[논문 리뷰] Ghostbuster: Detecting Text Ghostwritten by Large Language Models
타깃 모델 확률이 필요 없이 약한 언어 모델에 대한 구조화된 특징 탐색과 로지스틱 분류기를 사용하여 AI 생성 텍스트를 탐지하는 Ghostbuster가 도메인 간 in-domain에서 99.0 F1를 달성한다.
We introduce Ghostbuster, a state-of-the-art system for detecting AI-generated text. Our method works by passing documents through a series of weaker language models, running a structured search over possible combinations of their features, and then training a classifier on the selected features to predict whether documents are AI-generated. Crucially, Ghostbuster does not require access to token probabilities from the target model, making it useful for detecting text generated by black-box models or unknown model versions. In conjunction with our model, we release three new datasets of human- and AI-generated text as detection benchmarks in the domains of student essays, creative writing, and news articles. We compare Ghostbuster to a variety of existing detectors, including DetectGPT and GPTZero, as well as a new RoBERTa baseline. Ghostbuster achieves 99.0 F1 when evaluated across domains, which is 5.9 F1 higher than the best preexisting model. It also outperforms all previous approaches in generalization across writing domains (+7.5 F1), prompting strategies (+2.1 F1), and language models (+4.4 F1). We also analyze the robustness of our system to a variety of perturbations and paraphrasing attacks and evaluate its performance on documents written by non-native English speakers.
연구 동기 및 목표
- 다양한 도메인, 프롬프트 및 모델에 걸쳐 강력한 일반화가 필요한 AI 생성 텍스트 탐지기의 필요성을 제시한다.
- 타깃 모델의 토큰 확률에 대한 접근(블랙박스 설정)이 필요 없는 탐지 방법을 개발한다.
- 학생 에세이, 뉴스, 창의적 글쓰기 등 도메인 간 벤치마크를 구축하고 평가한다.
- 일반화, 프롬프트 전략에 대한 견고성, 모델-패러다임의 변화에 대해 조사한다.
- 해석 가능한 특징 중심의 탐지 접근 방식을 제공하여 취약성을 감소시킨다.
제안 방법
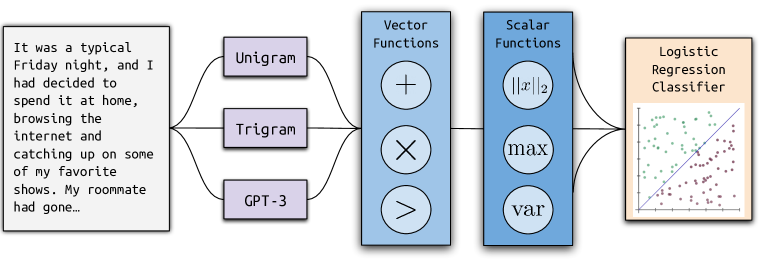
- 각 문서를 일련의 약한 언어 모델을 통해 처리하고 토큰 확률을 얻는다.
- 모델 확률을 결합하는 벡터 및 스칼라 특징 함수의 공간에 대해 구조화된 탐색을 정의한다.
- 선택된 특징들과 일곱 개의 수작업 특성들을 사용하는 로지스틱 회귀 분류기를 학습시킨다.
- 약한 모델(unigram, Kneser–Ney trigram, ada 및 davinci)로부터의 확률 벡터를 특징 구성 입력으로 사용한다.
- 분포 변화에 대한 견고성을 높이기 위해 고용량 시퀀스 모델에의 의존성을 피한다.
실험 결과
연구 질문
- RQ1타깃 모델의 토큰 확률에 대한 접근 없이 AI 생성 텍스트를 탐지할 수 있는가(블랙박스 탐지)?
- RQ2탐지기가 도메인, 프롬프트 및 보지 못한 모델들 간에 얼마나 잘 일반화되는가?
- RQ3구조화된 특징 및 약한 모델 확률 접근 방식은 편집 및 의역에 대해 견고한가?
- RQ4문서 길이가 탐지 성능에 미치는 영향은 무엇인가?
- RQ5비원어민 영어 텍스트에서의 방법 성능은 어떻게 되는가?
주요 결과
- Ghostbuster는 세 가지 도메인에서 도메인 내 탐지에 대해 99.0 F1을 달성한다.
- 도메인 외 평균 F1은 97.0으로, 평균적으로 DetectGPT 대비 39.6, GPTZero 대비 7.5를 상회한다.
- 프롬프트 간 일반화는 99.5 F1로 RoBERTa 및 GPTZero보다 낫다.
- 모델 간(Claude 포함)에서 Ghostbuster는 Claude에서 92.2 F1을 달성하며, ChatGPT 기반 데이터에 비해 일부 저하가 있다.
- 분해 실험은 구조화된 탐색과 신경 LM 확률(ada, davinci) 포함이 성능에 결정적이며, 수작업 특성은 단독으로는 영향이 제한적임을 보여준다.
- 더 긴 문서에서 성능이 향상되며, 매우 짧은 텍스트(≤100 토큰)에서는 신뢰성이 낮아진다.
- 벤치마킹을 위한 코드와 세 가지 새로운 데이터세트가 출시된다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.