손실과 함께 GPT-2 디코더 아키텍처를 채택한다.
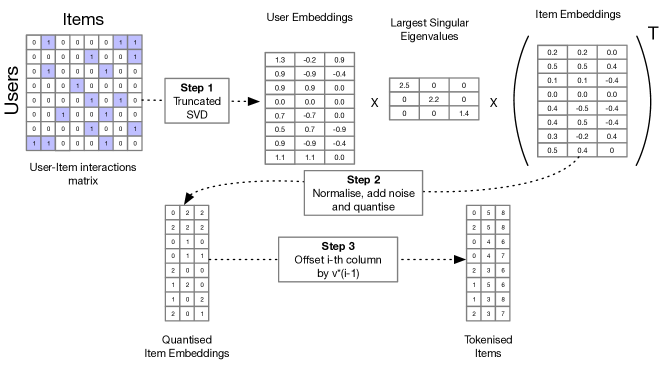
- 사용자-아이템 행렬의 양자화된 SVD 임베딩에서 아이템당 t개의 하위 아이템 토큰을 생성하는 SVD 토크나이제이션 도입.
- 메모리 사용과 생성을 균형 있게 하기 위해 아이템당 하나의 토큰 및 다중 토큰 모드를 허용한다.
- Top-K 및 Next-K 생성 전략 구현, Next-K를 위한 생성-대-생성 스코어링 포함.
- MovieLens-1M에서 남겨두기(leave-one-out) 설정과 최대 시퀀스 길이 100인 3-레이어 트랜스포머로 평가한다.
- Recall@10 및 NDCG@10을 사용하여 GPTRec 변형(GPTRec-TopK, GPTRec-NextK)을 SASRec 및 BERT4Rec와 비교한다.
실험 결과
연구 질문
- RQ1아이디당 하나의 토큰 모드에서 GPTRec의 성능은 BERT4Rec 및 SASRec와 비교해 어떠한가?
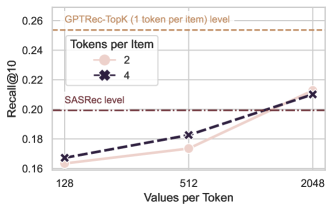
- RQ2GPTRec의 다중 토큰-당-아이템 모드에서 토큰 수와 토큰당 값의 수가 미치는 영향은 무엇인가?
- RQ3Next-K 추천 모드에서 임계값 K의 효과는 무엇인가?
주요 결과
| 모델 이름 | 생성 전략 | 아키텍처 | 학습 작업 | 손실 | Recall@10 | NDCG@10 |
|---|---|---|---|---|---|---|
| BERT4Rec | TopK | 인코더 | MLM (아이템 마스킹) | 교차 엔트로피(소프트맥스 손실) | 0.282 | 0.152 |
| GPTRec-TopK | TopK | 디코더 | LM (시퀀스 시프팅) | 교차 엔트로피(소프트맥스 손실) | 0.254 | 0.146 |
| SASRec | TopK | 디코더 | LM (시퀀스 시프팅) | 이진 교차 엔트로피 | 0.199 | 0.108 |
| GPTRec-NextK | NextK | 디코더 | LM (시퀀스 시프팅) | 교차 엔트로피(소프트맥스 손실) | 0.157 | 0.105 |
- GPTRec-NextK는 MovieLens-1M에서 Recall@10 0.157 및 NDCG@10 0.105를 달성하여 SASRec(Recall@10 0.199, NDCG@10 0.108)와 대등하게 경쟁한다.
- GPTRec-TopK는 Recall@10 0.254 및 NDCG@10 0.146을 달성하여 Top-K 설정에서 이 지표들에 대해 SASRec를 능가한다.
- BERT4Rec는 Recall@10 0.282 및 NDCG@10 0.152로 표에 보고된 GPTRec 변형들보다 높다.
- SVD 토크나이제이션은 임베딩 메모리 사용을 대폭 감소시킨다(예: t=8, v=2048은 16 MB로, 일부 규모에서 아이템당 하나의 토큰일 때의 10GB 이상과 비교).
- Next-K 모드의 GPTRec는 복잡한 목표를 다루면서도 경쟁력 있는 랭킹 품질을 유지하는 유연한 생성 프레임워크를 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.