[논문 리뷰] Is K-fold cross validation the best model selection method for Machine Learning?
논문은 표준 K-fold 교차 검증이 거짓 양성을 과대평가할 수 있다고 주장하고 실제 오차를 상한하고 ML의 통계적 추론을 개선하기 위해 K-fold Cross Upper Bounding Validation (CUBV)을 제안한다. 특히 작거나 이질적인 신경영상 데이터에서의 활용을 강조한다.
As a technique that can compactly represent complex patterns, machine learning has significant potential for predictive inference. K-fold cross-validation (CV) is the most common approach to ascertaining the likelihood that a machine learning outcome is generated by chance, and it frequently outperforms conventional hypothesis testing. This improvement uses measures directly obtained from machine learning classifications, such as accuracy, that do not have a parametric description. To approach a frequentist analysis within machine learning pipelines, a permutation test or simple statistics from data partitions (i.e., folds) can be added to estimate confidence intervals. Unfortunately, neither parametric nor non-parametric tests solve the inherent problems of partitioning small sample-size datasets and learning from heterogeneous data sources. The fact that machine learning strongly depends on the learning parameters and the distribution of data across folds recapitulates familiar difficulties around excess false positives and replication. A novel statistical test based on K-fold CV and the Upper Bound of the actual risk (K-fold CUBV) is proposed, where uncertain predictions of machine learning with CV are bounded by the worst case through the evaluation of concentration inequalities. Probably Approximately Correct-Bayesian upper bounds for linear classifiers in combination with K-fold CV are derived and used to estimate the actual