[논문 리뷰] GRAG: Graph Retrieval-Augmented Generation
GRAG는 소프트 프루닝과 이중 프롬팅(하드 텍스트 프롬프트와 소프트 그래프 프롬 prompts)으로 질의 관련 텍스트 서브그래프를 검색하여 그래프 기반 다중 홉 추론을 위해 LLM을 보강하고, 전통적인 RAG 방식보다 우수하며 환각을 감소시킨다.
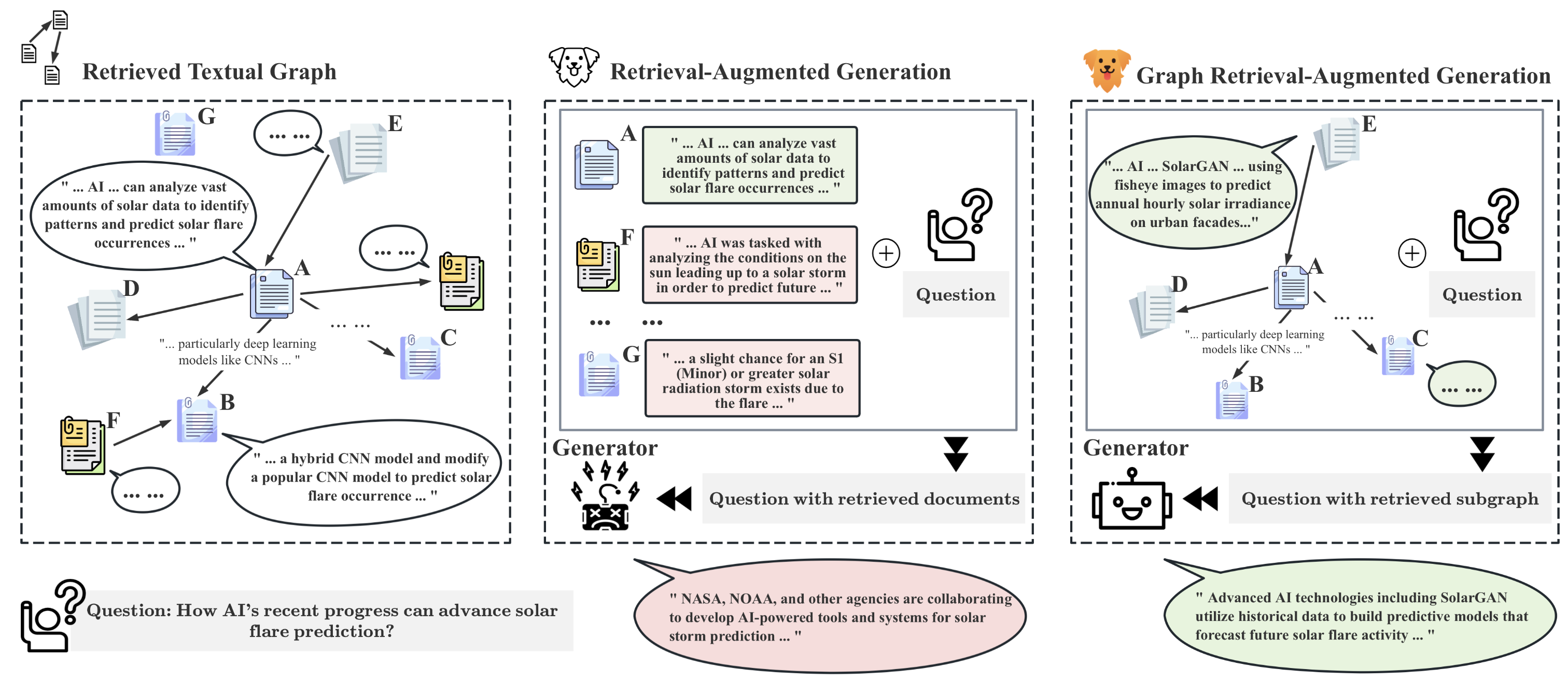
Naive Retrieval-Augmented Generation (RAG) focuses on individual documents during retrieval and, as a result, falls short in handling networked documents which are very popular in many applications such as citation graphs, social media, and knowledge graphs. To overcome this limitation, we introduce Graph Retrieval-Augmented Generation (GRAG), which tackles the fundamental challenges in retrieving textual subgraphs and integrating the joint textual and topological information into Large Language Models (LLMs) to enhance its generation. To enable efficient textual subgraph retrieval, we propose a novel divide-and-conquer strategy that retrieves the optimal subgraph structure in linear time. To achieve graph context-aware generation, incorporate textual graphs into LLMs through two complementary views-the text view and the graph view-enabling LLMs to more effectively comprehend and utilize the graph context. Extensive experiments on graph reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods. Our datasets as well as codes of GRAG are available at https://github.com/HuieL/GRAG.
