[논문 리뷰] graph2vec: Learning Distributed Representations of Graphs
graph2vec는 루트 하위그래프를 문서의 단어로 취급하여 데이터 기반의 비지도 임베딩을 전체 그래프에 대해 학습하고, 그래프 분류와 클러스터링을 그래프 커널과 경쟁력 있는 성능으로 가능하게 한다.
Recent works on representation learning for graph structured data predominantly focus on learning distributed representations of graph substructures such as nodes and subgraphs. However, many graph analytics tasks such as graph classification and clustering require representing entire graphs as fixed length feature vectors. While the aforementioned approaches are naturally unequipped to learn such representations, graph kernels remain as the most effective way of obtaining them. However, these graph kernels use handcrafted features (e.g., shortest paths, graphlets, etc.) and hence are hampered by problems such as poor generalization. To address this limitation, in this work, we propose a neural embedding framework named graph2vec to learn data-driven distributed representations of arbitrary sized graphs. graph2vec's embeddings are learnt in an unsupervised manner and are task agnostic. Hence, they could be used for any downstream task such as graph classification, clustering and even seeding supervised representation learning approaches. Our experiments on several benchmark and large real-world datasets show that graph2vec achieves significant improvements in classification and clustering accuracies over substructure representation learning approaches and are competitive with state-of-the-art graph kernels.
연구 동기 및 목표
- 전체 그래프에 대해 고정 길이 임베딩을 학습하여 분류 및 클러스터링과 같은 다운스트림 ML 작업을 가능하게 한다는 동기를 제공한다.
- 수작업으로 만든 그래프 커널과 부분구조 임베딩의 한계를 데이터 기반의 비지도, 작업-무관한 접근 방식으로 제시한다.
- 문서 임베딩에서 아이디어를 활용하여 그래프를 루트 하위그래프의 문서로 모델링한다.
- 벤치마크 데이터세트와 대규모 현실 데이터(악성 코드 그래프)에서 분류 및 클러스터링 작업에 대해 효과를 입증한다.
제안 방법
- 각 그래프를 노드 주변의 루트 하위그래프들로 구성된 문서로 표현한다(차수 D까지).
- WL 재표기화를 사용하여 루트 하위그래프를 어휘 항목으로 생성 및 라벨링한다.
- 음수 샘플링이 있는 스킵그램 모델을 학습하여 그래프 임베딩을 얻고 Pr(sg|G)를 최적화한다.
- 에포크에 걸쳐 확률적 기울기 하강법으로 그래프 임베딩을 반복적으로 업데이트한다.
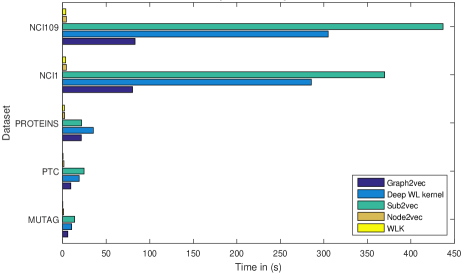
- 여러 데이터세트에서 graph2vec를 node2vec, sub2vec, WL 커널, Deep WL 커널과 비교한다.
- 비지도이며 작업-무관한 목표를 사용하여 차원 delta로 그래프를 임베딩한다.
실험 결과
연구 질문
- RQ1graph2vec가 정확도와 효율성 측면에서 벤치마크 데이터세트에 대한 그래프 분류에서 최첨단 부분구조 표현 학습 접근법 및 그래프 커널과 어떻게 비교되는가?
- RQ2대규모 실제 그래프 분류 작업(예: 악성 코드 탐지)에서 graph2vec가 기존 방법과 비교하여 어떻게 성능을 보이는가?
- RQ3그래프 클러스터링 작업(예: 악성 가족 클러스터링)에서 graph2vec가 경쟁 방식에 비해 어떻게 성능을 발휘하는가?
주요 결과
| Dataset | node2vec | sub2vec | WL kernel | Deep WL kernel | graph2vec |
|---|---|---|---|---|---|
| MUTAG | 72.63 �b1 10.20 | 61.05 �b1 15.79 | 80.63 �b1 3.07 | 82.95 �b1 1.96 | 83.15 �b1 9.25 |
| PTC | 58.85 �b1 8.00 | 59.99 �b1 6.38 | 56.91 �b1 2.79 | 59.04 �b1 1.09 | 60.17 �b1 6.86 |
| PROTEINS | 57.49 �b1 3.57 | 53.03 �b1 5.55 | 72.92 �b1 0.56 | 73.30 �b1 0.82 | 73.30 �b1 2.05 |
| NCI1 | 54.89 �b1 1.61 | 52.84 �b1 1.47 | 80.01 �b1 0.50 | 80.31 �b1 0.46 | 73.22 �b1 1.81 |
| NCI109 | 52.68 �b1 1.56 | 50.67 �b1 1.50 | 80.12 �b1 0.34 | 80.32 �b1 0.33 | 74.26 �b1 1.47 |
- 벤치마크 데이터세트에서 graph2vec는 MUTAG, PTC 및 PROTEINS에서 다른 표현 학습 및 커널 방법을 능가하며 NCI1 및 NCI109에서 유사한 정확도를 보인다.
- 대규모 실제 악성 코드 분류에서 graph2vec는 99.03%의 정확도를 달성하며 node2vec, sub2vec, WL 커널, Deep WL 커널보다 우수한 성능을 보인다.
- Sub2vec는 샘플링 한계로 대체로 모든 데이터세트에서 성능이 떨어지며; node2vec는 더 큰 그래프에서 어려움을 겪고; WL 커널은 그래프2vec와 비교적 근접한 강력한 기준선을 유지한다.
- Graph2vec는 로컬 및 전역 그래프 유사성을 포착하는 데이터 기반의 구조 보존 표현을 제공한다.
- 임베딩은 일반 분류기(RF, NN, SVM)와 함께 그래프 분류 및 클러스터링에 사용할 수 있어, 일부 커널 기반 방법과 달리 보다 유연하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.