[논문 리뷰] Improving Retrieval for RAG based Question Answering Models on Financial Documents
이 논문은 금융 문서에 대한 표준 RAG 파이프라인의 한계를 분석하고 검색 품질을 개선하기 위한 기법들을 제안합니다. 고급 청크화, 쿼리 확장(HyDE), 메타데이터 주석, 재랭킹, 임베딩 미세조정을 포함합니다.
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
연구 동기 및 목표
- 도메인 특화(금융) QA 작업에서 현재 RAG 파이프라인의 한계를 식별한다.
- 맥 context 품질 및 답변 정확도 향상을 위한 검색 개선안을 제안하고 평가한다.
- 금융 중심 Q&A에서 환각 현상을 완화하고 신뢰성을 높이는 기술을 입증한다.
제안 방법
- RAG 파이프라인에서 균일한 청크화와 코사인 유사도 기반 검색의 한계를 비판적으로 검토한다.
- 문서 구조(예: 제목, 표)로 재귀적으로 구분하는 적응형 청크화 전략을 제안한다.
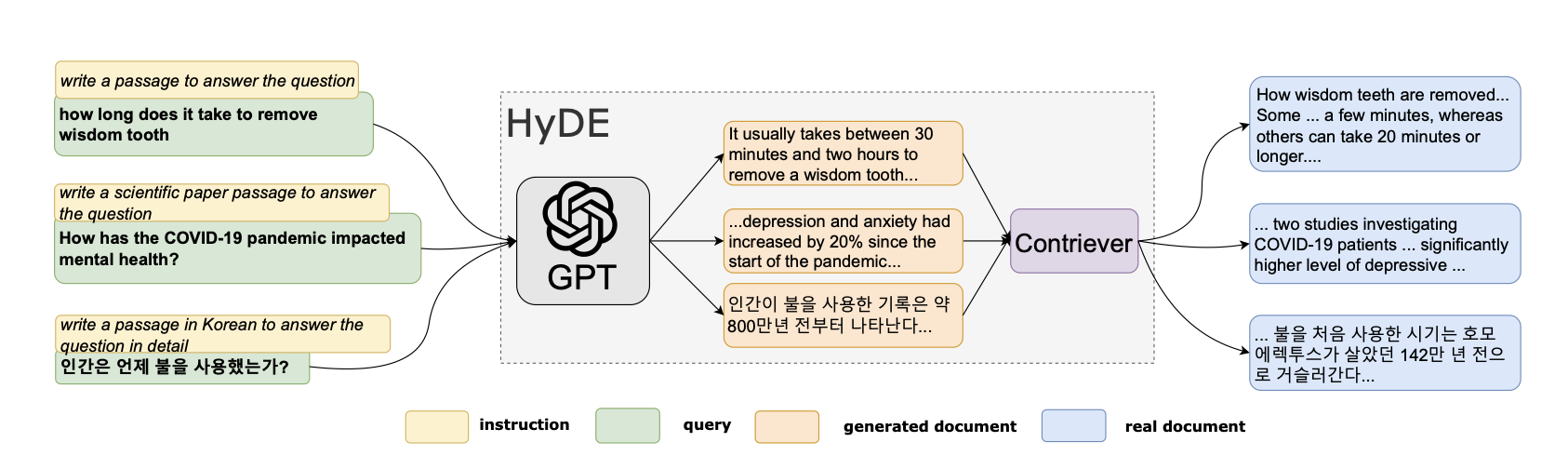
- 검색 가이드 개선을 위한 Hypothetical Document Embeddings(HyDE)와 함께 쿼리 확장을 탐구한다.
- 문서의 정체성과 맥락을 보존하기 위해 메타데이터 주석과 문서별 인덱싱을 도입한다.
- 재랭킹 알고리즘을 적용하여 단순한 유사성보다 실제로 관련성이 높은 청크를 우선순위화한다.
- 도메인 특화 데이터로 임베딩을 미세 조정하여 금융 용어와 뉘앙스를 포착한다.
실험 결과
연구 질문
- RQ1현재의 RAG 파이프라인이 다-document 금융 Q&A 작업에서 어떤 한계에 직면하는가?
- RQ2청크화, HyDE, 메타데이터, 재랭킹, 도메인 특화 임베딩 등 개선된 검색 전략이 금융 문서의 답변 품질과 신뢰성을 향상시킬 수 있는가?
- RQ3구조화된 금융 데이터셋에서 검색 품질과 답변 충실도를 가장 잘 포착하는 평가 전략은 무엇인가?
주요 결과
- 일관된 청크화에서 문서 구조 인지형 청크화로 전환함으로써 검색 품질과 답변 충실도를 향상시킬 수 있다.
- HyDE 스타일의 쿼리 확장이 사용자의 원래 질문을 넘어선 맥락을 찾아 검색 오류를 줄이는 데 도움이 된다.
- 메타데이터 주석은 문서 간 혼동을 줄이고 여러 문서에 걸친 맥락 보존을 향상시킨다.
- 재랭킹은 단순한 유사성보다 맥락 관련성을 우선시하여 검색된 청크의 품질을 향상시킨다.
- 도메인 데이터에 대한 임베딩 미세 조정은 금융 특화 맥락에서 검색 성능을 향상시킬 수 있다.
- FinanceBench (10-K, 10-Q, 8-K, earnings reports) 는 검색 및 QA 성능의 구조화된 평가를 위한 ground-truth를 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.