[논문 리뷰] #InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models
InsTag 자동으로 open-set SFT 쿼리를 태깅하여 지시 다양성과 복잡성을 정량하고, 복잡성 중심의 데이터 선택기를 사용해 TagLM 모델을 학습시켜 비교적 적은 SFT 데이터로 MT-Bench에서 강력한 성능을 달성한다.
Foundation language models obtain the instruction-following ability through supervised fine-tuning (SFT). Diversity and complexity are considered critical factors of a successful SFT dataset, while their definitions remain obscure and lack quantitative analyses. In this work, we propose InsTag, an open-set fine-grained tagger, to tag samples within SFT datasets based on semantics and intentions and define instruction diversity and complexity regarding tags. We obtain 6.6K tags to describe comprehensive user queries. Then we analyze popular open-sourced SFT datasets and find that the model ability grows with more diverse and complex data. Based on this observation, we propose a data selector based on InsTag to select 6K diverse and complex samples from open-source datasets and fine-tune models on InsTag-selected data. The resulting models, TagLM, outperform open-source models based on considerably larger SFT data evaluated by MT-Bench, echoing the importance of query diversity and complexity. We open-source InsTag in https://github.com/OFA-Sys/InsTag.
연구 동기 및 목표
- SFT 데이터의 다양성과 복잡성을 정량하기 위해 세밀하고 open-set 지시 태그를 정의한다.
- ChatGPT와 정규화를 이용한 자동 태깅 파이프라인을 개발해 고품질 태그를 산출한다.
- 개방형 오픈소스 SFT 데이터세트를 분석해 다양성과 복잡성이 정렬 성능과 어떻게 상관관계가 있는지 밝힌다.
- SFT를 위한 다양하고 복잡한 샘플을 선별하는 InsTag 기반 데이터 셀렉터를 제안한다.
- InsTag-selected 데이터로 파인튜닝된 TagLM 모델이 MT-Bench에서 일부 기준선보다 우수하다는 것을 시연한다.
제안 방법
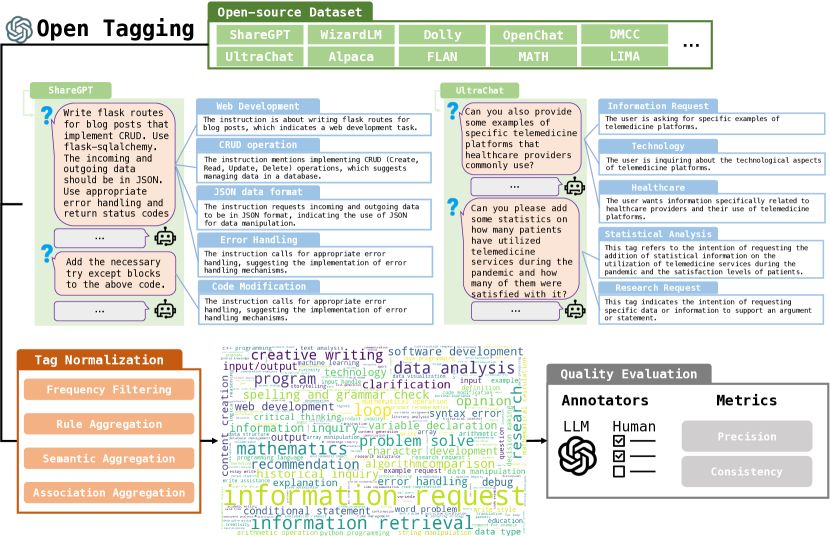
- ChatGPT에 오픈셋 세밀한 의도 태그로 쿼리를 주석 달도록 지시한다.
- 주파수 필터링, 규칙 집계, 의미적 클러스터링(DBSCAN), 연관성 집계(FP-Growth) 등을 통해 원시 태그를 정규화한다.
- 정밀도와 일관성 지표를 사용해 GPT-4와 인간 주석가로 태깅 품질을 평가한다.
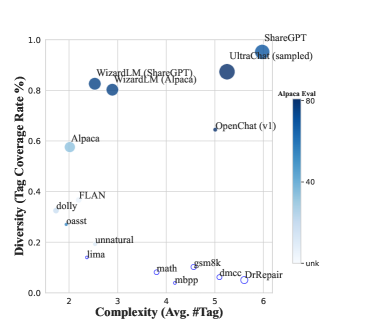
- 고유 태그 커버리지, 쿼리당 평균 태그 수 등 태그 기반 지표로 데이터셋의 다양성과 복잡성을 분석한다.
- Algorithm 1(복잡도 우선 다양성 샘플링)로 6K 개의 고복잡도/다양성 쿼리를 SFT에 샘플링한다.
- InsTag-selected 데이터로 13B LLaMA/LLaMA-2 모델을 파인튜닝하고 MT-Bench로 평가한다.
실험 결과
연구 질문
- RQ1open-set의 세밀한 지시 태깅이 SFT 데이터셋의 다양성과 복잡성을 효과적으로 정량화할 수 있는가?
- RQ2SFT 데이터의 더 높은 지시 다양성과 복잡성이 향상된 LLM 정렬 성능과 상관관계가 있는가?
- RQ3InsTag 기반 데이터 선택이 기준선 대비 더 적은 SFT 데이터로도 더 나은 성능의 LLM을 낳을 수 있는가?
- RQ4InsTag-selected 데이터로 학습된 TagLM 모델은 MT-Bench에서 독점형 및 오픈 소스 기준선과 어떻게 비교되는가?
주요 결과
| 모델 | 데이터 크기 | MT-Bench |
|---|---|---|
| gpt-4 | - | 8.99 |
| gpt-3.5-turbo | - | 7.94 |
| claude-v1 | - | 7.90 |
| Llama-2-13b-chat | - | 6.65 |
| TagLM-13b-v2.0 | 6K | 6.55±0.02 |
| alpaca-13b | 52K | 4.53 |
| openchat-13b-v1 | 8K | 5.22 |
| baize-v2-13b | 56K | 5.75 |
| vicuna-13b-v1.1 | 70K | 6.31 |
| wizardlm-13b | 70K | 6.35 |
| vicuna-13b-v1.3 | 125K | 6.39 |
| TagLM-13b-v1.0 | 6K | 6.44±0.04 |
- InsTag는 정규화 후 약 6,587개의 원자 태그를 산출하여 SFT 데이터의 다양성과 복잡성 분석을 가능하게 한다.
- 태그 다양성과 복잡성이 높은 데이터세트일수록 MT-Bench 정렬 성능과 더 높은 상관관계가 있다.
- TagLM-13b-v1.0 (6K 데이터)는 MT-Bench 6.44±0.04를 달성해 더 큰 데이터 크기를 가진 많은 오픈소스 정렬 LLM을 능가한다.
- TagLM-13b-v2.0 (6K 데이터)는 MT-Bench 6.55±0.02를 달성해 LLaMA-2 chat 성능에 근접하고 RLHF-튜닝된 등가에 가깝다.
- InsTag-selected 데이터로 학습된 모델은 상당히 더 많은 SFT 데이터를 사용하는 오픈자원 기준선보다 우수한 성능을 낸다.
- InsTag의 태깅 품질은 높은 정밀도와 일관성을 보인다(GPT-4: 96.1% precision, 86.6% consistency; 인간 주석가들은 다수결에서 일치한다).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.