[논문 리뷰] Grounded Language Learning in a Simulated 3D World
이 논문은 강화 학습과 비지도 보조 목표를 결합하여 3D 시뮬레이션 세계에서 자연어를 grounding하는 에이전트를 제시하며, 제로샷 이해 및 새로운 명령에 대한 일반화를 가능하게 한다. 이 접근 방식은 시각 인식, 언어 처리, 행동 정책을 엔드투엔드로 통합하고 커리큘럼 기반의 다중작업 학습 및 의미적 부트스트래핑을 시연한다.
We are increasingly surrounded by artificially intelligent technology that takes decisions and executes actions on our behalf. This creates a pressing need for general means to communicate with, instruct and guide artificial agents, with human language the most compelling means for such communication. To achieve this in a scalable fashion, agents must be able to relate language to the world and to actions; that is, their understanding of language must be grounded and embodied. However, learning grounded language is a notoriously challenging problem in artificial intelligence research. Here we present an agent that learns to interpret language in a simulated 3D environment where it is rewarded for the successful execution of written instructions. Trained via a combination of reinforcement and unsupervised learning, and beginning with minimal prior knowledge, the agent learns to relate linguistic symbols to emergent perceptual representations of its physical surroundings and to pertinent sequences of actions. The agent's comprehension of language extends beyond its prior experience, enabling it to apply familiar language to unfamiliar situations and to interpret entirely novel instructions. Moreover, the speed with which this agent learns new words increases as its semantic knowledge grows. This facility for generalising and bootstrapping semantic knowledge indicates the potential of the present approach for reconciling ambiguous natural language with the complexity of the physical world.
연구 동기 및 목표
- 연속적이고 구현된 환경에서 확장 가능한 인간–AI 상호 작용의 수단으로 언어 학습의 grounding을 촉진한다.
- 픽셀 단위 입력을 사용하여 언어 표현을 지각 표현 및 행동으로 매핑하는 엔드투엔드 에이전트를 개발한다.
- 강화 학습과 비지도 보조 작업을 결합하면 학습이 가속되고 새로운 명령에 대한 일반화가 가능함을 보인다.
- 다중 과제 학습 및 커리큘럼 학습을 통해 의미 지식을 획득하고 과제와 환경 간에 이전함을 시연한다.
제안 방법
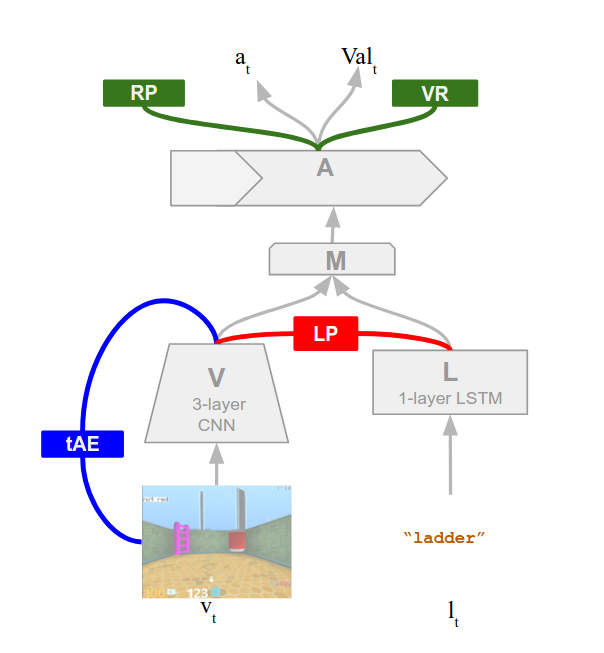
- 에이전트는 네 개의 상호 연결된 신경 모듈로 구성된다: 시각 인코더(V), 언어 인코더(L), 혼합 모듈(M), 행동/정책 모듈(A).
- 학습은 비동기 32 스레드와 RMSProp 최적화를 갖는 Advantage Actor-Critic를 사용한다.
- 보조 비지도 목표에는 다음 시각 입력을 예측하는 시간적 자동인코딩(tAE)과 관찰로부터 명령어를 예측하는 언어 예측(LP) 작업이 포함된다.
