[논문 리뷰] Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools
본 논문은 Lexis+ AI, Westlaw AI-Assisted Research, Ask Practical Law AI를 GPT-4와 대비시켜 사전 등록된 평가를 수행했으며, 도구 간 현저한 환각과 가변적인 정확도를 보인다.
Legal practice has witnessed a sharp rise in products incorporating artificial intelligence (AI). Such tools are designed to assist with a wide range of core legal tasks, from search and summarization of caselaw to document drafting. But the large language models used in these tools are prone to "hallucinate," or make up false information, making their use risky in high-stakes domains. Recently, certain legal research providers have touted methods such as retrieval-augmented generation (RAG) as "eliminating" (Casetext, 2023) or "avoid[ing]" hallucinations (Thomson Reuters, 2023), or guaranteeing "hallucination-free" legal citations (LexisNexis, 2023). Because of the closed nature of these systems, systematically assessing these claims is challenging. In this article, we design and report on the first preregistered empirical evaluation of AI-driven legal research tools. We demonstrate that the providers' claims are overstated. While hallucinations are reduced relative to general-purpose chatbots (GPT-4), we find that the AI research tools made by LexisNexis (Lexis+ AI) and Thomson Reuters (Westlaw AI-Assisted Research and Ask Practical Law AI) each hallucinate between 17% and 33% of the time. We also document substantial differences between systems in responsiveness and accuracy. Our article makes four key contributions. It is the first to assess and report the performance of RAG-based proprietary legal AI tools. Second, it introduces a comprehensive, preregistered dataset for identifying and understanding vulnerabilities in these systems. Third, it proposes a clear typology for differentiating between hallucinations and accurate legal responses. Last, it provides evidence to inform the responsibilities of legal professionals in supervising and verifying AI outputs, which remains a central open question for the responsible integration of AI into law.
연구 동기 및 목표
- 선도적인 AI 법률 연구 도구에서 환각의 발생률과 특성을 평가한다.
- 체계적 평가를 위한 사전 등록된 도메인별 법적 질의 데이터셋을 만든다.
- RAG 기반 시스템에서 환각과 정확한 법적 응답을 구분하는 유형학을 개발한다.
- 법적 업무에서 AI를 사용하는 변호사를 위한 감독 및 검증 관행을 안내하는 증거를 제공한다.
제안 방법
- 법적 산출물의 정확성과 근거성(groundedness)을 구분하는 형식적 프레임워크를 정의한다.
- 200개가 넘는 법적 질의의 사전 등록된 데이터셋을 수작업으로 선별한다.
- 해당 데이터셋에 대해 Lexis+ AI, Westlaw AI-Assisted Research, Ask Practical Law AI, 및 GPT-4를 평가한다.
- 정확성과 권위성에 대한 충실도 측면에서 출력물을 수작업으로 검토한다.
- RAG 기반 도구를 범용 모델(GPT-4)과 비교하여 상대적 개선과 남아 있는 위험을 평가한다.
실험 결과
연구 질문
- RQ1실제 질의에 대해 선도적인 AI 법률 연구 도구의 환각 비율은 얼마인가?
- RQ2이 도구들은 권위 있는 소스에 대한 정확성과 근거성 측면에서 어떻게 비교되는가?
- RQ3일반 목적의 LLM에 비해 RAG 기반 접근 방식이 환각을 의미 있게 줄이는가?
- RQ4변호사의 AI 산출물 감독 및 검증에 대한 실질적 시사점은 무엇인가?
주요 결과
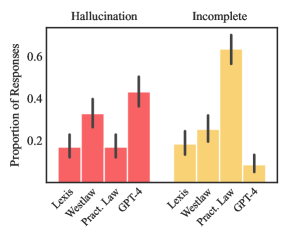
- Lexis+ AI는 질의의 65%를 정확하게 응답한다.
- Westlaw AI-Assisted Research는 42%의 정확도를 보인다.
- Ask Practical Law AI는 60%가 넘는 질의에서 불완전하거나 근거가 없는 응답을 제공한다.
- 모든 도구에서 특정 도구들에 대해 17%에서 33% 사이의 무시할 수 없는 환각 비율이 나타난다.
- RAG는 GPT-4에 비해 성능을 향상시키지만 법적 업무에서 환각을 완전히 제거하지는 못한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.