[논문 리뷰] Harnessing Artificial Intelligence to Combat Online Hate: Exploring the Challenges and Opportunities of Large Language Models in Hate Speech Detection
본 논문은 HateCheck 데이터셋에서 GPT-3.5, Llama-2, Falcon을 제로샷 혐오 발언 탐지기로 실증적으로 평가하고, 프롬프트 전략을 분석하며, LLM 기반 혐오 발언 분류의 강건성 및 편향에 대해 논의한다.
Large language models (LLMs) excel in many diverse applications beyond language generation, e.g., translation, summarization, and sentiment analysis. One intriguing application is in text classification. This becomes pertinent in the realm of identifying hateful or toxic speech -- a domain fraught with challenges and ethical dilemmas. In our study, we have two objectives: firstly, to offer a literature review revolving around LLMs as classifiers, emphasizing their role in detecting and classifying hateful or toxic content. Subsequently, we explore the efficacy of several LLMs in classifying hate speech: identifying which LLMs excel in this task as well as their underlying attributes and training. Providing insight into the factors that contribute to an LLM proficiency (or lack thereof) in discerning hateful content. By combining a comprehensive literature review with an empirical analysis, our paper strives to shed light on the capabilities and constraints of LLMs in the crucial domain of hate speech detection.
연구 동기 및 목표
- LLM이 혐오 발언 탐지자 및 주석자로서 작동하는 방식을 검토한다.
- 오픈 소스 LLM과 독점 LLM의 혐오 발언 탐지 성능을 경험적으로 비교한다.
