[논문 리뷰] Just Another Day on Twitter: A Complete 24 Hours of Twitter Data
이 논문은 모든 포괄적 쿼리로 수집한 최초의 완전한 24시간 Twitter 데이터세트(2022년 9월 21일 기준 375M 트윗)를 제시하며 활동, 봇 확산, 언어, 주제, 사용자 특성을 연구하고, 플랫폼 소유권 변경 이전의 기준선을 설정한다.
At the end of October 2022, Elon Musk concluded his acquisition of Twitter. In the weeks and months before that, several questions were publicly discussed that were not only of interest to the platform's future buyers, but also of high relevance to the Computational Social Science research community. For example, how many active users does the platform have? What percentage of accounts on the site are bots? And, what are the dominating topics and sub-topical spheres on the platform? In a globally coordinated effort of 80 scholars to shed light on these questions, and to offer a dataset that will equip other researchers to do the same, we have collected all 375 million tweets published within a 24-hour time period starting on September 21, 2022. To the best of our knowledge, this is the first complete 24-hour Twitter dataset that is available for the research community. With it, the present work aims to accomplish two goals. First, we seek to answer the aforementioned questions and provide descriptive metrics about Twitter that can serve as references for other researchers. Second, we create a baseline dataset for future research that can be used to study the potential impact of the platform's ownership change.
연구 동기 및 목표
- 이전 연구의 표본 편향 및 데이터 품질 문제를 다루기 위한 완전한 24시간 Twitter 데이터세트를 제공한다.
- 시간 편향을 최소화하고 대표성을 극대화하기 위한 데이터 수집 파이프라인과 방법을 설명한다.
- 연구자들의 참고 자료 및 Twitter 소유권 변경 이전의 기준선으로 작용하는 기술적 지표를 제공한다.
- 플랫폼 역학, 봇 확산, 언어 분포 및 콘텐츠 주제에 대한 향후 연구를 가능하게 한다.
제안 방법
- 시간 분할된 1초 작업 설계를 사용하여 시간 편향을 줄이기 위해 Academic API로 24시간의 Twitter 데이터를 수집(Sept 20 15:00 UTC – Sept 21 14:59 UTC).
- 창(window) 내 모든 트윗을 포착하기 위한 음성언어를 포함하는 부정적 언어 포함 쿼리 전략을 사용하고 Twitter의 언어 태깅(lang: 코드)과 긴 OR-언어 구성 활용.
- 하루를 86,400개의 작업으로 분할하고 각 작업은 한 초의 활동을 나타내며, 샘플 안정화를 위해 생성 시간으로부터 10분 후에 시작한다.
- 백로그를 피하고 높은 시간적 커버리지를 보장하기 위해 다중 병렬 API 토큰(80개 프로세스)을 구현한다.
- 공개성, 접근성, 재현성을 지원하는 FAIR 원칙에 따라 트윗 ID를 통해 데이터세트를 제공한다(CC BY 4.0).
