[논문 리뷰] GPT-NER: Named Entity Recognition via Large Language Models
GPT-NER는 NER을 LLM의 텍스트생성 작업으로 재구성하고, 엔티티 태그가 부착된 출력과 자체 검증을 사용해 환각을 줄이며, 특히 저자원 환경에서 감독 학습 베이스라인들과 비교해 경쟁력 있는 결과를 달성한다.
Despite the fact that large-scale Language Models (LLM) have achieved SOTA performances on a variety of NLP tasks, its performance on NER is still significantly below supervised baselines. This is due to the gap between the two tasks the NER and LLMs: the former is a sequence labeling task in nature while the latter is a text-generation model. In this paper, we propose GPT-NER to resolve this issue. GPT-NER bridges the gap by transforming the sequence labeling task to a generation task that can be easily adapted by LLMs e.g., the task of finding location entities in the input text "Columbus is a city" is transformed to generate the text sequence "@@Columbus## is a city", where special tokens @@## marks the entity to extract. To efficiently address the "hallucination" issue of LLMs, where LLMs have a strong inclination to over-confidently label NULL inputs as entities, we propose a self-verification strategy by prompting LLMs to ask itself whether the extracted entities belong to a labeled entity tag. We conduct experiments on five widely adopted NER datasets, and GPT-NER achieves comparable performances to fully supervised baselines, which is the first time as far as we are concerned. More importantly, we find that GPT-NER exhibits a greater ability in the low-resource and few-shot setups, when the amount of training data is extremely scarce, GPT-NER performs significantly better than supervised models. This demonstrates the capabilities of GPT-NER in real-world NER applications where the number of labeled examples is limited.
연구 동기 및 목표
- NER와 LLM 생성 간의 간극을 좁히기 위해 NER를 생성 작업으로 재구성한다.
- LLM에 잘 구성된 시연을 제공하기 위한 프롬프트 및 검색 전략을 설계한다.
- 자체 검증 단계를 통해 NER에서 LLM의 환각을 완화한다.
- 평면 및 중첩 NER 벤치마크에서 GPT-NER를 평가하고 저자원 성능을 분석한다.
제안 방법
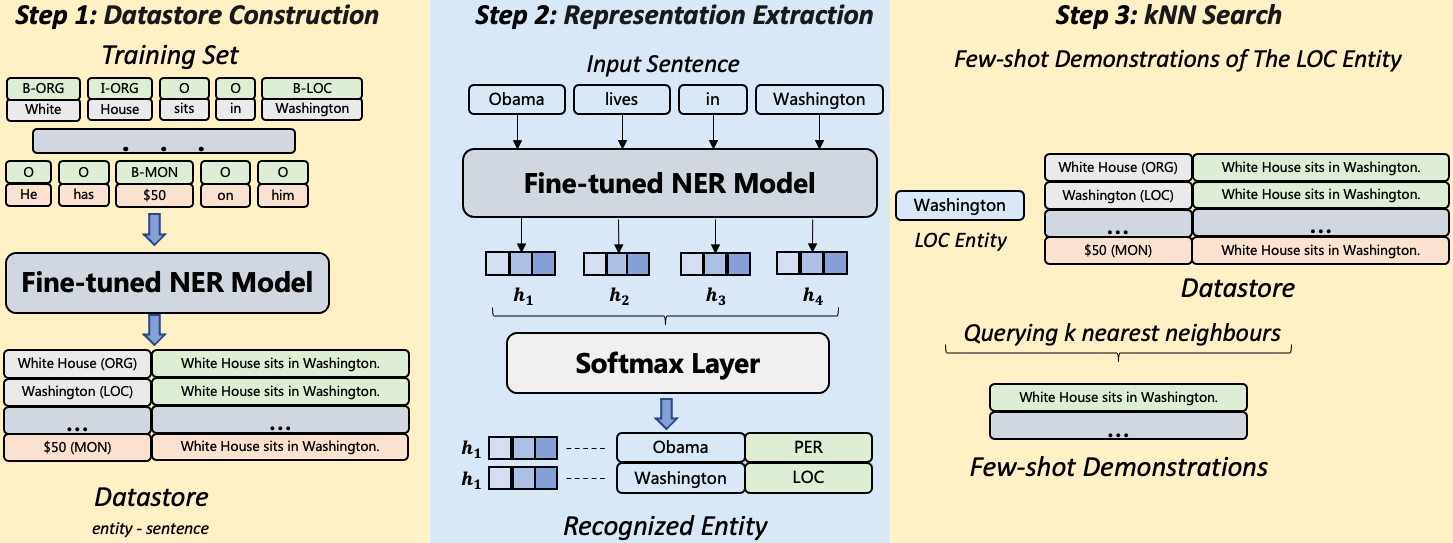
- 특수 토큰 @@ 및 ##로 엔티티를 둘러싸고 라벨링된 시퀀스를 생성하여 NER을 텍스트 생성 작업으로 변환한다.
- 작업 설명, 소수 샷 시연 및 입력 문장 섹션을 포함한 프롬프트 구성을 통해 LLM을 안내한다.
- 토큰 수준에서 k-최근접 이웃을 사용하여 관련 예시를 제공하는 시연 검색을 수행한다.
- 최종 출력 확정 전에 추출된 엔티티가 대상 레이블에 속하는지 모델이 검사하는 자체 검증 단계를 도입한다.
- GPT-3 (davinci-003)을 백본으로 고정된 생성 설정으로 표준 NER 데이터셋에서 평가한다.

실험 결과
연구 질문
- RQ1표면적(flat) 및 중첩된 데이터셋에서 표시된 출력이 있는 GPT 스타일의 생성이 감독 NER 베이스라인과 경쟁할 수 있는가?
- RQ2토큰 수준의 kNN 시연 검색이 무작위 또는 문장 수준 검색보다 NER 성능을 향상시키는가?
- RQ3자체 검증 단계가 환각을 줄이고 NER 출력의 정확도를 향상시키는가?
- RQ4저자원 및 소수 샷 시나리오에서 GPT-NER의 성능은 감독 모델과 비교해 어떠한가?
- RQ5시연 검색에 엔티티 수준 임베딩을 사용할 때 NER 작업에 미치는 영향은 무엇인가?
주요 결과
- GPT-NER은 평탄한 NER 데이터셋에서 감독 베이스라인과 비교 가능한 성능을 달성하고, 여러 설정에서 SOTA에 근접한다.
- 엔티티 수준(토큰 인식) kNN 검색은 시연에 대해 무작위 및 문장 수준 검색을 크게 능가한다.
- 자체 검증은 과도하게 확신하는 NULL 레이블링을 완화해 추가 이득을 제공하고 F1 점수를 향상시킨다.
- GPT-NER는 저자원 및 소수 샷 설정에서 강한 이점을 보이며, 라벨링된 데이터가 부족할 때 감독 모델을 능가한다.
- 더 큰 토큰 예산에서도 성능 이득이 지속되며, 더 높은 용량의 LLM(GPT-4 등)에서 개선 여지가 있음을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.