- 실험에 포함된 추가 보조 작업으로는 강화 학습의 안정화를 위한 보상 예측(RP)과 가치 재생(VR)이 있다.
- 보상으로부터의 학습은 표현 학습과 정책 최적화를 형성하기 위한 세계에 대한 예측으로 보완된다.
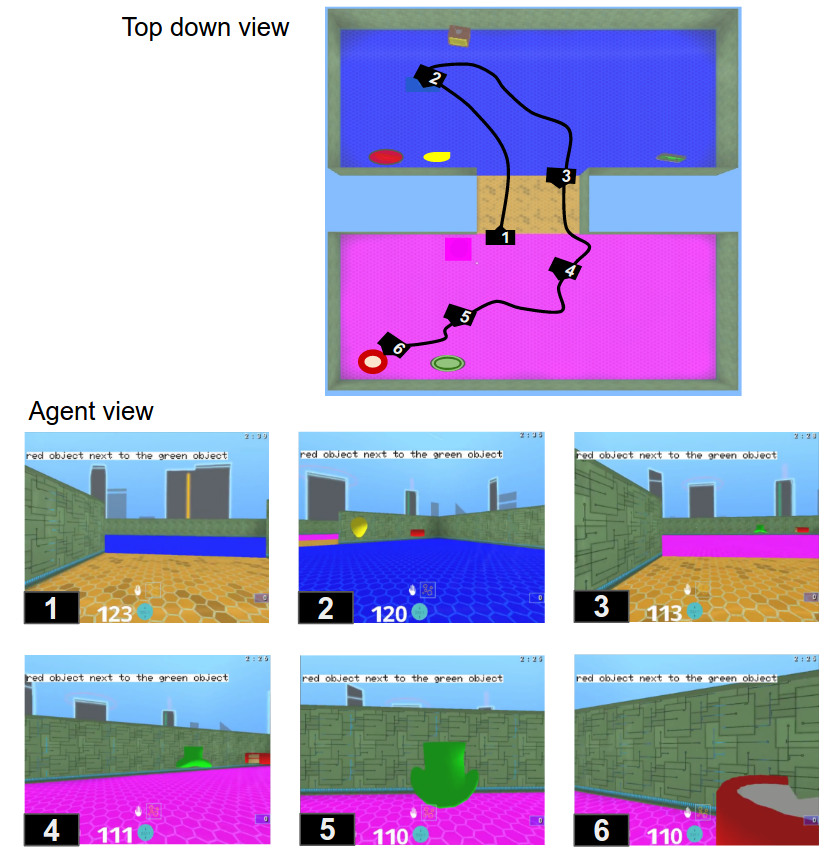
실험 결과
연구 질문
- RQ1에이전트가 연속적 3D 환경에서 원시 픽셀 입력으로부터 언어 표현에 대한 grounded 의미를 학습할 수 있는가?
- RQ2강화 학습과 비지도 보조 목표를 결합하면 효율적인 어휘 학습과 새로운 명령에 대한 일반화가 가능해지는가?
- RQ3에이전트가 어휘 개념을 분해하고 구성하여 낯선 구를 해석하고 관계적 언어를 새로운 객체로 확장할 수 있는가?
- RQ4커리큘럼 학습이 작업 간의 행동 및 관계에 묶인 언어의 다중 작업 grounding을 가능하게 하는가?
주요 결과
- 강화 학습만으로는 학습이 거의 일어나지 않으며; 보조 목적들(tAE, LP, RP, VR)이 어휘 습득을 크게 가능하게 한다.
- 에이전트가 사전 어휘 지식을 보유할 때 어휘 학습 속도가 향상되어 의미 지식의 부트스트래핑이 새로운 어휘 습득을 가속함을 시사한다.
- 에이전트는 알려진 개념의 분해와 생산적 구성을 통해 보지 않은 단어와 새로운 조합으로 일반화한다.
- 커리큘럼 학습은 점진적으로 더 복잡한 지시적 표현과 다중 작업 언어 grounding 해결을 가능하게 한다.
- 한 에이전트가 두 단계 커리큘럼을 통해 여러 작업(Selection, Next to, In room)을 학습하여 더 큰 환경으로의 언어 grounding 정책 전이를 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.