[논문 리뷰] INSTRUCTEVAL: Towards Holistic Evaluation of Instruction-Tuned Large Language Models
InstructEval은 문제 해결, 작문, 인간 가치에의 정합성에 걸쳐 지시-미세조정된 LLM을 평가하는 총체적 벤치마크를 제공합니다. 사전 학습, 지시 데이터, 학습 방법의 영향을 분석합니다.
Instruction-tuned large language models have revolutionized natural language processing and have shown great potential in applications such as conversational agents. These models, such as GPT-4, can not only master language but also solve complex tasks in areas like mathematics, coding, medicine, and law. Despite their impressive capabilities, there is still a lack of comprehensive understanding regarding their full potential, primarily due to the black-box nature of many models and the absence of holistic evaluation studies. To address these challenges, we present INSTRUCTEVAL, a more comprehensive evaluation suite designed specifically for instruction-tuned large language models. Unlike previous works, our evaluation involves a rigorous assessment of models based on problem-solving, writing ability, and alignment to human values. We take a holistic approach to analyze various factors affecting model performance, including the pretraining foundation, instruction-tuning data, and training methods. Our findings reveal that the quality of instruction data is the most crucial factor in scaling model performance. While open-source models demonstrate impressive writing abilities, there is substantial room for improvement in problem-solving and alignment. We are encouraged by the rapid development of models by the open-source community, but we also highlight the need for rigorous evaluation to support claims made about these models. Through INSTRUCTEVAL, we aim to foster a deeper understanding of instruction-tuned models and advancements in their capabilities. INSTRUCTEVAL is publicly available at https://github.com/declare-lab/instruct-eval.
연구 동기 및 목표
- 전통적 벤치마크를 넘어 지시-미세조정된 LLM의 총체적 역량 평가.
- 사전 학습 기반, 지시 데이터, 학습 방법이 성능에 어떤 영향을 미치는지 분석합니다.
- 모델 능력을 가장 효과적으로 확장시키는 요인 식별.
- 포괄적 평가 프레임워크와 순위표에 대한 오픈 소스 접근성 제공.
제안 방법
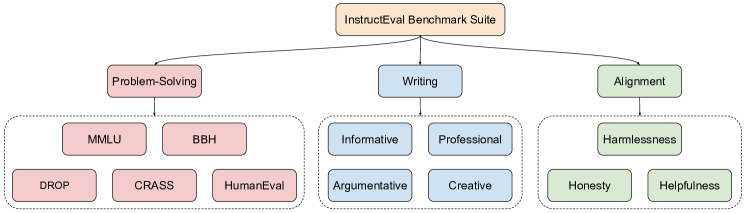
- 문제 해결, 작문, 그리고 인간 가치 정합성을 다루는 총체적 평가 체계를 정의합니다.
- 자동 평가와 인간-반복 평가를 포함한 다수의 객관적 및 주관적 평가 방법을 사용합니다.
- 표준화된 벤치마크(MMLU, BBH, DROP, CRASS, HumanEval, HHH, 및 영향력 있는 작문 데이터셋)를 사용하여 60개 이상의 오픈 소스 지시 LLM을 비교합니다.
- 기초 모델 크기, 지시 데이터 품질, 학습 방법(감독학습 vs RLHF, 매개변수 효율적 미세조정)의 효과를 분석합니다.
- 작업 간 적은 샷 대 제로샷 성능 및 인컨텍스트 학습 효과를 조사합니다.
실험 결과
연구 질문
- RQ1지시-튜닝 요소들(기초 모델, 데이터 품질, 학습 방법)이 문제 해결, 작문, 정합성 성능에 어떤 영향을 미치나요?
- RQ2성능 확장에 있어 지시 데이터의 상대적 중요도는 무엇이며, 사전훈련 기반은 어느 정도인가요?
- RQ3오픈 소스 지시 LLM이 작문과 정합성에서 폐쇄형 모델과 대등하거나 근접할 수 있으며, 문제 해결에서 어디에서 뒤처지나요?
- RQ4적은 샷 시연이 작업과 모델 전반에서 일관되게 성능을 향상시키나요?
주요 결과
- 지시 데이터 품질은 성능 확장의 가장 결정적인 요인입니다.
- 오픈 소스 지시 LLM은 작문에서 뛰어나지만 문제 해결 및 정합성에서 상당한 차이를 보입니다.
- 합성 지시를 통해 폐쇄형 모델을 모방하는 것은 한정된 이익을 주며 편향/잡음 확산으로 이어질 수 있습니다.
- 학습 방법(RLHF 등)은 도움이 되지만 일반적으로 지시 데이터보다 영향력이 작으며, 매개변수 효율적 튜닝은 모델 크기에 따라 잘 확장됩니다.
- 적은 샷 시연의 이점이 작업마다 균일하지 않으며, 이점이 작업 의존적이고 때로는 부정적일 수 있습니다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.