[논문 리뷰] Improving Assessment of Tutoring Practices using Retrieval-Augmented Generation
이 논문은 GPT 모델의 프롬프트 전략을 평가하여 튜터의 사회정서 학습 역량을 자동으로 평가하는 것을 다루며, RAG 기반 프롬프트가 특히 GPT-4와 함께 정확도(낮은 환각)와 비용 사이의 균형을 가장 잘 맞춘다는 것을 발견한다.
One-on-one tutoring is an effective instructional method for enhancing learning, yet its efficacy hinges on tutor competencies. Novice math tutors often prioritize content-specific guidance, neglecting aspects such as social-emotional learning. Social-emotional learning promotes equity and inclusion and nurturing relationships with students, which is crucial for holistic student development. Assessing the competencies of tutors accurately and efficiently can drive the development of tailored tutor training programs. However, evaluating novice tutor ability during real-time tutoring remains challenging as it typically requires experts-in-the-loop. To address this challenge, this preliminary study aims to harness Generative Pre-trained Transformers (GPT), such as GPT-3.5 and GPT-4 models, to automatically assess tutors' ability of using social-emotional tutoring strategies. Moreover, this study also reports on the financial dimensions and considerations of employing these models in real-time and at scale for automated assessment. The current study examined four prompting strategies: two basic Zero-shot prompt strategies, Tree of Thought prompt, and Retrieval-Augmented Generator (RAG) based prompt. The results indicate that the RAG prompt demonstrated more accurate performance (assessed by the level of hallucination and correctness in the generated assessment texts) and lower financial costs than the other strategies evaluated. These findings inform the development of personalized tutor training interventions to enhance the the educational effectiveness of tutored learning.
연구 동기 및 목표
- 튜터의 사회정서 학습에 대한 정확한 평가를 촉진하여 개인화된 훈련을 안내한다.
- GPT 모델이 튜터의 트레이닝 기록에서 초보 튜터의 사회정서적 관행을 신뢰할 수 있게 평가할 수 있는지 탐구한다.
- 실시간 평가에서 정확도와 비용 측면에서 프롬프트 전략(제로샷, 트리 오브 소우트, RAG)을 비교한다.
제안 방법
- 초보 튜터와 함께하는 Zoom 세션의 실제 중학교 6-8학년 튜터링 트랜스크립트를 사용한다.
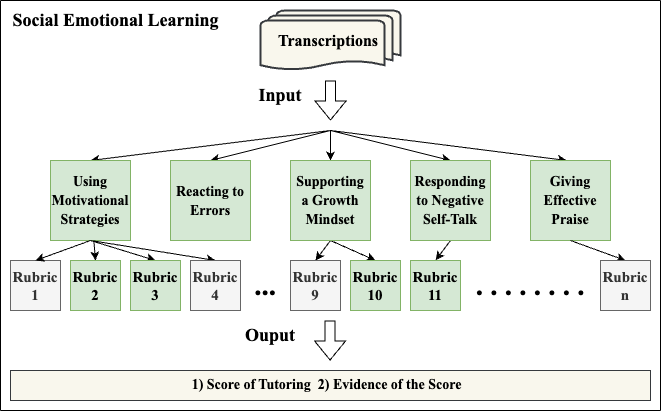
- 다섯 가지 사회정서 학습 원칙에 기반한 루브릭을 개발하여 튜터링 관행을 평가한다.
- 네 가지 프롬프트 전략을 설계하고 비교한다: 두 가지 기본 제로샷 프롬프트, Tree of Thought 프롬프트, Retrieval-Augmented Generator (RAG) 프롬프트.
- 사람의 판단에 대한 정확성과 환각 여부를 GPT 출력과 비교하여 주석을 달아 평가한다.
- API 가격을 사용하여 GPT-3.5 Turbo와 GPT-4 Turbo의 평가당 비용을 계산한다.
