[논문 리뷰] Introducing Bode: A Fine-Tuned Large Language Model for Portuguese Prompt-Based Task
이 논문은 프롬프트 기반 작업을 위한 Portuguese LLM(7B 및 13B) 기반 LLaMA 2를 미세 조정한 Bode를 제시하며, zero-shot 및 인-context 학습을 사용하여 감정 분석, 뉴스 분류, 가짜 뉴스 탐지에 대해 평가한다.
Large Language Models (LLMs) are increasingly bringing advances to Natural Language Processing. However, low-resource languages, those lacking extensive prominence in datasets for various NLP tasks, or where existing datasets are not as substantial, such as Portuguese, already obtain several benefits from LLMs, but not to the same extent. LLMs trained on multilingual datasets normally struggle to respond to prompts in Portuguese satisfactorily, presenting, for example, code switching in their responses. This work proposes a fine-tuned LLaMA 2-based model for Portuguese prompts named Bode in two versions: 7B and 13B. We evaluate the performance of this model in classification tasks using the zero-shot approach with in-context learning, and compare it with other LLMs. Our main contribution is to bring an LLM with satisfactory results in the Portuguese language, as well as to provide a model that is free for research or commercial purposes.
연구 동기 및 목표
- 고품질 포르투갈어 NLP 모델의 격차를 해소하기 위해 포르투갈어 지시 준수 작업에 대해 공개적으로 사용 가능한 LLM을 개발한다.
- 포르투갈어 데이터 세트를 이용해 LLaMA 2 아키텍처를 포르투갈어로 미세 조정한다.
- 제로샷 및 인-context 학습 설정에서 포르투갈어 분류 작업에 대해 Bode를 평가한다.
- 포르투갈어 프롬프트에서의 상대적 강점을 평가하기 위해 Bode를 다른 개방형 LLM과 비교한다.
제안 방법
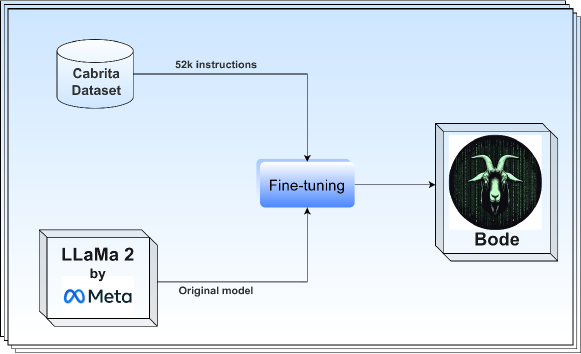
- 포르투갈어 지시 준수 데이터에서 파생된 데이터 세트를 사용해 LLaMA 2를 미세 조정한다.
- 미세 조정 중 알파=32 및 dropout=0.05로 Low-Rank Adaptation (LoRA)을 적용한다.
- 추가 작업별 학습 없이 평가를 위해 zero-shot 및 in-context 학습을 채택한다.
- 감정 및 뉴스 분류 작업에 대해 모델 응답을 안내하기 위해 프롬프트 엔지니어링을 사용한다.
- 세 가지 포르투갈어 데이터 세트(TweetSentBr multiclass, TweetSentBr binary, AGNews multiclass, FakeRecogna binary)에서 평가한다.
- Cabrita/openCabrita, Falcon-7B, LLaMA-2 7B/13B, 및 Mistral-7B 기본 모델과 비교한다.
실험 결과
연구 질문
- RQ1LLaMA 2를 기반으로 한 포르투갈어 특화 미세 조정 LLM이 제로샷 및 인-context 학습 하에서 감정 분석, 뉴스 분류 및 가짜 뉴스 탐지에서 경쟁력 있는 정확도를 달성할 수 있는가?
- RQ213B 매개변수의 Bode가 7B 동료 및 다른 개방 포르투갈어 LLM에 비해 이러한 작업에서 더 높은 성능을 보이는가?
- RQ3프롬프트 엔지니어링 및 LoRA 기반 미세 조정이 포르투갈어 지시 준수 성능에 어떤 영향을 미치는가?
주요 결과
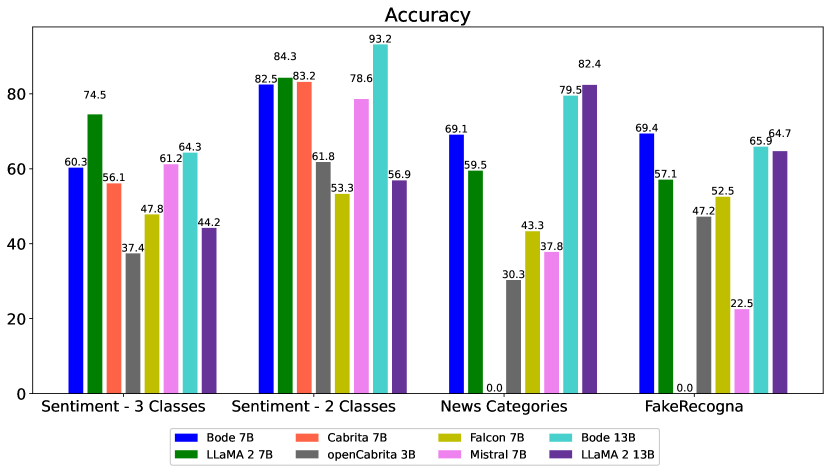
- Bode 13B는 감정 분석 작업에서 90%를 넘는 정확도를 달성하며 LLaMA 2 13B 기본 모델이 56.9%를 기록한 것을 능가했다.
- 다중 클래스 뉴스 분류에서 Bode 7B는 7B 모델들 중 가장 높은 성능을 달성했고, 13B 모델들 중에서는 LLaMA 2 13B에 비가까운 차이로 우위를 보였다.
- 가짜 뉴스 탐지에서 두 가지 Bode 모델은 기본 카운터파트를 능가했고, 작업 전반에 걸쳐 강한 일관성을 보여주었다.
- 전반적으로 Bode 7B 및 13B는 개방형 포르투갈어 LLM의 기준선에 대체로 일치하거나 능가했으며, 작업에 따라 편차가 있었다.
- 저자들은 LLaMA 2 7B/13B에 비해 Bode의 성능 하락의 가능한 원인으로 재앙적 망각(catastrophic forgetting)을 지적한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.