[논문 리뷰] Improving Factuality and Reasoning in Language Models through Multiagent Debate
본 논문은 여러 LLM 인스턴스가 여러 라운드에 걸쳐 응답을 생성, 비판하고 토론하는 다중 에이전트 대화 프레임워크를 제안하여 추론 및 사실성 향상을 도모하고, 단일 모델 기준선에 비해 추론 및 사실성 과제에서 상당한 이점을 달성한다.
Large language models (LLMs) have demonstrated remarkable capabilities in language generation, understanding, and few-shot learning in recent years. An extensive body of work has explored how their performance may be further improved through the tools of prompting, ranging from verification, self-consistency, or intermediate scratchpads. In this paper, we present a complementary approach to improve language responses where multiple language model instances propose and debate their individual responses and reasoning processes over multiple rounds to arrive at a common final answer. Our findings indicate that this approach significantly enhances mathematical and strategic reasoning across a number of tasks. We also demonstrate that our approach improves the factual validity of generated content, reducing fallacious answers and hallucinations that contemporary models are prone to. Our approach may be directly applied to existing black-box models and uses identical procedure and prompts for all tasks we investigate. Overall, our findings suggest that such "society of minds" approach has the potential to significantly advance the capabilities of LLMs and pave the way for further breakthroughs in language generation and understanding.
연구 동기 및 목표
- 동기: 대형 언어 모델(LLMs)의 환각 및 추론 오류를 해결하는 동기를 제시합니다.
- 제안: 여러 LLM 인스턴스가 서로의 솔루션을 생성하고 비판하는 다중 에이전트 토론 프레이크워크를 제안합니다.
- 시연: 블랙박스 모델 접근만으로 다양한 태스크에서 추론 및 사실 정확도를 향상시킵니다.
제안 방법
- 주어진 작업에 대해 동일한 LLM 에이전트들을 다수 또는 다양한 구성으로 인스턴스화한다.
- 각 에이전트는 독립적으로 후보 해답을 생성한다.
- 에이전트들은 서로의 응답을 읽고 비판하며 다수의 라운드에 걸쳐 합의에 도달하도록 반복한다.
- 토론 길이와 에이전트의 고집도를 제어하기 위한 프롬프트를 사용하여 수렴에 영향을 준다.
- 다른 프롬프트 방법들과의 직교성을 시연하고 체인-오브-사고(Chain-of-Thought) 프롬팅과 결합한다.
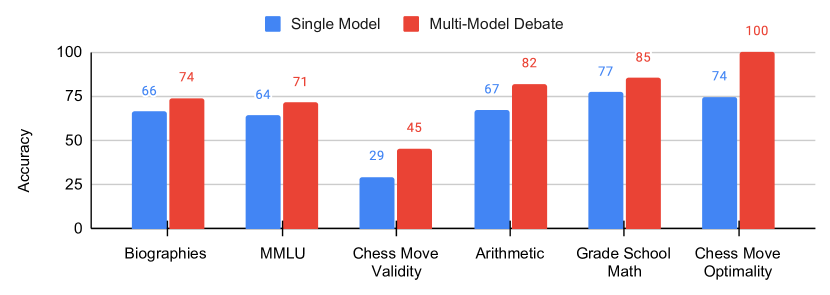
실험 결과
연구 질문
- RQ1다중 에이전트 토론이 단일 에이전트 기준선에 비해 추론 성능을 향상시키는가?
- RQ2토론 프레임워크가 다양한 태스크에서 사실 정확도 향상 및 환각 감소에 기여하는가?
- RQ3어떤 설계 선택(에이전트 수, 라운드 수, 프롬프트)이 성능을 최적화하는가?
- RQ4이 접근법이 다른 프롬프트 전략 및 모델 유형과 호환되는가?
- RQ5개별 에이전트가 불확실하거나 잘못되었을 때도 강인한 합의를 생성할 수 있는가?
주요 결과
| 모델 | 산술 (%) ↑ | 초등 수학 (%) ↑ | 체스 (Δ PS) ↑ |
|---|---|---|---|
| Single Agent | 67.0 ± 4.7 | 77.0 ± 4.2 | 91.4 ± 10.6 |
| Single Agent (Reflection) | 72.1 ± 4.5 | 75.0 ± 4.3 | 102.1 ± 11.9 |
| Multi-Agent (Majority) | 69.0 ± 4.6 | 81.0 ± 3.9 | 102.2 ± 6.2 |
| Multi-Agent (Debate) | 81.8 ± 2.3 | 85.0 ± 3.5 | 122.9 ± 7.6 |
- 다중 에이전트 토론은 산술, GSM8K, 체스 수순 예측에서 단일 에이전트 기준선 및 반성(reflection) 대비 추론을 크게 향상시킨다. (산술: 81.8±2.3; GSM8K: 85.0±3.5; 체스: 122.9±7.6, ΔPS 지표에서 토론 대 baselines)
- 토론은 자서전, MMLU, 체스 타당성 태스크에서도 사실 정확도를 향상시키며 반성 및 단일 에이전트 접근법보다 우수하다. (자서전: 73.8±2.3; MMLU: 71.1±4.6; 체스 타당성: 45.2±2.9)
- 에이전트 수와 토론 라운드를 늘리면 일반적으로 성능이 향상되지만 어느 시점을 넘으면 수익이 감소한다.
- 길이가 긴 토론 프롬프트는 수렴 속도를 늦추지만 더 높은 품질의 합의를 도출할 수 있다.
- 다른 초기화 프롬프트(에이전트 페르소나)가 특정 태스크에서 추가 이득을 낳을 수 있다.
- 토론은 초기 답변이 잘못된 경우에도 합의로 수렴하게 하고, 불확실한 사실의 포함을 줄일 수 있다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.