[논문 리뷰] How well do Large Language Models perform in Arithmetic tasks?
본 연구는 다양한 연산에 걸쳐 LLM의 수치 계산 능력을 평가하기 위한 산술 데이터셋 MATH 401를 소개한다; GPT-4와 ChatGPT가 가장 높은 정확도를 달성함을 보이고, 토크나이제이션, 사전 학습, 프롬프트, 스케일링 등의 요인을 분석한다.
Large language models have emerged abilities including chain-of-thought to answer math word problems step by step. Solving math word problems not only requires abilities to disassemble problems via chain-of-thought but also needs to calculate arithmetic expressions correctly for each step. To the best of our knowledge, there is no work to focus on evaluating the arithmetic ability of large language models. In this work, we propose an arithmetic dataset MATH 401 to test the latest large language models including GPT-4, ChatGPT, InstrctGPT, Galactica, and LLaMA with various arithmetic expressions and provide a detailed analysis of the ability of large language models. MATH 401 and evaluation codes are released at \url{https://github.com/GanjinZero/math401-llm}.
연구 동기 및 목표
- LLM의 산술 능력을 수학적 추론 역량의 대리 지표로 평가해야 할 필요성을 제고한다.
- 정수, 소수, 무리수, 그리고 긴 표현식을 포함하는 산술 평가 도구인 MATH 401을 소개한다.
- 아키텍처 선택과 학습 데이터가 LLM의 산술 성능에 어떠한 영향을 미치는지 분석한다.
- 산술 결과를 개선하기 위한 프롬프트, 시스템 메시지 및 프롬팅 전략에 대한 지침을 제공한다.
제안 방법
- 덧셈, 뺄셈, 곱셈, 나눗셈, 거듭제곱, 삼각함수, 로그, 그리고 긴 대괄호 표현을 포함하는 401개의 산술 표현식을 구성한다.
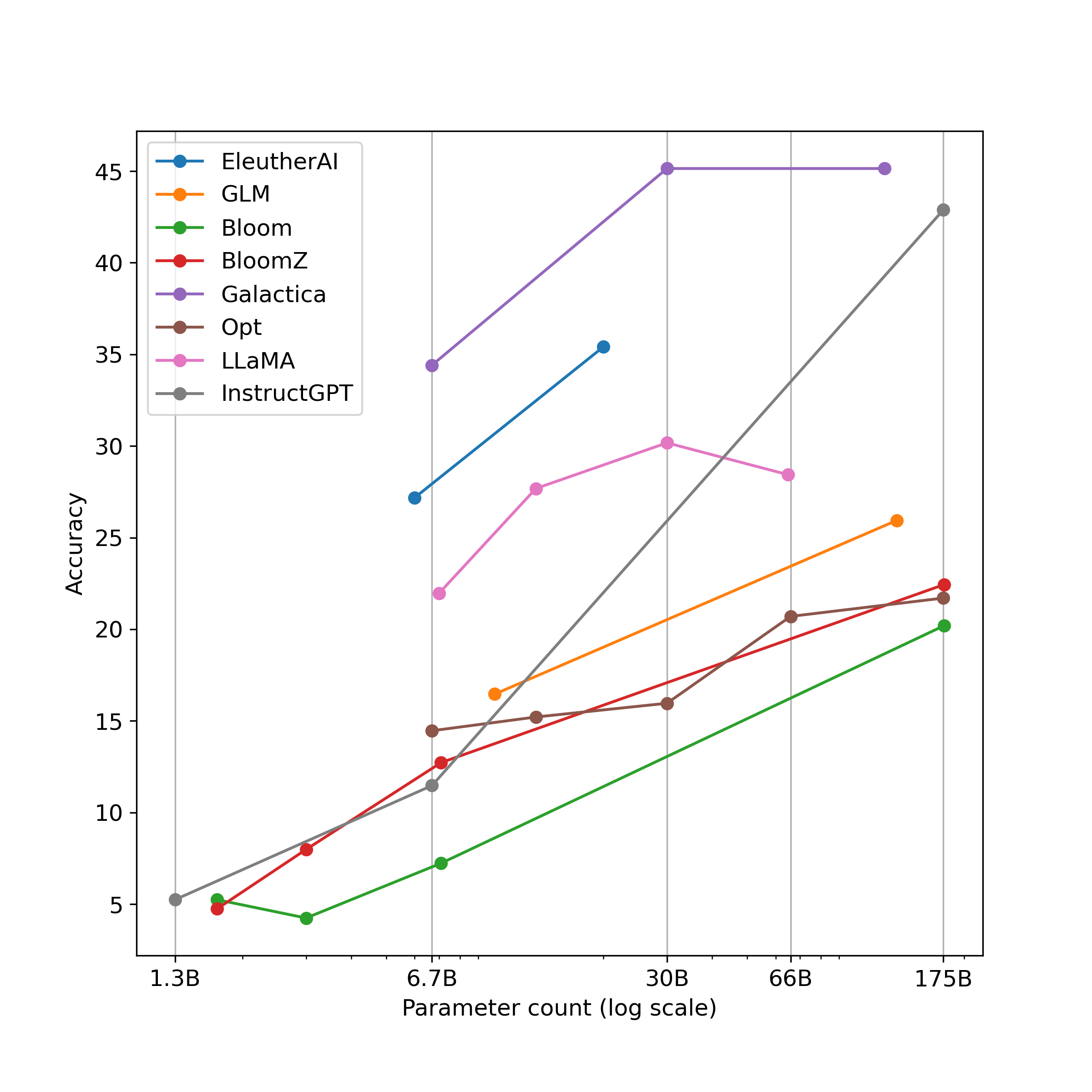
