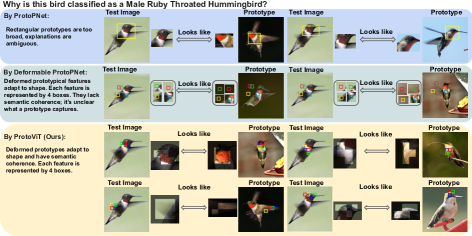
[논문 리뷰] Interpretable Image Classification with Adaptive Prototype-based Vision Transformers
ProtoViT는 Vision Transformer 백본과 적응형 변형 가능한 프로토타입을 결합하여 사례 기반 추론을 통한 해석 가능한 이미지 분류를 가능하게 하며, 프로토타입 기반 모델 중 최첨단 정확도를 달성하는 동시에 일관되고 충실한 설명을 보장합니다.
We present ProtoViT, a method for interpretable image classification combining deep learning and case-based reasoning. This method classifies an image by comparing it to a set of learned prototypes, providing explanations of the form ``this looks like that.'' In our model, a prototype consists of extit{parts}, which can deform over irregular geometries to create a better comparison between images. Unlike existing models that rely on Convolutional Neural Network (CNN) backbones and spatially rigid prototypes, our model integrates Vision Transformer (ViT) backbones into prototype based models, while offering spatially deformed prototypes that not only accommodate geometric variations of objects but also provide coherent and clear prototypical feature representations with an adaptive number of prototypical parts. Our experiments show that our model can generally achieve higher performance than the existing prototype based models. Our comprehensive analyses ensure that the prototypes are consistent and the interpretations are faithful.
연구 동기 및 목표
- 고위험 도메인에서 해석 가능한 이미지 분류기가 필요한 이유를 제시합니다.
- 비전 트랜스포머 백본을 사용하는 프로토타입 기반 프레임워크를 개발합니다.
- 일관되고 충실한 설명을 제공하는 적응적이고 기하학적으로 유연한 프로토타입을 가능하게 합니다.
- 해석 가능성을 보존하면서 정확도를 극대화하는 학습 절차를 제시합니다.
제안 방법
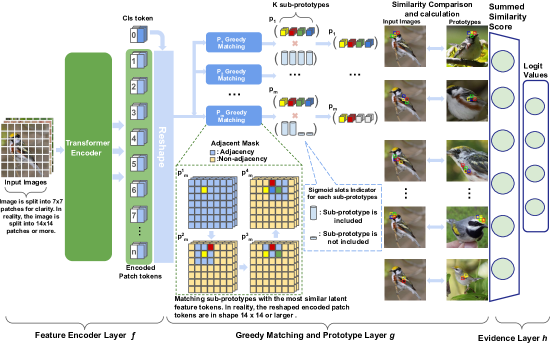
- 이미지 패치에서 latent 토큰을 생성하기 위해 f로서 ViT 백본을 특징 인코더로 사용합니다.
- 프로토타입을 부분 프로토타입의 집합으로 정의하고 탐욕적 매칭 계층 g를 적용해 부분 프로토타입을 잠재 토큰과 짝짓습니다.
- 부분 프로토타입 간 기하학적 연속성을 보장하기 위해 인접성 마스크를 도입합니다.
- 프로토타입당 동적 수의 부분 프로토타입을 허용하는 적응형 슬롯 메커니즘을 도입합니다.
- 시각적 설명을 위해 프로토타입을 가장 가까운 잠재 패치로 투영하고 최종 분류를 위한 증거 계층 h를 최적화합니다.
- 군집, 분리, 일관성, 직교성 항을 포함한 단계적 손실로 훈련한 뒤 프로토타입 가지치기 및 투영 단계를 수행합니다.
실험 결과
연구 질문
- RQ1ProtoViT가 해석 가능성을 유지하면서 기존의 프로토타입 기반 모델보다 더 높은 정확도를 달성할 수 있을까?
- RQ2적응적이고 변형 가능한 프로토타입이 다양한 데이터 세트에서 일관되고 충실한 대표적 설명을 생성하는가?
- RQ3ProtoViT는 시각적 추론에서 기하학적 변이와 위치 정합성 문제를 어떻게 처리하는가?
- RQ4프로토타입 투영이 모델 성능과 해석 가능성에 어떤 영향을 미치는가?
주요 결과
| 아키텍처 | 모델 | CUB 정확도(%) | Car 정확도(%) |
|---|---|---|---|
| ProtoPNet | (9) | 80.1 ± 0.3 | 89.5 ± 0.2 |
| Densenet-161 | Def. ProtoPNet(2x2) (given in [ 10 ] ) | 80.9 ± 0.22 | 88.7 ± 0.3 |
| ProtoPool | (13) | 80.3 ± 0.3 | 90.0 ± 0.3 |
| TesNet | (14) | 81.5 ± 0.3 | 92.6 ± 0.3 |
| Base | (given in [ 23 ] ) | 80.57 | 86.21 |
| DeiT-Tiny | ViT-Net (given in [ 23 ] ) | 81.98 | 88.41 |
| ProtoPFormer | (given in [ 23 ] ) | 82.26 | 88.48 |
| ProtoViT(K=4,r=1) | ours | 82.92 ± 0.5 | 89.02 ± 0.1 |
| Baseline | (given in [ 23 ] ) | 84.28 | 90.06 |
| DeiT-Small | ViT-Net (given in [ 23 ] ) | 84.26 | 91.34 |
| ProtoPFormer | (given in [ 23 ] ) | 84.85 | 90.86 |
| ProtoViT(K=4,r=1) | ours | 85.37 ± 0.13 | 91.84 ± 0.3 |
| Baseline | (given in [ 23 ] ) | 83.95 | 90.19 |
| CaiT-XXS 24 | ViT-Net (given in [ 23 ] ) | 84.51 | 91.54 |
| ProtoPFormer | (given in [ 23 ] ) | 84.79 | 91.04 |
| ProtoViT(K=4,r=1) | ours | 85.82 ± 0.15 | 92.40 ± 0.1 |
- ViT 백본을 사용하는 ProtoViT는 새의 데이터셋과 자동차 데이터셋에서 여러 프로토타입 기반 방법보다 더 높은 정확도를 달성합니다.
- K=4 부분 프로토타입 및 r=1 인접성으로 구성된 ProtoViT는 82.92% CUB 정확도와 89.02% Car 정확도를 달성합니다 (DeiT 백본).
- CaiT-XXS 백본을 사용하는 ProtoViT는 85.82% CUB 정확도와 92.40% Car 정확도를 달성합니다.
- ProtoViT는 동일 백본을 사용하는 다른 프로토타입 기반 모델보다 우수한 정확도를 보이고 실제 이미지 패치에 매핑된 시각적으로 일관된 프로토타입을 제공합니다.
- 글로벌/로컬 분석은 프로토타입이 항상 의미 있는 의미론적 특징에 대응함을 나타냅니다.
- 위치 정합성 벤치마크는 ProtoViT가 PLC, PAC, PRC 측면에서 CNN 기반 프로토타입 모델과 동등하거나 더 우수한 성능을 보이는 동시에 경쟁력 있는 정확도를 유지함을 보여줍니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.