[논문 리뷰] Jasper: An End-to-End Convolutional Neural Acoustic Model
요약: Jasper는 1D 컨볼루션, 배치 노름, ReLU, 드롭아웃 및 잔차 연결을 사용하는 엔드투엔드 합성 음향 모델로, Transformer-XL 언어 모델과 함께 테스트-클린에서 2.95% WER로 LibriSpeech에서 최첨단 결과를 달성합니다.
In this paper, we report state-of-the-art results on LibriSpeech among end-to-end speech recognition models without any external training data. Our model, Jasper, uses only 1D convolutions, batch normalization, ReLU, dropout, and residual connections. To improve training, we further introduce a new layer-wise optimizer called NovoGrad. Through experiments, we demonstrate that the proposed deep architecture performs as well or better than more complex choices. Our deepest Jasper variant uses 54 convolutional layers. With this architecture, we achieve 2.95% WER using a beam-search decoder with an external neural language model and 3.86% WER with a greedy decoder on LibriSpeech test-clean. We also report competitive results on the Wall Street Journal and the Hub5'00 conversational evaluation datasets.
연구 동기 및 목표
- LibriSpeech 및 다른 벤치마크에서 엔드투엔드가 아닌 접근방식과 동등하거나 우수한 성능을 보이는 계산적으로 효율적인 엔드투엔드 CNN 음향 모델을 시연한다.
- 매우 깊은 1D-CNN 기반 ASR 모델을 가능하게 하는 아키텍처 선택(활성화, 정규화, 잔차) 및 옵티마이저 전략을 조사한다.
- 외부 언어 모델(신경망 및 N-그램)이 엔드투엔드 Jasper 성능에 미치는 영향을 보여준다.
- Very deep 네트워크를 가능하게 하기 위한 잔차 연결 변형( Dense Residual 포함)을 제안하고 평가한다.
- Jasper를 재현 가능한 훈련 설정과 제거 실험으로 엔드투엔드 CNN 기반 ASR의 강력한 기준(baseline)으로 확립한다.
제안 방법
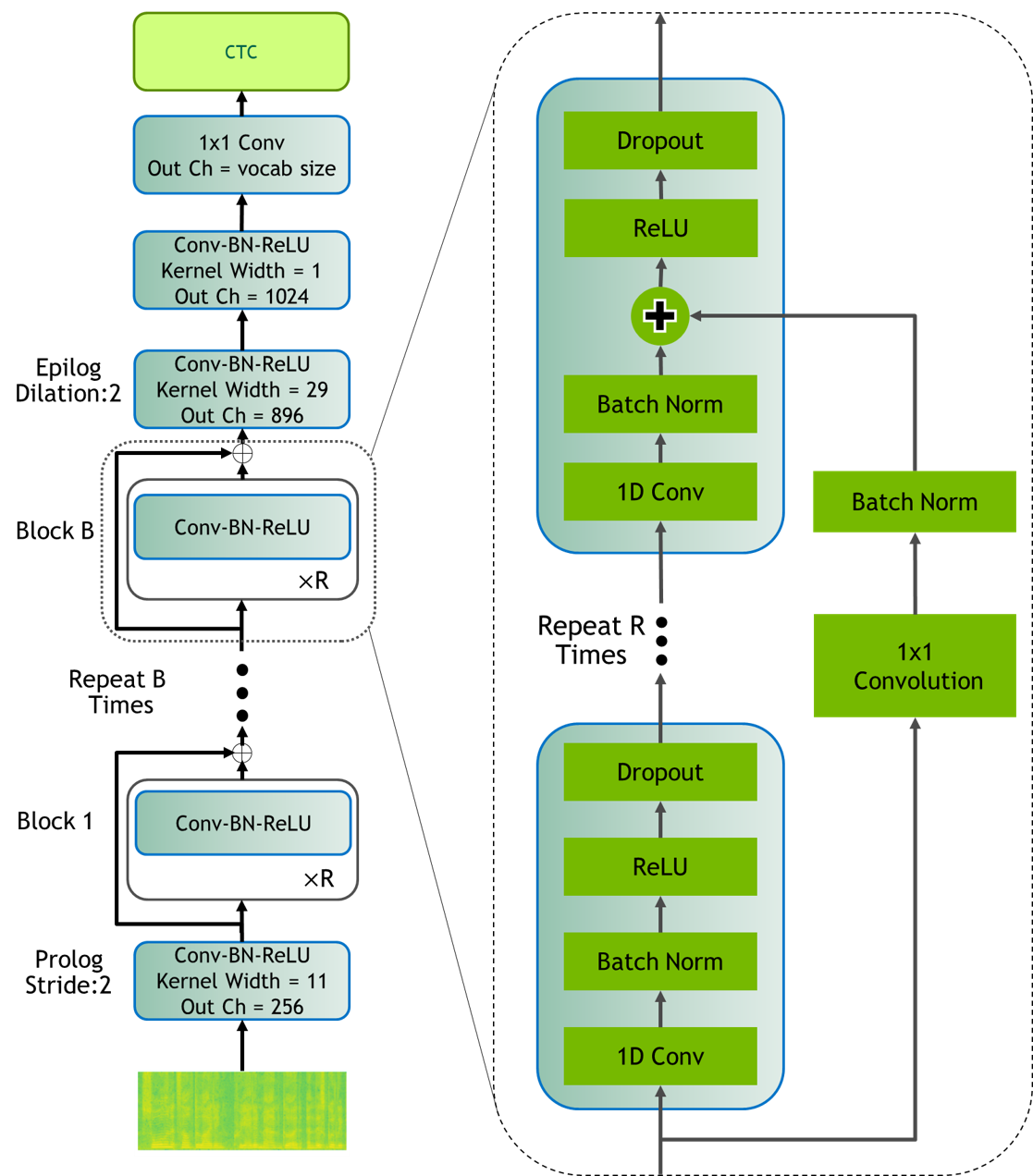
- 잔차 연결이 있는 1D 컨볼루션 블록 스택을 사용한다(Jasper B x R 모델).
- 정규화(Batch Norm, Layer Norm, Weight Norm)와 활성화(ReLU, cReLU, lReLU, GAU/GLU)를 실험하여 효과적인 조합을 식별한다.
- NovoGrad 옵티마이저(레이어별 2차 모멘트 추정)를 도입하여 학습 안정성을 개선하고 메모리를 감소시킨다.
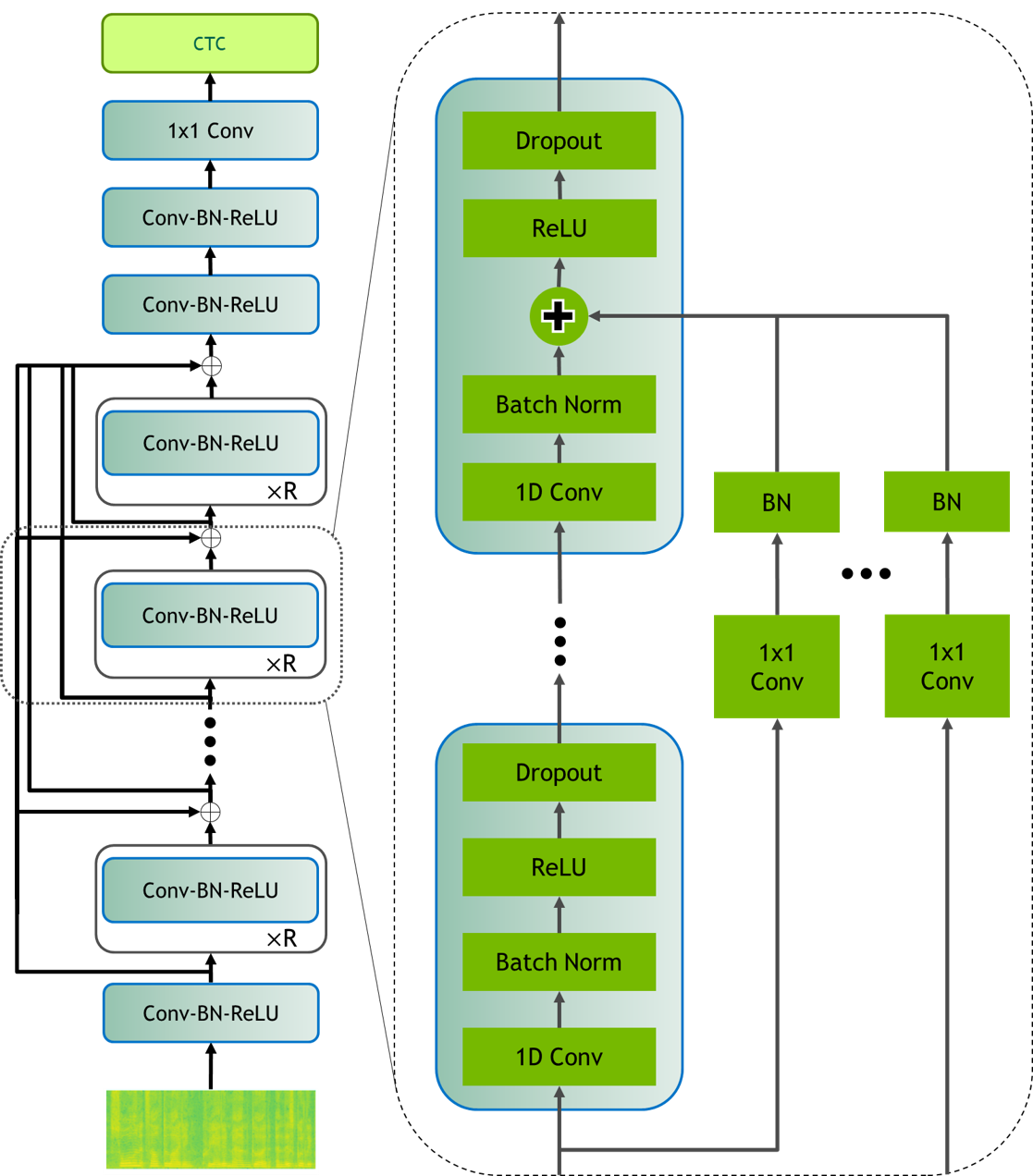
- Dense Residual을 포함한 잔차 토폴로지의 비교와 DenseNet/DenseRNet 내부-블록 연결 비교를 수행한다; 더 깊은 모델에 Dense Residual를 선택한다.
- 음향+단어 수준 N-그램 LM을 사용한 빔 서치(폭 2048)로 디코딩하고 Transformer-XL 신경 LM 리스코어링을 수행한다; 그 외 greedy 디코딩 결과도 보고한다.
- Jasper 변형을 54개의 컨볼루션 층(333M 파라미터)까지 SGD 모멘텀 또는 NovoGrad로 학습한다; LM 실험에서 Spec 확대와 유사한 마스킹을 적용한다.
