[논문 리뷰] Interpretable and Explainable Logical Policies via Neurally Guided Symbolic Abstraction
NUDGE는 pretrained neural policies로 미분 가능 순전Reasoning을 안내하여 해석 가능하고 설명 가능한 논리 정책을 학습하고, 관계형 RL 태스크 전반에서 경쟁력 있는 성능과 강건한 적응을 달성합니다.
The limited priors required by neural networks make them the dominating choice to encode and learn policies using reinforcement learning (RL). However, they are also black-boxes, making it hard to understand the agent's behaviour, especially when working on the image level. Therefore, neuro-symbolic RL aims at creating policies that are interpretable in the first place. Unfortunately, interpretability is not explainability. To achieve both, we introduce Neurally gUided Differentiable loGic policiEs (NUDGE). NUDGE exploits trained neural network-based agents to guide the search of candidate-weighted logic rules, then uses differentiable logic to train the logic agents. Our experimental evaluation demonstrates that NUDGE agents can induce interpretable and explainable policies while outperforming purely neural ones and showing good flexibility to environments of different initial states and problem sizes.
연구 동기 및 목표
- RL에서 해석 가능하고 설명 가능한 정책의 필요성을 동기화한다.
- 논리 기반 정책을 학습하기 위해 뉴럴-가이드 미분 가능 로직 프레임워크(NUDGE)를 제안한다.
- 사전 학습된 신경 정책으로 기호적 추상화를 안내하여 효율적인 규칙 탐색을 가능하게 한다.
- NUDGE가 신경 기반 벤치마크와 경쟁하고 환경 변화에 적응할 수 있음을 입증한다.
- 읽기 쉬운 규칙 세트와 기울기 기반 설명을 통해 해석 가능성을 보여준다.
제안 방법
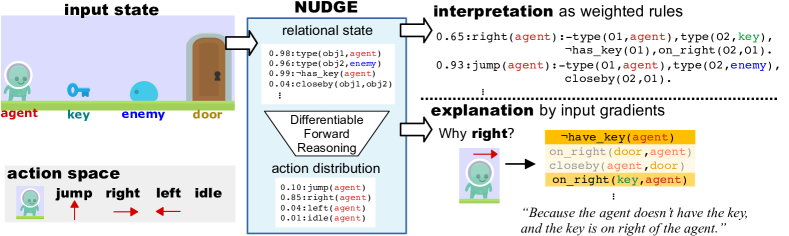
- 액션 술어(state predicate)와 상태 술어를 구분하는 1차 논리(action-state) 언어를 정의한다.
- 확률적 사실로부터 행동 분포를 계산하기 위해 미분 가능 순전Reasoning을 사용한다.
- 신경 정책에 기반한 신경-가이드 기호 추상을 구현하여 후보 규칙의 компакт한 집합을 선택한다.
- 신경 비평가를 통해 반환을 최대화하는 PPO actor-critic 업데이트로 규칙 가중치를 학습한다.
- 확률적 로직 표현에 대한 입력 기여도 점수를 계산하여 기울기 기반 설명을 제공한다.
실험 결과
연구 질문
- RQ1Q1: NUDGE가 표준 및 논리 지향 태스크에서 신경 기반 및 순수 로직 벤치마크와 어떻게 비교되는가?
- RQ2Q2: 재학습 없이 환경 변화에 NUDGE가 어떻게 적응할 수 있는가?
- RQ3Q3: NUDGE 정책이 해석 가능하고 의사결정에 대한 설명을 제공할 수 있는가?
주요 결과
| Score (↑) | Random | DQN | NUDGE |
|---|---|---|---|
| Asterix | 235 ± 134 | 124.5 | 6259 ± 1150 |
| Freeway | 0.0 ± 0 | 25.8 | 21.4 ± 0.8 |
- NUDGE는 여러 로직 환경에서 신경 벤치마크를 능가하거나 일부 환경에서 신경 성능과 맞먹거나 능가한다.
- NUDGE는 재학습 없이도 환경 변화에 대해 강건한 모습을 보인다.
- NUDGE는 가중 규칙 세트로 해석 가능한 정책을 생성하고 행동 선택에 대한 기울기 기반 설명을 가능하게 한다.
- NUDGE는 신경 가이드 추상화를 통해 compact한 규칙 세트와 효율적인 학습을 제공한다.
- NUDGE는 고정된 템플릿에 의존하는 비미분 가능 기호 벤치마크를 크게 능가한다.
- 실험에는 OCAtari 벤치마크와 관계 추론 능력을 보여주는 세 개의 객체 중심 로직 환경이 포함된다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.