[논문 리뷰] How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
논문은 Open instruction-tuning 데이터셋을 모델 크기 6.7B–65B 및 기본 LMs에 걸쳐 체계적으로 평가하고, 모든 작업에 최적의 단일 데이터셋은 없으며 기본 모델의 품질이 결정적이며, 그들이 공개한 최적의 공개 모델(Tülu)은 평균적으로 ChatGPT/GPT-4보다 뒤처진다는 것을 보여준다. 그들은 모델, 데이터, 평가 프레임워크를 공개한다.
In this work we explore recent advances in instruction-tuning language models on a range of open instruction-following datasets. Despite recent claims that open models can be on par with state-of-the-art proprietary models, these claims are often accompanied by limited evaluation, making it difficult to compare models across the board and determine the utility of various resources. We provide a large set of instruction-tuned models from 6.7B to 65B parameters in size, trained on 12 instruction datasets ranging from manually curated (e.g., OpenAssistant) to synthetic and distilled (e.g., Alpaca) and systematically evaluate them on their factual knowledge, reasoning, multilinguality, coding, and open-ended instruction following abilities through a collection of automatic, model-based, and human-based metrics. We further introduce Tülu, our best performing instruction-tuned model suite finetuned on a combination of high-quality open resources. Our experiments show that different instruction-tuning datasets can uncover or enhance specific skills, while no single dataset (or combination) provides the best performance across all evaluations. Interestingly, we find that model and human preference-based evaluations fail to reflect differences in model capabilities exposed by benchmark-based evaluations, suggesting the need for the type of systemic evaluation performed in this work. Our evaluations show that the best model in any given evaluation reaches on average 87% of ChatGPT performance, and 73% of GPT-4 performance, suggesting that further investment in building better base models and instruction-tuning data is required to close the gap. We release our instruction-tuned models, including a fully finetuned 65B Tülu, along with our code, data, and evaluation framework at https://github.com/allenai/open-instruct to facilitate future research.
연구 동기 및 목표
- Instruction-tuning on open datasets가 사실 지식, 추론, 다국어 능력, 코딩, 안전성, 그리고 개방형 지시 이행에 어떤 영향을 주는지 평가한다.
- 개방형 데이터세트와 다양한 기본 모델 및 지시 데이터셋을 광범위하게 비교하여 공개 지시 튜닝 자원들의 강점과 약점을 파악한다.
- 모델 기반 평가와 벤치마크 기반 평가가 모델 능력을 드러내는 데 얼마나 일치하는지 조사한다.
- 다양한 공개 리소스로 구축된 최고 성능의 개방형 지시 튜닝 모델 모음집(Tülu)을 제안하고 평가한다.
제안 방법
- 다양한 지시 데이터셋을 공통의 챗봇 스타일 포맷으로 통합하여 디코더-전용 LMs를 Teacher-forcing 및 토큰 수준 손실 마스킹으로 학습시킨다.
- 12개의 지시 데이터셋(수동, 합성, 증류 소스)을 대상으로 6.7B–65B 크기의 LLaMa, LLaMa-2, OPT, Pythia 기반 모델을 학습한다.
- Tülu 모델을 학습하고 혼합 데이터를 Human data와 Human+GPT data로 구성하여 혼합의 효과를 비교한다.
- MMLU, GSM, BBH, TyDiQA, Codex-Eval, AlpacaEval, ToxiGen, TruthfulQA 등 다방면의 평가 도구 및 모델 기반(GPT-4 주석자) 및 인간 평가를 포함하여 모델을 평가한다.
- 데이터셋 선택, 기본 모델 품질, 데이터 혼합이 작업 및 평가 모듈성에서의 성능에 어떤 영향을 미치는지 분석한다.

실험 결과
연구 질문
- RQ1Instruction-tuning 데이터셋이 특정 모델 기술(사실적 지식, 추론, 다국어, 코딩) 및 개방형 지시 이행에 어떤 영향을 미치는가?
- RQ2다양한 데이터셋을 결합하면 전반적으로 최상의 성능을 내는가, 아니면 특정 작업에 한해 데이터셷이 지배적인가?
- RQ3기본 모델 품질(크기 및 사전학습 데이터)이 instruction-tuning 데이터와 상호작용하여 성능에 어떤 영향을 주는가?
- RQ4모델 기반 평가와 인간 평가가 벤치마크 기반 평가와 모델 능력을 얼마나 일치시켜 반영하는가?
- RQ5개방형 지시 튜닝 모델과 독점 모델(ChatGPT, GPT-4) 간의 성능 차이가 평가 설정 전반에서 어떤가?
주요 결과
- 다양한 지시 데이터셋이 서로 다른 능력을 향상시켜 주며, 단일 데이터셋이 모든 작업에서 뛰어나지 않다.
- 더 큰 기본 모델이 일반적으로 지시 튜닝 후 더 나은 성능을 보이고, 기본 모델 품질이 지배적인 요인이다.
- 고품질 개방 데이터의 혼합(Tülu)이 벤치마크 전반에서 최상의 평균 성능을 달성하지만, 그들의 구성에서 평균적으로 ChatGPT나 GPT-4를 이기지는 못한다.
- 다양한 데이터에 대해 미세조정된 65B 개방 모델도 독점 모델에 미치지 못해 여전히 격차가 있다.
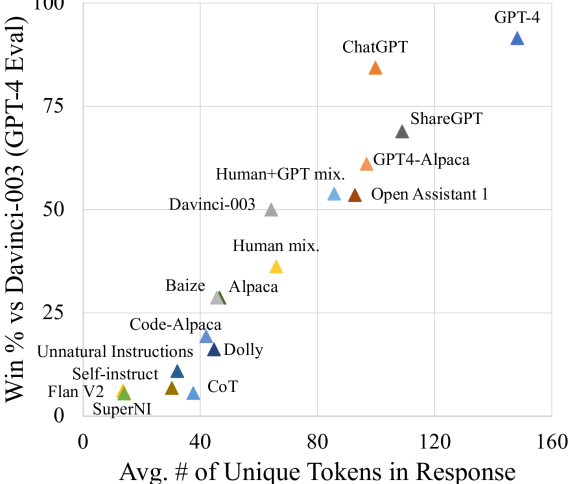
- 모델 기반 선호 신호는 생성 길이와 상관관계가 있어, 이러한 평가에 편향이 있을 수 있음을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.