연구 동기 및 목표
- 토폴로지가 텍스트 만으로는 충분하지 않은 텍스트 그래프에서 견고한 추론을 촉진한다.
- NP-난제 서브그래프 탐색에 대처하기 위한 효율적 서브그래프 검색 메커니즘을 제안한다.
- 검색 및 생성 중 텍스트 내용과 그래프 토폴로지 모두를 보존한다.
- 텍스트 서브그래프를 손실 없이 계층적 설명으로 변환하는 프롬프트 전략을 도입한다.
제안 방법
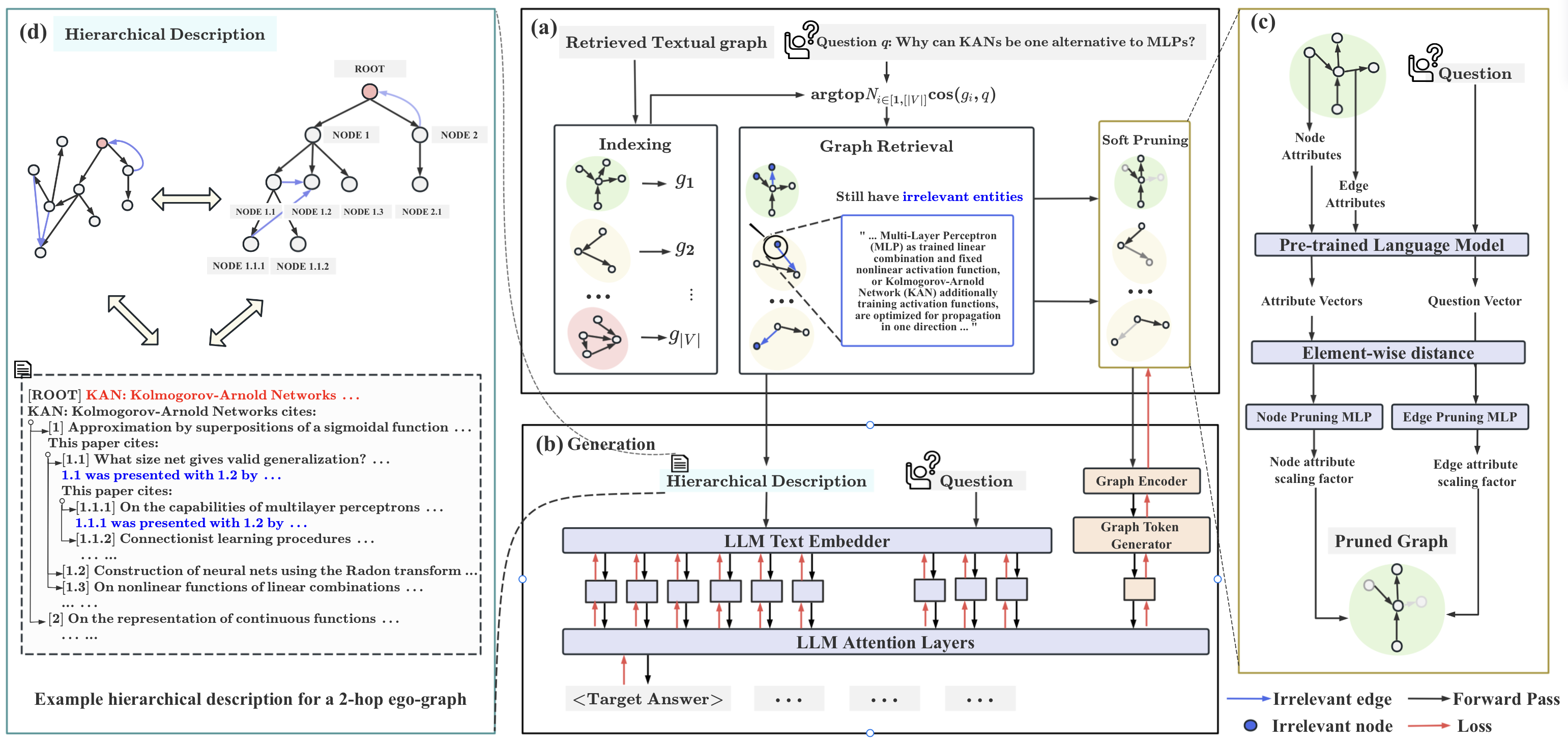
- k-hop 자가 그래프를 인덱싱하고 이를 사전 학습된 언어 모델을 사용하여 그래프 임베딩으로 인코딩한다.
