[논문 리뷰] Impression Network for Video Object Detection
이 논문은 희소한 关键帧에서 고수준 특징을 전파하여 저품질 프레임을 향상시키는 반복적인 인상 특징 집합 메커니즘을 사용하는 새로운 특징 수준의 비디오 객체 검출 프레임워크인 Impression Network를 제안한다. 장거리 세그먼트 간의 최소한의 계산 비용으로 특징을 융합함으로써 20 fps의 추론 속도를 달성하고 ImageNet VID에서 프레임별 기준 모델을 뛰어넘는 정확도를 확보하여 효율적이고 정확한 비디오 특징 향상의 새로운 패러다임을 제시한다.
Video object detection is more challenging compared to image object detection. Previous works proved that applying object detector frame by frame is not only slow but also inaccurate. Visual clues get weakened by defocus and motion blur, causing failure on corresponding frames. Multi-frame feature fusion methods proved effective in improving the accuracy, but they dramatically sacrifice the speed. Feature propagation based methods proved effective in improving the speed, but they sacrifice the accuracy. So is it possible to improve speed and performance simultaneously? Inspired by how human utilize impression to recognize objects from blurry frames, we propose Impression Network that embodies a natural and efficient feature aggregation mechanism. In our framework, an impression feature is established by iteratively absorbing sparsely extracted frame features. The impression feature is propagated all the way down the video, helping enhance features of low-quality frames. This impression mechanism makes it possible to perform long-range multi-frame feature fusion among sparse keyframes with minimal overhead. It significantly improves per-frame detection baseline on ImageNet VID while being 3 times faster (20 fps). We hope Impression Network can provide a new perspective on video feature enhancement. Code will be made available.
연구 동기 및 목표
- 이미지 품질 저하(예: 초점 불량, 운동 흐림) 상황에서도 속도와 정확도의 상충 관계를 해결하기 위해.
- 높은 계산 비용 없이도 장거리 다중 프레임 특징 융합을 효율적으로 가능하게 하기 위해.
- 인간의 시각 인지 방식을 모방하여 시간적 인상의 누적을 통해 저품질 프레임의 검출 성능을 향상시키기 위해.
- 실시간 추론 속도를 유지하면서도 프레임별 검출 기준 모델을 뛰어넘는 성능을 달성하기 위해.
- 하나의 작업에 종속되지 않는 특징 수준의 프레임워크를 제공하여 후속 검출 작업을 위한 비디오 특징 품질을 향상시키기 위해.
제안 방법
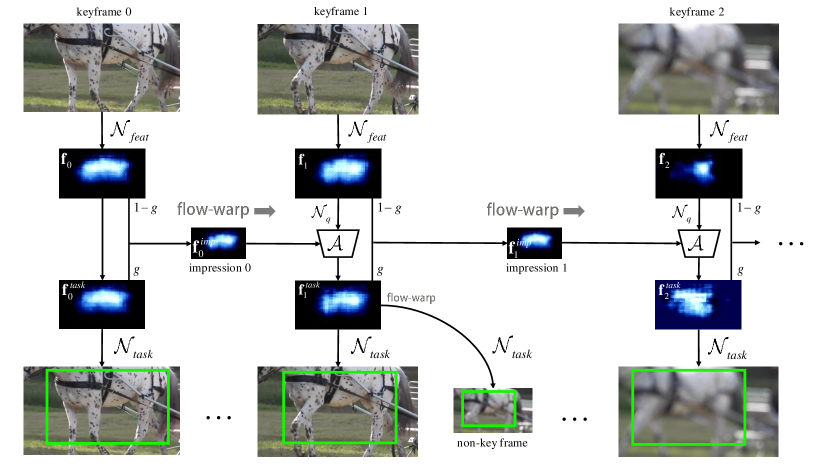
- 프레임워크는 비디오를 고정 길이의 세그먼트로 나누고, 각 세그먼트의 중심에 위치한 하나의 关键帧을 선택하여 ResNet-101과 같은 백본을 사용해 고차원 특징을 추출한다.
- 유동 지도 특징 전파 메커니즘이 비-關键프레임으로도 关键프레임의 특징을 재사용하여 실시간 속도를 유지한다.
- 각 새로운 关键프레임의 특징을 수용함으로써 인상 특징이 반복적으로 업데이트되며, 이는 고수준 객체 신호의 누적 메모리 역할을 한다.
- 각 关键프레임의 작업 특징은 자체 특징과 전파된 인상 특징의 가중 조합으로 구성되며, 이는 품질이 낮은 프레임의 특징 향상 기능을 가능하게 한다.
- 인상 특징은 다음과 같은 재귀적 집합 규칙로 업데이트된다: $ I_{t} = (1-g)I_{t-1} + g \cdot f_t $, 여기서 $ g $ 는 시간적 영향 범위를 제어한다.
- 메서드는 세그먼트 쌍당 한 번의 유동 추정만 필요로 하여 공간 정렬 비용을 최소화하고, 효율적인 장거리 융합을 가능하게 한다.
실험 결과
연구 질문
- RQ1시간적 맥락을 활용함으로써 특징 수준의 방법이 비디오 객체 검출에서 높은 속도와 높은 정확도를 동시에 달성할 수 있는가?
- RQ2추론 속도를 희생시키지 않고도 장거리 특징 융합을 어떻게 효율적으로 수행할 수 있는가?
- RQ3과거 특징의 누적 인상이 시각적 신호가 약한 저품질 프레임의 검출 성능을 어느 정도 향상시킬 수 있는가?
- RQ4유동 지도 특징 전파 오차를 최소화하기 위해 최적의 关键프레임 선택 전략은 무엇인가?
- RQ5기존의 특징 집합 및 전파 기법에 비해 인상 메커니즘은 정확도와 효율성 측면에서 어떻게 비교되는가?
주요 결과
- Impression Network는 20 fps의 추론 속도를 확보하여 프레임별 기준 모델보다 3배 빠르며, 정확도도 크게 향상시켰다.
- FGFA와 같은 최신 집합 기반 방법보다도 뛰어난 성능을 보였으며, ImageNet VID에서 단지 50ms의 추론 시간에 75.5% mAP를 달성했다.
- 인상 메커니즘은 앞선 关键프레임에서 유도된 고품질 특징을 전파하여 초점 불량 및 흐림 프레임의 검출 성능을 향상시키며, 그 결과는 그림 5와 그림 1에서 확인할 수 있다.
- 집합 가중치 $ g $ 를 1.0으로 설정하면 전체 시간적 맥락을 활용할 수 있으며, 이는 가장 높은 mAP를 기록함으로써 장거리 특징 융합이 강건성을 향상시킨다는 것을 시사한다.
- 중앙 关键프레임 선택 전략은 평균 특징 전파 거리 $ \bar{d} $ 를 최소화하여 유동 오차를 감소시키고 성능 향상을 이끌어내며, 이는 표 2에서 확인되었다.
- 다양한 세그먼트 길이에 걸쳐 매끄러운 정확도-속도 트레이드오프를 유지하며, 고속 영역에서 프레임별 기준 모델과 Deep Feature Flow를 모두 능가하는 성능을 보였다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.