- 다양한 프롬프트와 입력 형식 하에서 광범위한 LLM들(GPT-4, ChatGPT, InstructGPT, Galactica, LLaMA, OPT, Bloom 등)을 평가한다.
- 정확도, 상대 오차, 비숫자 비율을 지표로 사용하고 소수점 네 자리 반올림 및 해독된 숫자에 대한 특정 처리 규정을 둔다.
- 토크나이제이션 효과, 사전 학습 데이터(코드 및 LaTeX 소스), 지시 미세조정 및 RLHF가 산술 성능에 미치는 영향을 비교한다.
- 산술 작업에서 보간/외삽, 스케일링 법칙, 사고 흐름(COT) 효과 및 맥락 학습(ICL)을 조사한다.
실험 결과
연구 질문
- RQ1다양한 연산자 및 수치 형태에 걸친 산술 작업에서 현행 대형 언어 모델의 역량은 어느 정도인가?
- RQ2토크나이제이션, 학습 데이터, 프롬프트, 스케일링 등 어떤 요인들이 LLM의 산술 성능에 영향을 미치는가?
- RQ3사고 흐름(COT) 프롬프트나 시스템 차원의 프롬프트가 산술 정확도를 의미 있게 향상시키는가?
- RQ4지시 미세조정과 ICL이 산술 능력을 의미 있게 향상시킬 수 있으며 모델 크기가 결과에 어떤 영향을 미치는가?
- RQ5모델은 쉬운 산술 그룹과 어려운 산술 그룹에서 어떻게 성능을 보이며 긴 표현식으로 외삽하는가?
주요 결과
- GPT-4와 ChatGPT가 산술 과제 전반에서 다른 모든 모델보다 큰 차이로 우수하다.
- 나눗셈, 소수를 이용한 거듭제곱, 삼각법 및 로그는 대부분 모델에서 여전히 도전적이다; 큰 수 및 긴 표현식은 GPT-4와 ChatGPT가 더 잘 처리한다.
- 토크나이제이션 전략(예: 숫자 수준 대 분리 토큰)이 산술 정확도에 상당한 영향을 미치며, 숫자를 자릿수로 분리하는 모델은 다르게 수행하는 경향이 있다.
- 지시 미세조정 및 RLHF(InstructGPT 및 ChatGPT에 해당)로 인해 초기 사전 학습 또는 SFT 모델에 비해 산술 능력이 향상된다.
- 프롬프트의 중요성: LaTeX 또는 수학 텍스트 프롬프트가 많은 모델에서 일반적으로 더 나은 결과를 낳으며; 시스템 프롬프트는 ChatGPT의 정확도를 크게 향상시키고 비숫자 해독을 줄인다.
- COT 프롬프트는 산술 성능을 일관되게 향상시키지 않으며, 간단한 계산 프롬프트가 긴 표현식에서 때때로 더 나은 결과를 낳는다.
- 스케일링은 어느 정도까지는 도움이 되지만; 약 300억 매개변수 이후에는 일부 모델에서 이득이 정체되는 반면(Galactica 등), GPT-4/ChatGPT는 긴 표현식에서 강한 능력을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.