risk. The performance with simulated and neuroimaging datasets suggests that K-fold CUBV is a robust criterion for detecting effects and validating accuracy values obtained from machine learning and classical CV schemes, while avoiding excess false positives.
연구 동기 및 목표
- 표준 K-fold CV의 가설 검정에 대한 한계를 작은 데이터셋이나 이질적인 데이터에서 동기로 제시한다.
- CV 기반 ML 분석에서 실제 오차를 상한하는 통계적으로 근거 있는 방법을 제안한다.
- 제안된 방법을 합성 데이터와 ADNI/MCI의 실제 신경영상 MRI 데이터셋에서 평가한다.
- 데이터 이질성과 샘플 크기가 ML 파이프라인의 예측 추론 및 오차 상한에 미치는 영향을 평가한다.
제안 방법
- K-fold Cross Upper Bounding Validation (CUBV)를 도입하여 경험적 CV 오차를 주어진 실제 오차를 상한하기 위해 농도 부등식을 사용하는 방법을 제시한다.
- K-fold CV를 PAC-Bayesian에서 영감을 얻은 상한과 결합하여 오분류 위험에 대한 신뢰 구간을 도출한다.
- CV 기반 상한이 1−η의 확률로 특정 임계치를 만족하면 귀무가설을 기각하는 통계적 테스트(K-fold CUBV test)를 형식화한다.
- 이질성을 시뮬레이션하기 위해 단일 및 다중 클러스터 Gaussian PDF를 가진 합성 데이터를 사용하여 유형 I 오류 제어를 평가한다.
- ADNI에서 추출된 특징의 실제 MRI 다중 클래스 데이터셋에 접근법을 적용하여 연구 결과를 검증한다.
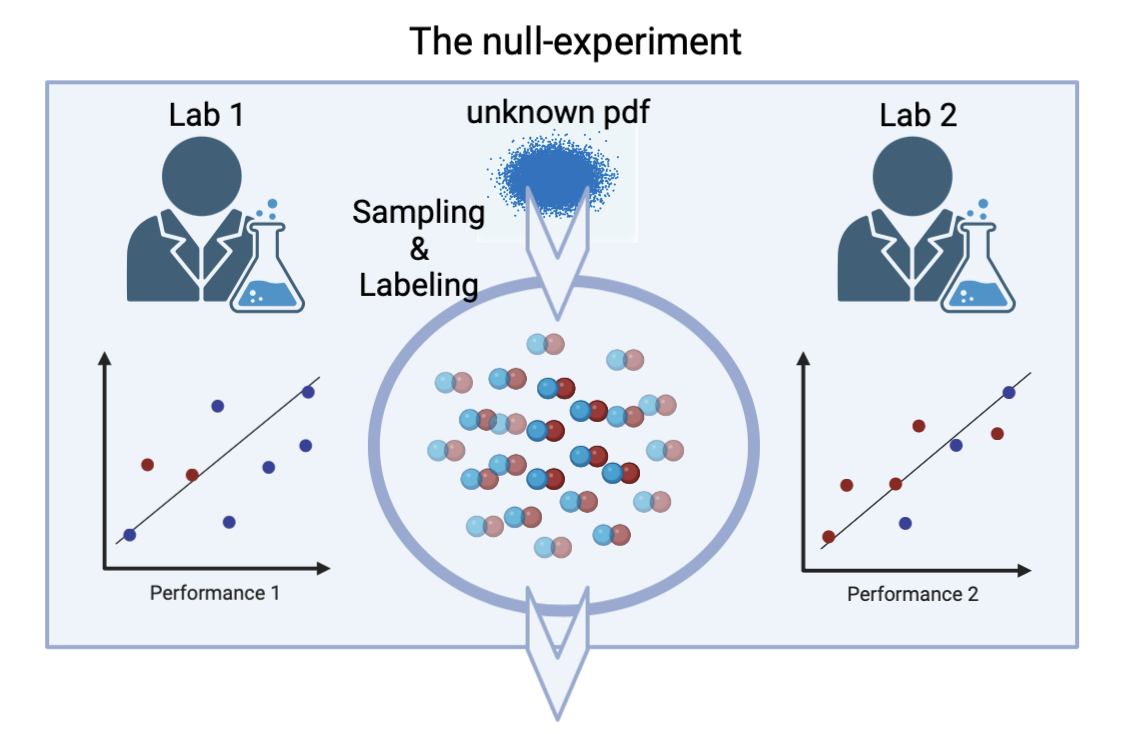
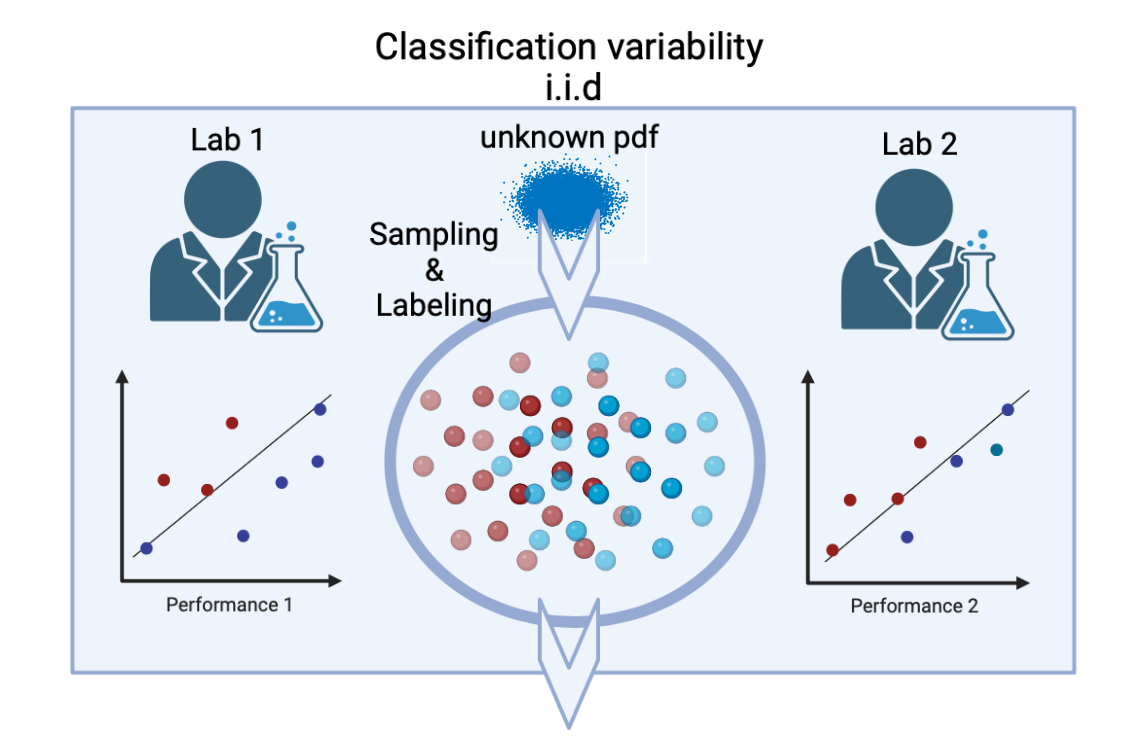
실험 결과
연구 질문
- RQ1작은 샘플이나 이질적 샘플에서의 K-fold CV 기반 ML이 순열 테스트 하에서 거짓 양성을 과대하게 만들 수 있는가?
- RQ2K-fold CUBV 접근법이 다양한 실험 설계에서 실제 오차에 대한 유효한 상한을 제공하는가?
- RQ3데이터 이질성과 다중 클러스터 구조가 신경영상 분류 작업의 예측 추론에 어떤 영향을 미치는가?
- RQ4CV와 PAC-Bayesian 상한의 결합이 표준 CV에 비해 제1종 오류 제어를 개선하는가?
- RQ5제안된 방법이 실제 MRI/MCI 예측 작업에 실용적이고 강력한가?
주요 결과
- K-fold CV만으로도 작은 샘플에서 특정 무작위 실험 설정에서 명목 수준을 넘는 거짓 양성을 초래할 수 있다.
- K-fold CUBV는 시뮬레이션된 다중 샘플 및 단일 샘플 실험에서 일관되게 제1종 오류를 제어한다.
- CUBV 접근법은 일부 설정에서 표준 CV보다 검력(l power)이 낮을 수 있지만, 이질성 하에서 robust한 오차 경계 및 추론 개선을 제공한다.
- 시뮬레이션에서 데이터 복잡도 증가와 작은 표본 크기가 CV 성능의 변동성을 증가시키는 반면, CUBV는 이를 정량화하고 상한을 제시하는 데 도움을 준다.
- MRI 기반의 신경영상 데이터셋에의 적용은 과대 거짓 양성 문제를 완화하면서 ML 정확도를 검증하는 방법의 실현 가능성을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.