[논문 리뷰] GPTAraEval: A Comprehensive Evaluation of ChatGPT on Arabic NLP
본 논문은 44개의 아랍어 NLP 작업을 대상으로 ChatGPT (GPT-3.5-turbo) 에 대한 대규모 자동 평가 및 인간 평가를 60개 이상 데이터셋에 걸쳐 수행하고, ChatGPT가 파인튜닝된 소형 아랍어 모델들에 비해 성능이 떨어지는 경향을 보였으며, 특히 방언 아랍어에서 그렇고, 일반적으로 GPT-4가 ChatGPT보다 우수하다는 점을 보인다.
ChatGPT's emergence heralds a transformative phase in NLP, particularly demonstrated through its excellent performance on many English benchmarks. However, the model's efficacy across diverse linguistic contexts remains largely uncharted territory. This work aims to bridge this knowledge gap, with a primary focus on assessing ChatGPT's capabilities on Arabic languages and dialectal varieties. Our comprehensive study conducts a large-scale automated and human evaluation of ChatGPT, encompassing 44 distinct language understanding and generation tasks on over 60 different datasets. To our knowledge, this marks the first extensive performance analysis of ChatGPT's deployment in Arabic NLP. Our findings indicate that, despite its remarkable performance in English, ChatGPT is consistently surpassed by smaller models that have undergone finetuning on Arabic. We further undertake a meticulous comparison of ChatGPT and GPT-4's Modern Standard Arabic (MSA) and Dialectal Arabic (DA), unveiling the relative shortcomings of both models in handling Arabic dialects compared to MSA. Although we further explore and confirm the utility of employing GPT-4 as a potential alternative for human evaluation, our work adds to a growing body of research underscoring the limitations of ChatGPT.
연구 동기 및 목표
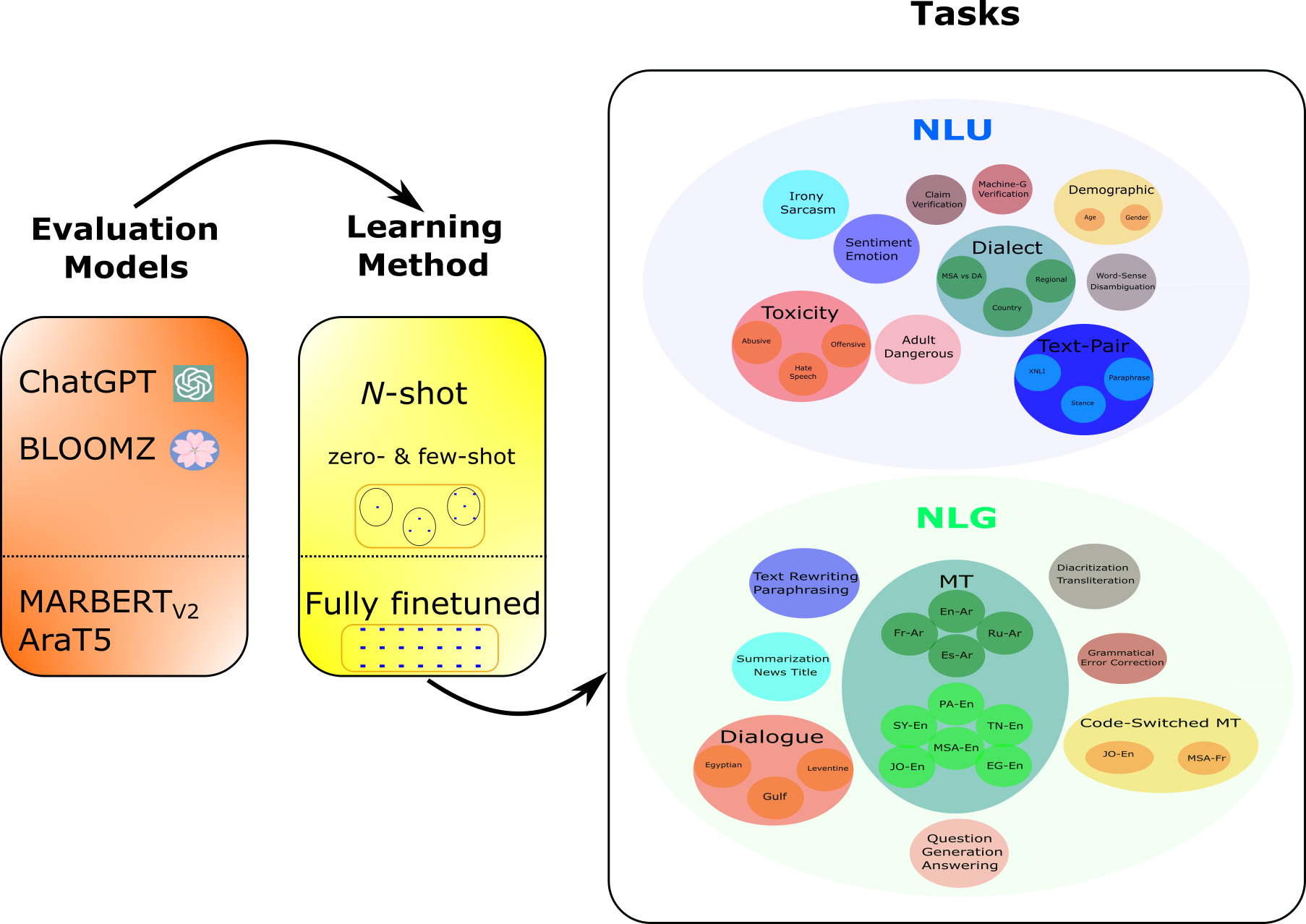
- 광범위한 아랍어 NLU 및 NLG 작업과 데이터셋 전반에 걸친 ChatGPT의 성능을 평가한다.