- 프롬프트 전략과 분류 효율성에 대한 영향을 조사한다.
- LLM을 혐오 발언 관리에 배치할 때의 한계, 편향 및 모범 사례를 식별한다.
제안 방법
- 텍스트 분류기 및 혐오 발언 탐지기로서의 LLM에 관한 선행 연구(LLM 이전 시대 대 LLM 시대)에 관한 문헌 고찰.
- HateCheck에서 제로샷 혐오 발언 탐지를 사용하여 GPT-3.5, Llama-2, Falcon을 경험적으로 평가.
- 직접적이고 간결한 프롬프트, 컨텍스트 프롬프트, 그리고 GPT-3.5와 함께하는 사고의 연쇄(chain-of-thought) 프롬프트를 포함한 프롬프트 설계 실험.
- LLM 출력물을 혐오/비혜오 라벨로 매핑하는 분류 라벨링 전략.
- 방향성 및 대상 편향에 대한 HateCheck 주석을 사용한 오류 분석.
실험 결과
연구 질문
- RQ1RQ1: LLM은 일반적 범주와 대상화된 범주 전반에서 혐오 발언 탐지에 얼마나 강건한가?
- RQ2RQ2: 프롬프트 기법이 LLM의 혐오 발언 탐지 효율성에 어떤 영향을 미치는가?
주요 결과
| LLM | Hate P | Hate R | Hate F1 | Non-Hate P | Non-Hate R | Non-Hate F1 | Accuracy | AUROC |
|---|---|---|---|---|---|---|---|---|
| Falcon | 0.69 | 0.43 | 0.53 | 0.30 | 0.56 | 0.40 | 0.47 | 0.49 |
| Llama 2 | 0.80 | 1.00 | 0.89 | 0.99 | 0.46 | 0.63 | 0.83 | 0.73 |
| GPT 3.5 | 0.89 | 0.98 | 0.93 | 0.93 | 0.73 | 0.82 | 0.89 | 0.85 |
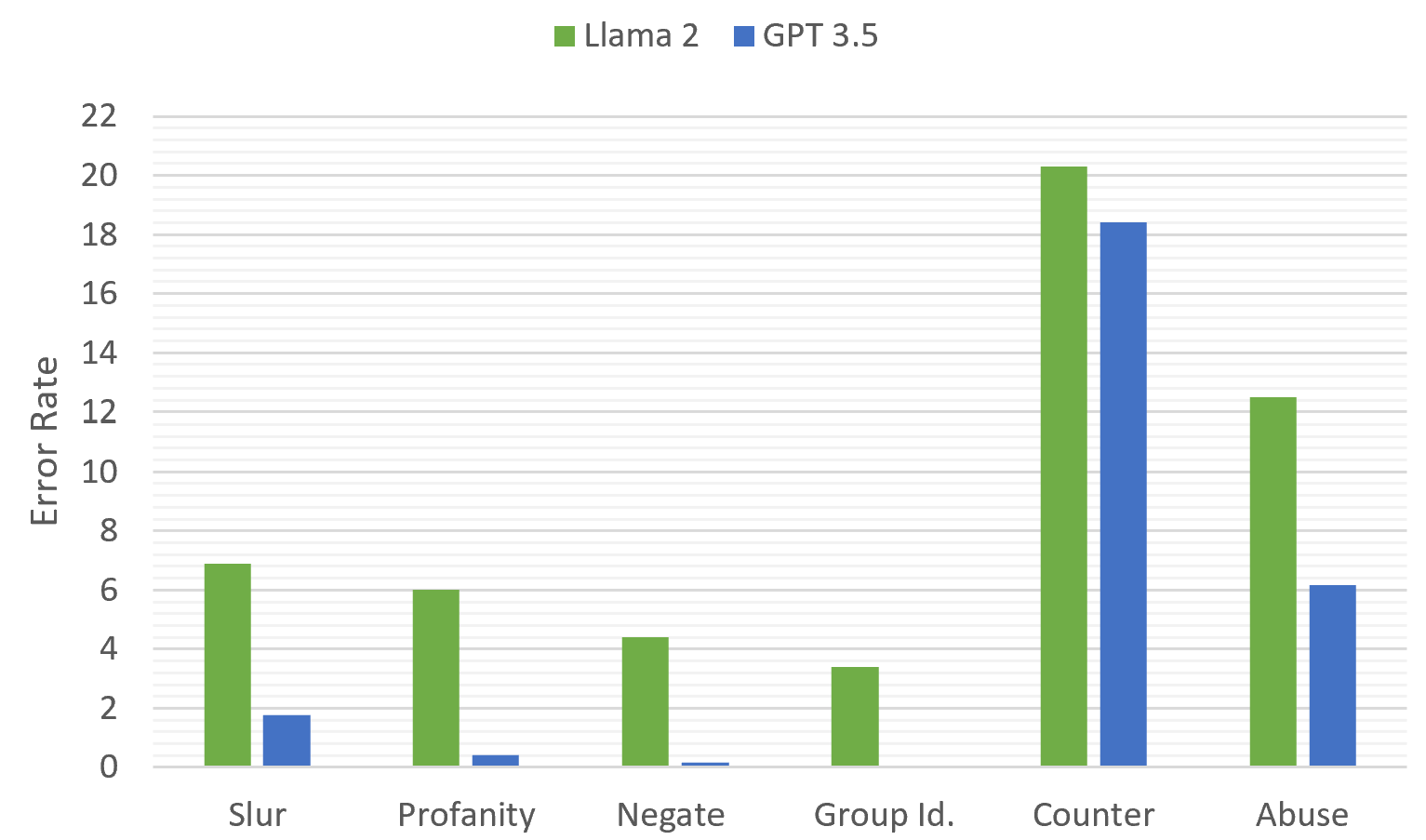
- GPT-3.5는 테스트된 모델들 중 전체 혐오 발언 탐지 성능이 가장 높았으며 (보고된 F1 및 관련 지표가 83?~93? 범위), Llama-2가 GPT-3.5 성능에 근접하게 도달한다.
- Llama-2 (7B)은 혐오 발언 탐지에서 강력한 성능을 보이지만 비혐오 콘텐츠를 식별할 때 허위 상관관계에 더 의존하는 경향을 보인다.
- Falcon은 혐오 발언 분류에서 GPT-3.5 및 Llama-2에 비해 성능이 떨어진다.
- 프롬프트의 영향: 직접적이고 간결한 프롬프트가 최상의 전반 성능을 제공하는 반면, 컨텍스트 프롬프트와 사고의 연쇄 프롬프트는 일관되게 결과를 개선하지 않는다.
- 오류 분석은 지시된 혐오와 일반 혐오를 처리하는 차이 및 혐오 대상(예: 여성, 무슬림 등)에 따른 성능 차이를 밝힌다.
- 연구는 잠재적 가드레일 상호작용과 잘못된 신호를 줄이기 위한 라벨링 기능 및 균형 잡힌 미세조정의 중요성을 강조한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.