실험 결과
연구 질문
- RQ1순수한 1D-컨볼루션 엔드투엔드 음향 모델이 외부 학습 데이터 없이 LibriSpeech에서 최첨단 결과를 달성할 수 있는가?
- RQ2매우 깊은 1D CNN ASR 모델을 가능하게 하는 정규화, 활성화, 잔차 연결 구성은 무엇인가?
- RQ3NovoGrad가 SGD에 비해 학습 안정성과 WER에 미치는 영향은 무엇인가?
- RQ4 LibriSpeech에서 外部 언어 모델(N-그램 및 Transformer-XL)을 통합하는 것이 엔드투엔드 Jasper 성능에 어떤 영향을 미치는가?
- RQ5Dense Residual/DenseNet 스타일의 연결이 딥 Jasper 모델에 대해 고전적 잔차와 비교해 이점이 있는가?
주요 결과
- Jasper는 LibriSpeech의 test-clean에서 엔드투엔드 모델 중 최첨단 결과를 달성하고 test-other에서도 경쟁력 있는 결과를 보이며(Transformer-XL LM을 사용한 test-clean에서 2.95% WER).
- 대규모 Jasper 모델에서 배치 정규화와 ReLU가 다른 정규화/활성화 조합보다 우수하며, 수렴을 위해 잔차 연결이 필요하다.
- NovoGrad는 10x5 Jasper DR 모델에서 LibriSpeech dev-clean WER를 4.00%에서 3.64%로 개선하며 상대적 9% 향상을 보인다.
- Dense Residual 연결은 다른 Dense/연결 기반 방법과 유사한 성능을 보이면서도 증가 요인을 피하여 매우 깊은 Jasper 네트워크의 학습을 용이하게 한다.
- 빔 서치와 리스코어링에서 외부 LM(N-그램 및 Transformer-XL)을 사용하는 것이 LibriSpeech WER를 현저히 향상시키며, Transformer-XL은 Jasper DR 10x5의 test-clean에서 2.95%를 달성한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.