- 질문 임베딩과 서브그래프 임베딩 간의 코사인 유사도로 상위-N 텍스트 서브그래프를 검색한다.
- 질문-서브그래프 거리에서 학습된 관련성 스칼라를 통해 노드/에지 기여를 스케일링하는 소프트 프루닝을 적용한다.
- 하드 프롬프트(서브그래프의 계층적 텍스트 설명)와 소프트 프롬프트(그래프 임베딩)를 결합하고 그래프 임베딩을 GNN과 MLP를 통해 LLM 텍스트 벡터에 맞춘다.
실험 결과
연구 질문
- RQ1대규모 텍스트 그래프에서 완전 탐색 없이 질의 관련 서브그래프를 어떻게 효율적으로 검색할 수 있는가?
- RQ2생성 중 텍스트 정보와 위상 정보를 어떻게 보존하고 통합할 수 있는가?
- RQ3검색된 서브그래프로 보강된 동결된 LLM이 그래프 추론 작업에서 미세 조정된 LLM 베이스라인보다 우수한가?
- RQ4소프트 프롬프팅이 큰 학습 비용 없이 그래프 인지 생성에 효과적으로 가이드를 제공할 수 있는가?
주요 결과
| 모델 | Φ(g) | 파인 튜닝 | WebQSP F1 | WebQSP Hit@1 | WebQSP 재현율 | WebQSP 정확도 | ExplaGraphs F1 | ExplaGraphs Hit@1 | ExplaGraphs 재현율 | ExplaGraphs 정확도 |
|---|---|---|---|---|---|---|---|---|---|---|
| LLM only | ✗ | ✗ | 0.2555 | 0.4148 | 0.2920 | 0.3394 | ||||
| LLM_LoRA | ✗ | ✓ | 0.4295 | 0.6186 | 0.4193 | 0.8927 | ||||
| BM25 | ✗ | ✗ | 0.2999 | 0.4287 | 0.2879 | 0.6011 | ||||
| MiniLM-L12-v2 | ✗ | ✗ | 0.3485 | 0.4730 | 0.3289 | 0.6011 | ||||
| LaBSE | ✗ | ✗ | 0.3280 | 0.4496 | 0.3126 | 0.6011 | ||||
| mContriever-Base | ✗ | ✗ | 0.3172 | 0.4453 | 0.3047 | 0.5866 | ||||
| E5-Base | ✗ | ✗ | 0.3421 | 0.4705 | 0.3254 | 0.6011 | ||||
| G-Retriever | ✓ | ✗ | 0.4674 | 0.6808 | 0.4579 | 0.8825 | ||||
| G-Retriever_LoRA | ✓ | ✓ | 0.5023 | 0.7016 | 0.5002 | 0.9042 | ||||
| GRAG | ✓ | ✗ | 0.5022 | 0.7236 | 0.5099 | 0.9223 | 0.NOP | 0.NOP | 0.NOP | 0.NOP |
| GRAG_LoRA | ✓ | ✓ | 0.5041 | 0.7275 | 0.5112 | 0.9274 | 0.NOP | 0.NOP | 0.NOP | 0.NOP |
- GRAG은 그래프 다중 홉 추론 벤치마크(WebQSP 및 ExplaGraphs)에서 최첨단 RAG 베이스라인 및 LLM 단독 접근법보다 우수하다.
- GRAG를 동결된 LLM은 모든 작업에서 미세 조정된 LLM보다 우수하고 학습 비용이 더 낮다.
- 소프트 프루닝과 서브그래프 수준 검색은 환각을 줄이고 사실적 근거를 향상시키며 인간 평가에서 더 높은 유효 엔티티 인용으로 입증된다.
- 검색된 서브그래프를 소프트 그래프 토큰으로 사용하는 것이 텍스트만 사용하거나 전체 서브그래프 탐색만 사용하는 것보다 성능이 더 좋다.
- 크로스 데이터세트 전이에서 한 데이터세트에서 학습된 GRAG가 다른 데이터세트의 성능을 향상시킬 수 있다(예: WebQSP에서 ExplaGraphs로의 전이).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.