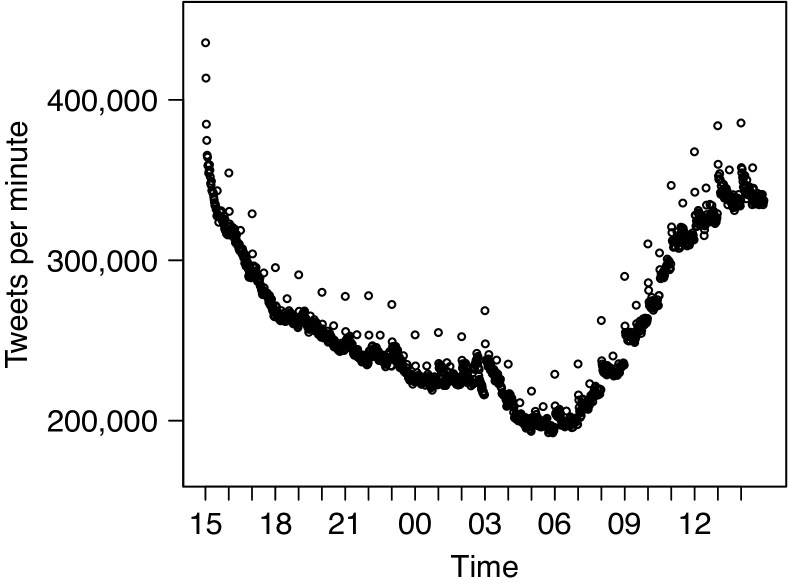
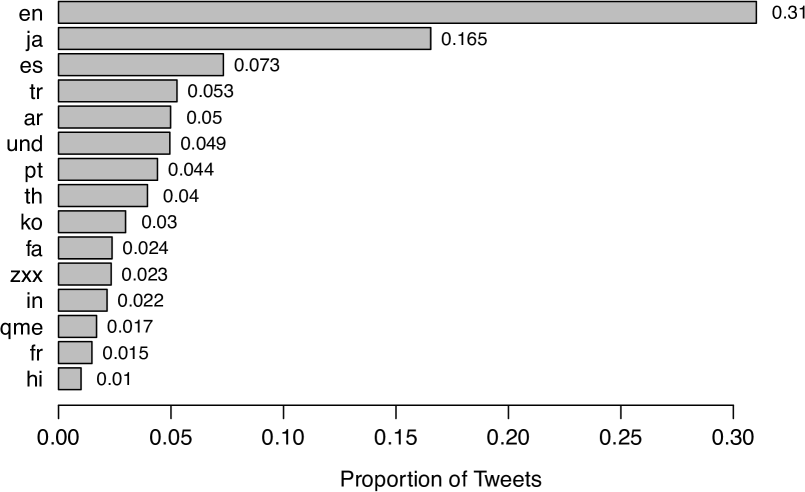
실험 결과
연구 질문
- RQ1대표적인 날의 완전한 24시간 동안 Twitter 활동의 규모와 구성은 어떠한가?
- RQ2하루 전체에 걸친 활성 계정, 언어, 콘텐츠 유형(텍스트, 미디어, 지오태그)의 분포는 어떻게 되는가?
- RQ3수집된 날의 봇 유사 행동의 유병률과 특성은 어떤가?
- RQ4해시태그와 콘텐츠 범주를 통해 반영된 24시간 담론에서 어떤 주제와 커뮤니티가 지배적인가?
- RQ5이 기준선 지표가 소유권 변경에 비추어 향후 연구에 어떻게 정보를 제공하는가?
주요 결과
- 데이터세트는 40,199,195 계정의 374,937,971 트윗을 포함하며, 약 1%의 사용자가 약 3.5백만 트윗을 생성하고 트윗의 50%가 175,000 계정에서 나옵니다.
- 평균적으로 초당 약 4,340건의 트윗을 수집했고 범위는 2,989–8,955; 각 시간의 첫 분에 트윗 활동이 15.5% 더 높은 것으로 나타났습니다.
- 트윗의 79.2%가 리트윗/인용/응답이고 20.8%가 원본 트윗이며, 하루 동안의 총 리트윗은 4010억 건에 달합니다.
- 언어: 15개 언어가 트윗의 92.5%를 차지하며; 글로벌 지오태그 비율은 0.5%이고 상위 지오태그 국가로는 미국, 브라질, 일본, 사우디아라비아, 인도가 있다.
- 미디어: 112,779,266개의 미디어 첨부(76.9% 사진, 20.7% 비디오, 2.4% GIF); 0.5% 트윗에 지오태그.
- 봇 확률(BotometerLite): 활성 계정의 약 20%가 0.5를 초과하는 봇 유사 점수를 가지며, 봇 유사 행동은 더 오래된 계정과 더 많은 트윗을 가진 계정에서 더 높은 경향을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.