- BLOOMZ 및 파인튜닝된 아랍어 기준 모델(MARBERT V2, AraT5)과 ChatGPT를 비교한다.
- 현대 표준 아랍어(MSA)와 방언 아랍어(DA) 간의 성능 차이를 분석한다.
- 아랍어 생성 과제에 대해 인간 평가와 GPT-4 기반 평가의 신뢰도를 평가한다.
제안 방법
- NLU 및 NLG를 위해 60개가 넘는 데이터셋에 걸친 44개의 아랍어 NLP 작업을 사용한다.
- 영문 보편 프롬프트 템플릿을 사용하여 0-, 3-, 5-, 10-shot 프롬프트로 ChatGPT (gpt-3.5-turbo-0301)를 평가한다.
- BLOOMZ-7.1B(아랍어 포함 파인튜닝) 및 파인튜닝된 MARBERT V2 및 AraT5 기준과 비교한다.
- NLU에 대해서는 macro-F1을, NLG에는 과제에 적합한 지표를 수행한다.
- 사내 MSA vs DA 분류기 및 ORCA-연계 과제를 사용한 방언 초점 평가를 수행하고, DA 대 MSA에서 ChatGPT와 GPT-4를 비교한다.
- 자동 지표 외에도 여덟 개 NLG 작업에 대한 인간 평가를 수행하고 평가 벤치마크로 GPT-4를 사용한다.
실험 결과
연구 질문
- RQ1아랍어에 특화된 파인튜닝 모델에 비해 ChatGPT가 광범위한 아랍어 NLP 벤치마크에서 어떤 성능을 보이나?
- RQ2ChatGPT가 방언 아랍어와 비교하여 표준 아랍어(MSA)에서 어려움을 겪는가?
- RQ3방언 포함 모든 아랍어 NLU/NLG 과제에서 GPT-4가 일관되게 ChatGPT보다 강한가?
- RQ4GPT-4가 아랍어 생성 과제에서 인간 판단과 일치하는 신뢰할 수 있는 자동 평가를 제공할 수 있는가?
주요 결과
- ChatGPT는 대체로 대부분의 작업에서 더 작은 파인튜닝된 아랍어 모델에 비해 성능이 떨어진다.
- MARBERT V2는 NLU 과제에서 종종 ChatGPT보다 상당히 높은 macro-F1 점수를 산출한다.
- 방언 아랍어에서는 ChatGPT의 성능이 MSA에 뒤처지며 일반적으로 GPT-4에게 패배하는 편이고, GPT-4가 여러 DA 과제에서 더 안정적인 결과를 보인다.
- NLG 과제에서 AraT5가 일반적으로 ChatGPT와 BLOOMZ 모두를 능가하고, ChatGPT가 많은 과제에서 BLOOMZ를 능가하지만 AraT5보다 아래이다.
- 의역 및 일부 텍스트-쌍 과제에서 더 많은 샷으로 ChatGPT의 강한 향상을 보이며 때로는 완전히 파인튜닝된 MARBERT V2를 능가하지만 모든 과제에서 일관되게 그런 것은 아니다.
- 모델 출력에 대한 GPT-4 평가가 인간 평가와 상당한 정도로 일치하여, 아랍어 생성 과제에서 인간 평가의 대리 평가자로 GPT-4를 사용할 수 있음을 시사한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.