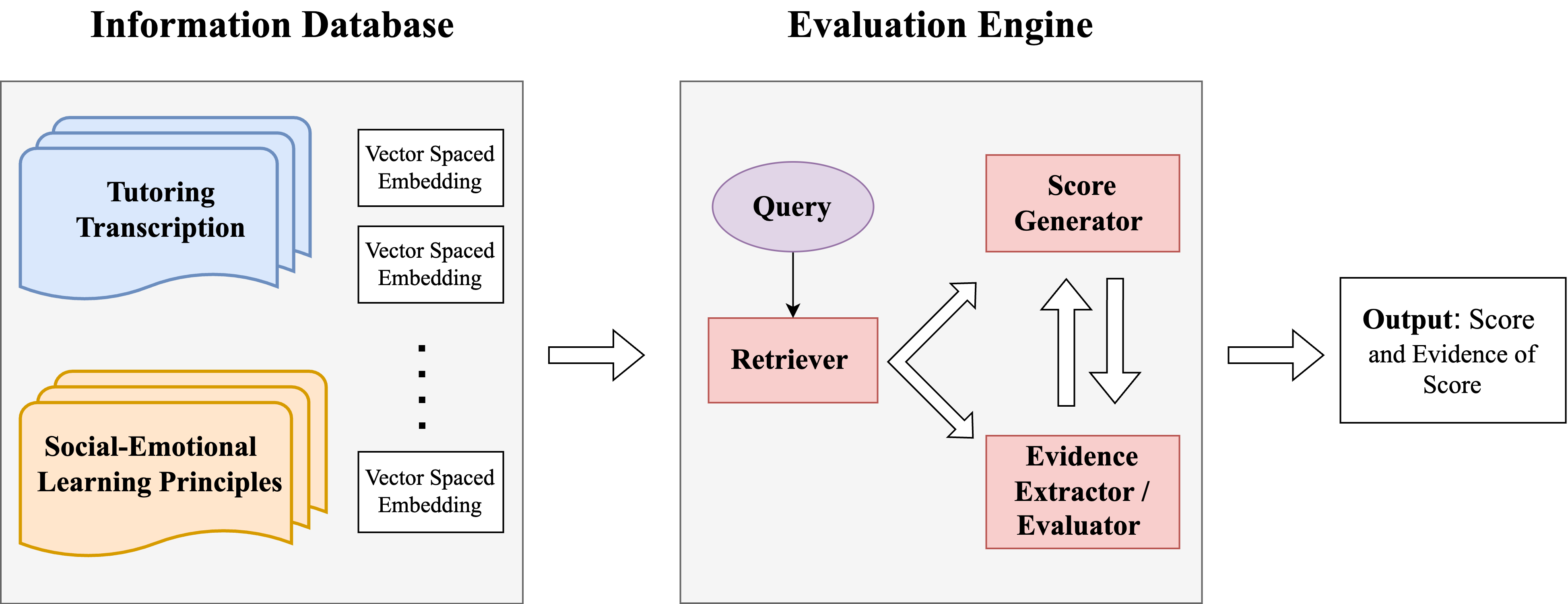
실험 결과
연구 질문
- RQ1RQ1: GPT 모델이 인간 튜터의 사회정서 학습 역량을 정확하게 평가할 수 있는가?
- RQ2RQ2: 이 작업에서 GPT-3.5와 GPT-4의 성능 및 비용은 어떻게 비교되는가?
주요 결과
| 프롬프트 | GPT-3.5 Turbo | GPT-4 Turbo |
|---|---|---|
| Zero-shot Prompt Type I | $0.100 | $1.035 |
| Zero-shot Prompt Type II | $0.014 | $0.188 |
| Tree of Thoughts (ToT) | $0.013 | $0.137 |
| Retrieval-Augmented Generation (RAG) | $0.008 | $0.137 |
- RAG 프롬프트는 다른 프롬프트에 비해 환각이 적고 평가의 정확도가 더 높은 경향이 있다(모델 전반에 걸쳐).
- GPT-4는 일반적으로 GPT-3.5보다 더 정확한 평가를 제공하며, RAG 및 제로샷(P1) 프롬프트가 가장 우수하게 작동한다.
- RAG 프롬프트는 GPT-3.5와 GPT-4 모두에서 가장 비용 효율적인 평가 전략을 제공한다.
- GPT-3.5는 때때로 환각이 나타났으며(예: 부정적 자기대화에 대한 반응 잘못 식별 등).
- GPT-4 결과는 프롬프트 전략 전반에서 인간 판단과의 정렬도가 더 높음을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.